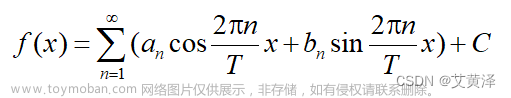文章目录
-
- 概要
- 整体结果
- 模块设计
- 细节实现
- 小结
概要
对于基4fft算法,计算原理无需多说,可以看看知网论文,或者数字信号处理的书籍,本次基4fft按照AXI4-stream总线协议方式,当握手时开始产生传送数据流
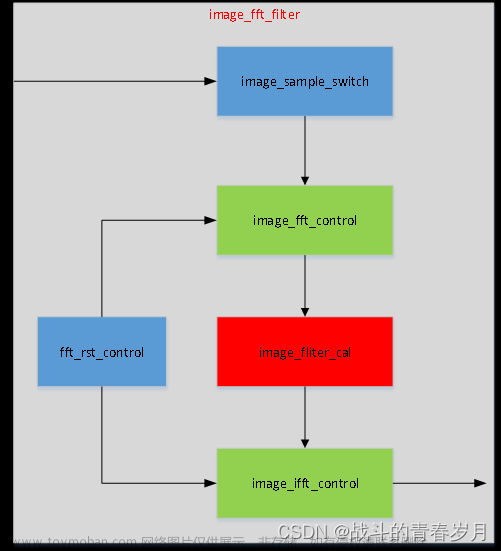
整体结构
本次采用的方法是使用状态机实现:(1)S0状态:初始状态.(2)S1状态:开始传送数据,(S2):开始将RAM1的数据读出,进行蝶形运算到RAM2中.(S3)将RAM2数据读出进行蝶形运算到RAM2中.(S4):等待握手从RAM2读出结果,此时RAM1可以接受新的数据,当读完并且存完时,进入状态S2,开始新一轮计算。(当开始接受数据到开始接受下一组数据的间隔大约为3600左右时钟)
模块设计
- 蝶形运算:输入三个旋转因子可四个数据进行蝶形计算,在第三个时钟出结果,采用流水线形式,用的是*作为乘法。
module butter
(
input aclk,
input rstn,
input en,
input signed [15:0] w_i_k,
input signed [15:0] w_q_k,
input signed [15:0] w_i_2k,
input signed [15:0] w_q_2k,
input signed [15:0] w_i_3k,
input signed [15:0] w_q_3k,
input [63:0] data_a,data_b,data_c,data_d,
output[63:0] q_a,q_b,q_c,q_d,
output valid
);
wire signed [31:0] w_i_k_Re,w_i_k_Im,w_i_2k_Re,w_i_2k_Im,w_i_3k_Re,w_i_3k_Im;
wire signed [31:0] interA_Re,interA_Im,interB_Re,interB_Im,interC_Re,interC_Im,interD_Re,interD_Im;
assign interA_Re = data_a[31:0];
assign interA_Im = data_a[63:32];
assign interB_Re = data_b[31:0];
assign interB_Im = data_b[63:32];
assign interC_Re = data_c[31:0];
assign interC_Im = data_c[63:32];
assign interD_Re = data_d[31:0];
assign interD_Im = data_d[63:32];
assign w_i_k_Re={{16{w_i_k[15]}},w_i_k};
assign w_i_k_Im={{16{w_q_k[15]}},w_q_k};
assign w_i_2k_Re={{16{w_i_2k[15]}},w_i_2k};
assign w_i_2k_Im={{16{w_q_2k[15]}},w_q_2k};
assign w_i_3k_Re={{16{w_i_3k[15]}},w_i_3k};
assign w_i_3k_Im={{16{w_q_3k[15]}},w_q_3k};
reg [3:0] en_r ;
always @(posedge aclk or negedge rstn) begin
if (!rstn)
begin
en_r <= 'b0 ;
end
else
begin
en_r <= {en_r[3:0], en} ;
end
end
reg signed [63:0] xa_re;
reg signed [63:0] xa_im;
reg signed [63:0] xb_wnr_real0;
reg signed [63:0] xb_wnr_real1;
reg signed [63:0] xb_wnr_imag0;
reg signed [63:0] xb_wnr_imag1;
reg signed [63:0] xc_wnr_real0;
reg signed [63:0] xc_wnr_real1;
reg signed [63:0] xc_wnr_imag0;
reg signed [63:0] xc_wnr_imag1;
reg signed [63:0] xd_wnr_real0;
reg signed [63:0] xd_wnr_real1;
reg signed [63:0] xd_wnr_imag0;
reg signed [63:0] xd_wnr_imag1;
always @(posedge aclk or negedge rstn) begin
if (!rstn) begin
xa_re <= 'b0;
xa_im <= 'b0;
xb_wnr_real0 <= 'b0;
xb_wnr_real1 <= 'b0;
xb_wnr_imag0 <= 'b0;
xb_wnr_imag1 <= 'b0;
xc_wnr_real0 <= 'b0;
xc_wnr_real1 <= 'b0;
xc_wnr_imag0 <= 'b0;
xc_wnr_imag1 <= 'b0;
xd_wnr_real0 <= 'b0;
xd_wnr_real1 <= 'b0;
xd_wnr_imag0 <= 'b0;
xd_wnr_imag1 <= 'b0;
end
else if (en) begin
xa_re <= {{18{interA_Re[31]}},interA_Re,14'd0};
xa_im <= {{18{interA_Im[31]}},interA_Im,14'd0};
xb_wnr_real0 <= interB_Re * w_i_k_Re;
xb_wnr_real1 <= interB_Im * w_i_k_Im;
xb_wnr_imag0 <= interB_Re * w_i_k_Im;
xb_wnr_imag1 <= interB_Im * w_i_k_Re;
xc_wnr_real0 <= interC_Re * w_i_2k_Re;
xc_wnr_real1 <= interC_Im * w_i_2k_Im;
xc_wnr_imag0 <= interC_Re * w_i_2k_Im;
xc_wnr_imag1 <= interC_Im * w_i_2k_Re;
xd_wnr_real0 <= interD_Re * w_i_3k_Re;
xd_wnr_real1 <= interD_Im * w_i_3k_Im;
xd_wnr_imag0 <= interD_Re * w_i_3k_Im;
xd_wnr_imag1 <= interD_Im * w_i_3k_Re;
end
else
begin
xa_re <= 'b0;
xa_im <= 'b0;
xb_wnr_real0 <= 'b0;
xb_wnr_real1 <= 'b0;
xb_wnr_imag0 <= 'b0;
xb_wnr_imag1 <= 'b0;
xc_wnr_real0 <= 'b0;
xc_wnr_real1 <= 'b0;
xc_wnr_imag0 <= 'b0;
xc_wnr_imag1 <= 'b0;
xd_wnr_real0 <= 'b0;
xd_wnr_real1 <= 'b0;
xd_wnr_imag0 <= 'b0;
xd_wnr_imag1 <= 'b0;
end
end
reg signed [63:0] xA_re1;
reg signed [63:0] xA_im1;
reg signed [63:0] xB_re1;
reg signed [63:0] xB_im1;
reg signed [63:0] xC_re1;
reg signed [63:0] xC_im1;
reg signed [63:0] xD_re1;
reg signed [63:0] xD_im1;
always @(posedge aclk or negedge rstn) begin
if (!rstn) begin
xA_re1 <= 'b0;
xA_im1 <= 'b0;
xB_re1 <= 'b0;
xB_im1 <= 'b0;
xC_re1 <= 'b0;
xC_im1 <= 'b0;
xD_re1 <= 'b0;
xD_im1 <= 'b0;
end
else if (en_r[0]) begin
xA_re1 <=(xa_re + xb_wnr_real0 - xb_wnr_real1);
xA_im1 <=(xa_im + xb_wnr_imag0 + xb_wnr_imag1);
xB_re1 <= (xa_re - xb_wnr_real0 + xb_wnr_real1);
xB_im1 <= (xa_im - xb_wnr_imag0 - xb_wnr_imag1);
xC_re1 <= (xc_wnr_real0 - xc_wnr_real1 + xd_wnr_real0 - xd_wnr_real1);
xC_im1 <= (xc_wnr_imag0 + xc_wnr_imag1 + xd_wnr_imag0 + xd_wnr_imag1);
xD_re1 <= (xc_wnr_imag0 + xc_wnr_imag1 - xd_wnr_imag0 - xd_wnr_imag1);
xD_im1 <= (xd_wnr_real0 - xd_wnr_real1 - xc_wnr_real0 + xc_wnr_real1);
end
else
begin
xA_re1 <= 'b0;
xA_im1 <= 'b0;
xB_re1 <= 'b0;
xB_im1 <= 'b0;
xC_re1 <= 'b0;
xC_im1 <= 'b0;
xD_re1 <= 'b0;
xD_im1 <= 'b0;
end
end
reg signed [64:0] xA_re;
reg signed [64:0] xA_im;
reg signed [64:0] xB_re;
reg signed [64:0] xB_im;
reg signed [64:0] xC_re;
reg signed [64:0] xC_im;
reg signed [64:0] xD_re;
reg signed [64:0] xD_im;
always @(posedge aclk or negedge rstn) begin
if (!rstn) begin
xA_re <= 'b0;
xA_im <= 'b0;
xB_re <= 'b0;
xB_im <= 'b0;
xC_re <= 'b0;
xC_im <= 'b0;
xD_re <= 'b0;
xD_im <= 'b0;
end
else if (en_r[1]) begin
xA_re <=(xA_re1 + xC_re1)>>>14;
xA_im <=(xA_im1 + xC_im1)>>>14;
xB_re <=(xB_re1 + xD_re1)>>>14;
xB_im <=(xB_im1 + xD_im1)>>>14;
xC_re <=(xA_re1 - xC_re1)>>>14;
xC_im <=(xA_im1 - xC_im1)>>>14;
xD_re <=(xB_re1 - xD_re1)>>>14;
xD_im <=(xB_im1 - xD_im1)>>>14;
end
else
begin
xA_re <= 'b0;
xA_im <= 'b0;
xB_re <= 'b0;
xB_im <= 'b0;
xC_re <= 'b0;
xC_im <= 'b0;
xD_re <= 'b0;
xD_im <= 'b0;
end
end
assign valid = en_r[2] ;
assign q_a = {xA_im[63],xA_im[30:0],xA_re[63],xA_re[30:0]};
assign q_b = {xB_im[63],xB_im[30:0],xB_re[63],xB_re[30:0]};
assign q_c = {xC_im[63],xC_im[30:0],xC_re[63],xC_re[30:0]};
assign q_d = {xD_im[63],xD_im[30:0],xD_re[63],xD_re[30:0]};
endmodule
- 地址产生模块
第一个模块是存储数据的地址产生模块,需要进行码位倒序
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/06/06 17:03:00
// Design Name:
// Module Name: addr_rever
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module addr_rever(
input aclk,rstn,en,
output done,
output wire [9:0] re_addr
);
reg [9:0] addr;
always @(posedge aclk or negedge rstn)
begin
if (rstn == 1'b0)
begin
addr <= 10'd0;
end
else if(addr == 10'd1023)
begin
addr <= 10'd0;
end
else if(en)
begin
addr <= addr+10'd1;
end
else
begin
addr <= addr;
end
end
assign done = (addr==10'd1023)? 1:0;
assign re_addr = {addr[0],addr[1],addr[2],addr[3],addr[4],addr[5],addr[6],addr[7],addr[8],addr[9]};
endmodule第二个模块进行蝶形运算读取RAM的地址。按照每一级进行产生(stage),在出数据地址时也会产生对于的旋转因子地址。
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/06/05 21:07:42
// Design Name:
// Module Name: addr_gen
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module addr_gen(
input aclk ,
input rstn ,
input en ,
input [3:0] stage ,
output valid ,
output done ,
output wire [9:0] out1 ,
output wire [9:0] out2 ,
output wire [9:0] w_1k ,
output wire [9:0] w_2k
);
reg [10:0] cnt ;
reg [10:0] count ;
wire [10:0] groups ;
wire [10:0] p ;
wire [10:0] count_buf ;
wire [10:0] p1 ;
wire [10:0] p2 ;
wire [10:0] p3 ;
reg cls ;
reg clk_2 ;
reg flag ;
reg [9:0] counter ; //记录
wire par2ser_en ;
assign count_buf = en ? 1 << (2 *(stage - 1)) : 0;
assign groups = en ? 10'd1 << (10 - 2*stage) : 0;
assign p = en ? count_buf << 2 :0 ;
assign p1 = 10'd1 << (2*stage - 2);
assign p2 = 10'd2 << (2*stage - 2);
assign p3 = 10'd3 << (2*stage - 2);
// 1/2分频
always @(posedge aclk or negedge rstn)
if(rstn == 1'd0)
clk_2 <= 0;
else if(en)
clk_2 <= clk_2 + 1'b1;
else
clk_2 <= 0;
always @(posedge aclk or negedge rstn) //256
if(rstn == 1'd0)
flag <= 0;
else if(en)
begin
if(clk_2 == 0)
flag <= 1'b1;
else
flag <= 0;
end
else
flag <= 0;
always @(posedge aclk or negedge rstn) //256
if(rstn == 1'd0)
counter <= 0;
else if(counter == 10'd514)
counter <= 0;
else if(en)
counter <= counter + 1'b1;
else
counter <= 0;
// 地址产生
//always @(posedge aclk or negedge rstn) //256
// if(rstn == 1'd0)
// cnt <= 0;
// else if((cnt == groups-1'b1) & (clk_2 ==1'b1) & flag)
// cnt <= 0;
// else if(en)
// begin
// if((count == count_buf-1'b1) & flag)
// cnt <= cnt + 1'b1;
// else
// cnt <= cnt;
// end
// else
// cnt <= 0;
always @(posedge aclk or negedge rstn) //1
if(rstn == 1'd0)
count <= 0;
else if((count == count_buf-1'b1) & flag)
count <= 0;
else if(en)
if(flag)
count <= count + 1'b1;
else
count <= count;
else
count <= 0;
//数据地址产生
reg [9:0] addr ;
reg [9:0] addr_1 ;
reg [9:0] addr_2 ;
reg [9:0] addr_3 ;
reg [9:0] addr_4 ;
wire [9:0] addr_A ;
wire [9:0] addr_B ;
wire [9:0] addr_C ;
wire [9:0] addr_D ;
wire [9:0] out_1 ;
wire [9:0] out_2 ;
//旋转因子地址产生
reg [9:0] w_addr ;
reg [9:0] addr_1k ;
reg [9:0] addr_2k ;
reg [9:0] addr_3k ;
wire [9:0] addr_w_1k ;
wire [9:0] addr_w_2k ;
wire [9:0] addr_w_3k ;
wire [9:0] w1 ;
wire [9:0] w2 ;
always @(posedge aclk or negedge rstn)
if(rstn == 1'd0)
addr <= 0;
else if(en)
begin
if((count == count_buf-1'b1) & (addr == 11'd1024) & flag)
addr <= 0;
else if((count == count_buf-1'b1) & flag)
addr <= addr + p;
end
else
addr <= 0;
always @(posedge aclk or negedge rstn)
if(rstn == 1'd0)
begin
addr_1 <= 0;
addr_2 <= 0;
addr_3 <= 0;
addr_4 <= 0;
end
else if(en)
if(flag)
begin
addr_1 <= addr + count;
addr_2 <= addr + count + p1;
addr_3 <= addr + count + p2;
addr_4 <= addr + count + p3;
end
else
begin
addr_1 <= addr_1;
addr_2 <= addr_2;
addr_3 <= addr_3;
addr_4 <= addr_4;
end
else
begin
addr_1 <= 0;
addr_2 <= 0;
addr_3 <= 0;
addr_4 <= 0;
end
assign addr_A = en ? addr_1 : 0;
assign addr_B = en ? addr_2 : 0;
assign addr_C = en ? addr_3 : 0;
assign addr_D = en ? addr_4 : 0;
par2ser inst1(
.data_a(addr_A) ,
.data_b(addr_B) ,
.data_c(addr_C) ,
.data_d(addr_D) ,
.en(par2ser_en) ,
.aclk(aclk) ,
.rstn(rstn) ,
.out_1(out_1) ,
.out_2(out_2)
);
assign out1 = en ? out_1 : 0;
assign out2 = en ? out_2 : 0;
always @(posedge aclk or negedge rstn) //1
if(rstn == 1'd0)
w_addr <= 0;
else if(en)
begin
if(stage == 1)
w_addr <= 0;
else if((count == count_buf - 1'b1) & flag)
w_addr <= 0;
else if(flag)
w_addr <= w_addr + groups;
else
w_addr <= w_addr;
end
else
w_addr <= 0;
//旋转因子地址产生
always @(posedge aclk or negedge rstn) //1
if(rstn == 1'd0)
begin
addr_1k <= 0;
addr_2k <= 0;
addr_3k <= 0;
end
else if(en)
if(flag)
begin
addr_1k <= w_addr << 1'b1;
addr_2k <= w_addr;
addr_3k <= w_addr * 3'd3;
end
else
begin
addr_1k <= addr_1k;
addr_2k <= addr_2k;
addr_3k <= addr_3k;
end
else
begin
addr_1k <= 0;
addr_2k <= 0;
addr_3k <= 0;
end
assign addr_w_1k = addr_1k;
assign addr_w_2k = addr_2k;
assign addr_w_3k = addr_3k;
par2ser inst2(
.data_a(10'd0) ,
.data_b(addr_w_1k) ,
.data_c(addr_w_2k) ,
.data_d(addr_w_3k) ,
.en(par2ser_en) ,
.aclk(aclk) ,
.rstn(rstn) ,
.out_1(w1) ,
.out_2(w2)
);
assign par2ser_en = (counter > 10'd1) ? 1:0;
assign w_1k = w1;
assign w_2k = w2;
assign valid = (counter > 10'd2) ? 1 : 0;
assign done = (counter == 10'd514) ? 1 : 0;
endmodule
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/06/12 15:33:28
// Design Name:
// Module Name: par2ser
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module par2ser(
input [9:0] data_a,
input [9:0] data_b,
input [9:0] data_c,
input [9:0] data_d,
input en,
input aclk,
input rstn,
output [9:0] out_1,
output [9:0] out_2
);
reg [9:0] cach1;
reg [9:0] cach2;
reg [9:0] data_out1;
reg [9:0] data_out2;
reg cnt;
always @(posedge aclk or negedge rstn)
if(rstn == 1'b0)
begin
data_out1 <= 0;
data_out2 <= 0;
end
else if(en)
if(cnt == 1'b1)
begin
data_out1 <= cach1;
data_out2 <= cach2;
end
else if(cnt == 0)
begin
data_out1 <= data_a;
data_out2 <= data_b;
end
else
begin
data_out1 <= 0;
data_out2 <= 0;
end
always @(posedge aclk or negedge rstn)
if(rstn == 1'b0)
begin
cach1 <= 0;
cach2 <= 0;
end
else if(en)
begin
cach1 <= data_c;
cach2 <= data_d;
end
else
begin
cach1 <= 0;
cach2 <= 0;
end
always @(posedge aclk or negedge rstn)
if(rstn == 1'b0)
begin
cnt <= 0;
end
else if(en)
begin
cnt <= cnt + 1'b1;
end
else
begin
cnt <= 0;
end
assign out_1 = data_out1;
assign out_2 = data_out2;
endmodule
这里本来是可以出4个并行地址,但是我采用两个双口RAM来相互存储,一次只能读取两个数据,所以我的地址产生模块需要两个两个的出,即两个时钟RAM才会读出四个数据出来。
- ROM旋转因子表
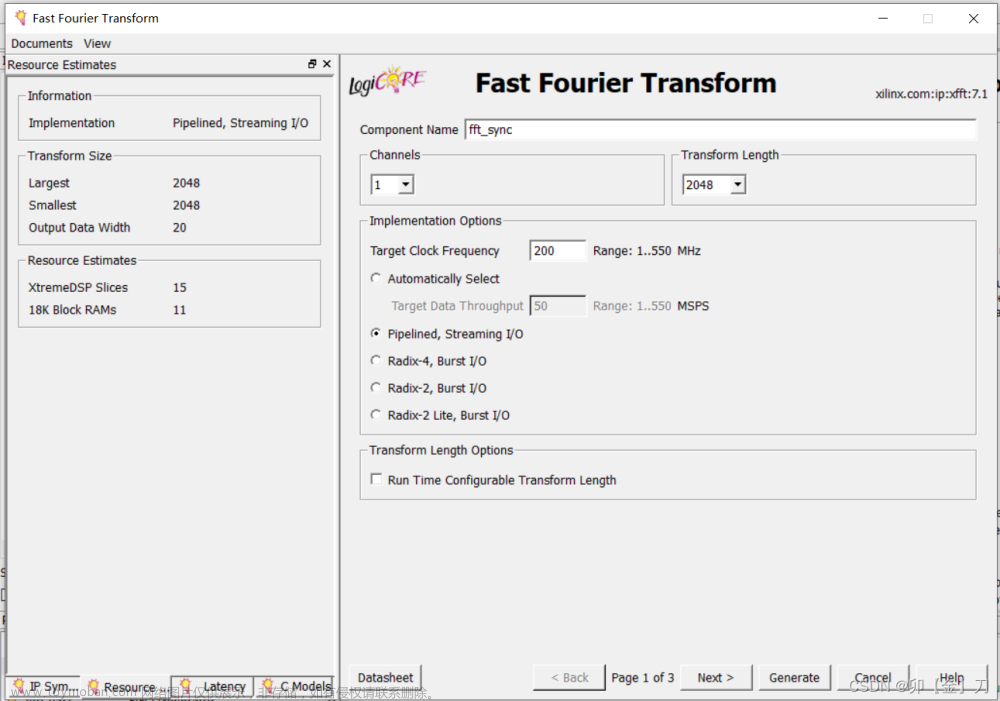
首先本次没有采用cordic算法求取旋转因子的值,可以先用Python生成使用下面这个函数,这里采用的14bit的放大.
def generate_rotation_factors():
with open("rom.v",'w') as f:
for i in range(1024):
angle = -2 * math.pi * i / 1024
cos_val = round(math.cos(angle) * (2**14))
sin_val = round(math.sin(angle) * (2**14))
if(cos_val<0):
cos_val = cos_val + 2**16
if(sin_val<0):
sin_val = sin_val + 2**16
# print("10'd{}:begin w_rom_i <= 16'h{:04X} ; w_rom_q <= 16'h{:04X}; end".format(i,cos_val, sin_val))
f.write("10'd{}:begin w_rom_i <= 16'h{:04X} ; w_rom_q <= 16'h{:04X}; end\n".format(i,cos_val, sin_val))rom.v可以写成case语句对应每个地址比如:

- 顶层主控模块:控制各个信号,和各个模块的使能信号:

输入的数据低16位是实部高16位是虚部,也就是说最高支持16位的有符号数-32767 -- +32767,输出是高32位是虚部,第32位是实部.
细节实现
- 地址产生块仿真:符合倒序 0 512 256 ...

假设输入的级数是第二级stage=2仿真结果如下:当valid信号拉高表示开始产生旋转因子的地址和ram的地址
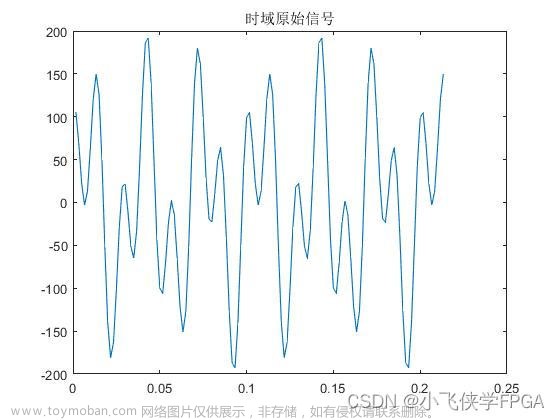
- 顶层模块仿真,仿真了4种波形,分别是方波,三角波,斜坡函数和sign函数,将仿真的数据存入txt文件中,在与python的fft包进行对比结果如下:

当master和slave握手时开始进行数据传送,并且测试了接受端和发生端在握手时的信号突然拉低的突发情况,对第一组结果放大:
可知输入的数据前523都是200,其余为0,得到的仿真结果为
- 将的得到的结果使用python包的fft进行对比:
 方波:
方波: -

局部放大:

三角波:
局部放大:

斜坡:

局部放大:

sign:

局部放大:

综合:仿真完成后进行综合: 文章来源:https://www.toymoban.com/news/detail-754159.html
文章来源:https://www.toymoban.com/news/detail-754159.html
小结
我将把我的这个完整的工程文件放入我的资源中包含各个文件的仿真文件,和python的的对比理论值的文件,如果你有什么问题,或者有改进的地方欢迎讨论文章来源地址https://www.toymoban.com/news/detail-754159.html
到了这里,关于基4FFT 1024 fpga(verilog)实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!