在当今数字化时代,互联网已经成为人们获取信息的主要渠道之一。而搜索引擎作为互联网上最重要的工具之一,扮演着连接用户与海量信息的桥梁角色。然而,我们是否曾经好奇过当我们在搜索引擎中输入关键词并点击搜索按钮后,究竟是如何能够迅速地找到相关结果呢?文章来源:https://www.toymoban.com/news/detail-754308.html
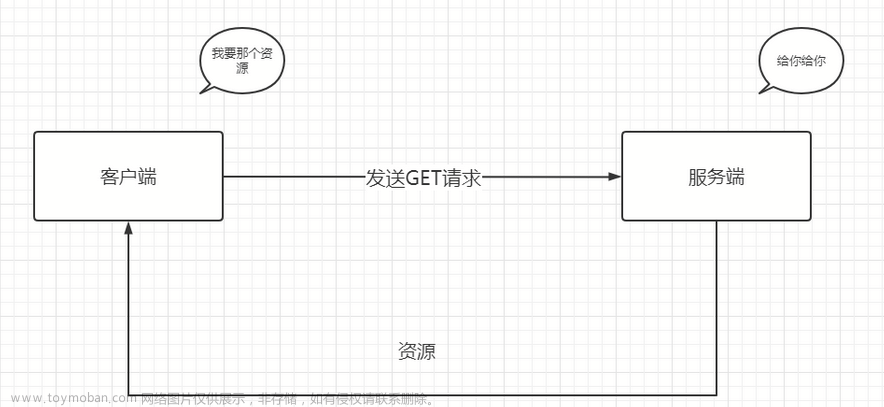
百度作为中国最大的搜索引擎之一,其背后隐藏着一个庞大而复杂的系统,其中核心组成部分就是百度爬虫。百度爬虫是一种自动化程序,通过不断地抓取、解析和索引互联网上的网页,为用户提供高质量的搜索结果。它背后的工作原理涉及到多个技术领域的交叉与融合,包括网络通信、数据挖掘、算法优化等等。文章来源地址https://www.toymoban.com/news/detail-754308.html
到了这里,关于深入了解百度爬虫工作原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!