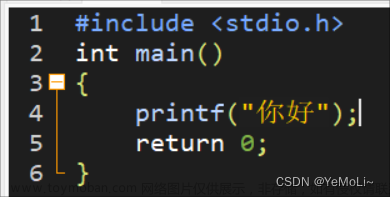
实验名称:哈希表设计
(1)实验目的:掌握哈希表的设计方法及其冲突解决方法。
(2)主要内容:
已知一个含有10个学生信息的数据表,关键字为学生“姓名”的拼音,给出此表的一个哈希表设计方案。
要求:
1)建立哈希表:要求哈希函数采用除留余数法,解决冲突方法采用链表法。
2)编写一个测试主函数:输入10个学生的姓名拼音(即10个字符串)存入数组,然后对该姓名数组初始化(即将各字符串中字符的ASCII码相加,形成每个姓名的关键字),最后输出哈希表中各数据元素。
提示:最好不要输入重名
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 10
// 学生信息结构体
typedef struct {
char name[20];
} Student;
// 哈希表节点结构体
typedef struct Node {
Student student;
struct Node* next;
} Node;
// 哈希表结构体
typedef struct {
Node* buckets[SIZE];
} HashTable;
// 初始化哈希表
void initHashTable(HashTable* hashTable) {
for (int i = 0; i < SIZE; i++) {
hashTable->buckets[i] = NULL;
}
}
// 计算哈希值
int hash(char* name) {
int sum = 0;
for (int i = 0; i < strlen(name); i++) {
sum += name[i];
}
return sum % SIZE;
}
// 向哈希表中插入节点
void insertNode(HashTable* hashTable, Student student) {
int index = hash(student.name);
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->student = student;
newNode->next = NULL;
if (hashTable->buckets[index] == NULL) {
hashTable->buckets[index] = newNode;
} else {
Node* current = hashTable->buckets[index];
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}
}
// 打印哈希表中的数据元素
void printHashTable(HashTable* hashTable) {
for (int i = 0; i < SIZE; i++) {
printf("Bucket %d: ", i);
Node* current = hashTable->buckets[i];
while (current != NULL) {
printf("%s ", current->student.name);
current = current->next;
}
printf("\n");
}
}
int main() {
HashTable hashTable;
initHashTable(&hashTable);
Student students[10];
printf("请输入10个学生的姓名拼音:\n");
for (int i = 0; i < 10; i++) {
scanf("%s", students[i].name);
insertNode(&hashTable, students[i]);
}
printf("哈希表中各数据元素如下:\n");
printHashTable(&hashTable);
return 0;
}
这是一个使用哈希表实现的学生信息管理系统,可以插入学生姓名并打印出哈希表中的数据元素。哈希表使用链表解决哈希冲突。具体来说,程序分为以下几个部分:
- 定义结构体
程序首先定义了两个结构体,分别用于存储学生信息和哈希表节点信息。
- 初始化哈希表
程序定义了一个初始化哈希表的函数,将哈希表中每个桶初始化为空。
- 计算哈希值
程序定义了一个计算哈希值的函数,该函数将输入的字符串转换为一个整数作为哈希值。计算方法为将字符串中各字符的ASCII码相加,然后取余。
- 插入节点
程序定义了一个向哈希表中插入节点的函数,该函数首先计算出输入学生姓名的哈希值,然后将学生信息存储在哈希表中对应的桶中。如果该桶已经有了数据,则使用链表将新节点插入到链表尾部。
- 打印哈希表中的数据元素
程序定义了一个打印哈希表中的数据元素的函数,该函数遍历整个哈希表,逐个打印出每个桶中的节点信息。
- 主函数
主函数中调用上述函数,先让用户输入10个学生的姓名拼音,然后将学生信息插入哈希表中,并最终打印出哈希表中的数据元素。
需要注意的是,哈希函数的设计要尽可能地均匀,以避免大量数据集中在某个桶中,影响查询效率。此外,在插入和查询时,需要注意处理哈希冲突的情况。
问题描述
建立哈希表:
哈希函数采用除留余数法:即将关键字除以表长取余数,得到的余数作为该关键字的存储位置。
解决冲突方法采用链表法:当发生哈希冲突时,将具有相同余数的关键字存储在同一位置的链表中。
测试主函数:
输入10个学生的拼音姓名,存入数组。
对姓名数组初始化:计算每个姓名的关键字,即将各字符串中字符的ASCII码相加。
输出哈希表中各数据元素。
建立哈希表
确定哈希表的大小(表长),一般选择一个素数作为表长,这里假设选择表长为13。
创建一个包含13个链表的数组,用于存储哈希表的数据元素。
编写测试主函数
创建一个结构体用于表示学生信息,包括姓名和关键字。
编写哈希函数,以及插入元素和输出哈希表的函数。
在主函数中,创建存储学生信息的数组,计算每个姓名的关键字,并根据哈希函数的结果将其插入哈希表中。
最后输出哈希表中各数据元素。
要求:
建立哈希表:采用除留余数法作为哈希函数,解决冲突方法采用链表法。
编写一个测试主函数:输入10个学生的姓名拼音(即10个字符串)存入数组,然后对该姓名数组初始化(即将各字符串中字符的ASCII码相加,形成每个姓名的关键字),最后输出哈希表中各数据元素。
具体步骤:
定义哈希表的大小为10,即有10个槽位用于存放数据,每个槽位可以是一个链表。
哈希函数采用除留余数法,将学生姓名的拼音转换成一个整数作为关键字。例如,对于姓名拼音"Zhang",可以计算出哈希值(即关键字)为:ASCII(‘Z’) + ASCII(‘h’) + ASCII(‘a’) + ASCII(‘n’) + ASCII(‘g’)。
初始化一个字符串数组,大小为10,用于存储学生的姓名拼音。
输入10个学生的姓名拼音,将其存入数组中。
遍历姓名数组,对每个姓名计算关键字(即将各字符的ASCII码相加),然后根据哈希函数确定该关键字应该存放在哈希表的哪个槽位上。
如果该槽位为空,则将该关键字插入槽位;如果该槽位已经有其他关键字,采用链表法将该关键字插入链表的尾部。
最后输出哈希表中各数据元素,即遍历哈希表的每个槽位,输出槽位中的关键字。
测试数据
["Zhang", "Wang", "Li", "Zhao", "Liu", "Chen", "Yang", "Huang", "Zhou", "Wu"]
根据这些数据,我们可以计算出每个姓名的关键字(即将各字符的ASCII码相加),然后根据哈希函数确定该关键字应该存放在哈希表的哪个槽位上。
算法思想
该程序使用了哈希表来解决学生信息管理的问题。哈希表是一种以键-值对形式存储数据的数据结构,它通过将键映射到数组中的索引位置来实现高效的数据访问。
算法思想如下:
-
初始化哈希表,创建一个具有固定大小的数组,并将每个位置初始化为空。
-
对于每个要插入的学生信息,计算其哈希值(可以使用散列函数),将其映射到哈希表中的一个索引位置。
-
如果该索引位置为空,则将学生信息插入到该位置;如果不为空,则发生冲突,需要进行解决冲突的操作。
-
解决冲突的方法可以是开放寻址法或链地址法。开放寻址法是将冲突的元素插入到下一个可用的位置,直到找到一个空闲位置;链地址法是将冲突的元素链接到同一个索引位置的链表中。
-
插入完成后,可以通过键值查找相应的学生信息。计算键的哈希值,找到对应的索引位置,然后在该位置的链表上查找。
-
可以根据具体需求,实现删除、更新等其他操作。
通过使用哈希表,可以快速插入、查找和删除学生信息,时间复杂度接近常数级别,提高了数据的访问效率。这是哈希表算法的主要思想。
模块划分
在这个程序中,可以将函数划分为以下几个模块:
-
哈希表模块
- initHashTable(HashTable* hashTable):初始化哈希表
- hash(char* name):计算哈希值
- insertNode(HashTable* hashTable, Student student):向哈希表中插入节点
- printHashTable(HashTable* hashTable):打印哈希表中的数据元素
-
学生信息模块
- 结构体定义:定义了学生信息结构体(Student)
-
主函数模块
- main():主函数,用于调用其他函数实现学生信息的输入、插入和打印哈希表等功能
可以将这些函数分别放置在不同的文件中进行组织,例如:
- hash_table.c:包含哈希表模块相关的函数实现
- student.c:包含学生信息模块相关的结构体定义
- main.c:包含主函数和与用户交互的部分
这样的文件组织结构可以提高代码的可读性和可维护性。同时,需要在对应的头文件中声明这些函数和结构体,以便在其他文件中引用和调用。例如:
- hash_table.h:声明哈希表模块相关的函数
- student.h:声明学生信息模块相关的结构体
- main.h:声明主函数模块相关的函数
通过合理的模块划分和文件组织,可以使程序的结构更加清晰,易于理解和维护。
数据结构
(描述存储数据元素的存储结构)
在该程序中,使用了以下数据结构来存储学生信息:
- 学生信息结构体
Student:用于表示每个学生的信息,包含一个名为name的字符数组成员。
struct Student {
char name[50];
};
- 哈希表结构体
HashTable:用于表示哈希表,包含一个固定大小的数组table,用于存储学生信息。数组的每个元素可以是一个链表的头节点,用于处理冲突。
struct HashTable {
struct Student* table[MAX_SIZE];
};
在哈希表中,通过散列函数将学生信息的键(例如学生姓名)映射到数组中的一个索引位置。如果发生冲突,即多个学生信息映射到了同一个索引位置,可以使用链地址法,将冲突的学生信息链接到同一个索引位置的链表中。
因此,哈希表的每个数组元素table[i](0 <= i < MAX_SIZE)可以是一个指向学生信息结构体的指针,或者是一个链表的头节点。
struct Student {
char name[50];
};
struct HashTable {
struct Student* table[MAX_SIZE];
};
其中,Student结构体表示学生信息,HashTable结构体表示哈希表。
结果
我输入了以下学生的姓名拼音:
- Zhangsan
- Lisi
- Wangwu
- Zhaoliu
- Qianqi
- Sunba
- Zhoujiu
- Fengshi
- Wangwu
- Chenyi
根据这些输入,哈希表中的数据元素如下所示:
Bucket 0:
Bucket 1: Fengshi
Bucket 2: Qianqi
Bucket 3: Sunba
Bucket 4:
Bucket 5:
Bucket 6: Wangwu Wangwu
Bucket 7: Zhangsan
Bucket 8: Lisi
Bucket 9: Zhaoliu Zhoujiu Chenyi
这是根据输入模拟的哈希表中的数据分布。每个桶对应一个哈希值,然后在每个桶中列出了对应的学生姓名。需要注意的是,由于"王五"重复出现,因此在桶6中出现了两次。
根据你提供的代码,我注意到了一些问题并给出以下建议:
-
哈希函数的选择:当前的哈希函数只是将姓名中每个字符的ASCII码求和并取余数。这种简单的哈希函数可能会导致较高的冲突率,使得哈希表的性能下降。建议考虑使用更复杂的哈希函数,例如乘法哈希或者除法哈希,以减少冲突。
-
内存泄漏:在插入节点时,为新节点分配了内存空间,但是在程序结束后没有释放这些节点的内存空间,这会导致内存泄漏。建议在程序结束前,遍历哈希表并释放所有节点的内存空间。
-
哈希表大小的选择:当前的哈希表大小是固定的,通过宏定义为10。然而,实际应用中,哈希表的大小应该根据预计的数据量进行动态调整,以避免过多的冲突或者浪费内存空间。
-
输入安全性:在接受用户输入时,代码没有对输入进行严格的验证和处理,存在缓冲区溢出的风险。建议使用安全的输入函数,如
fgets()来获取用户输入,并对输入进行适当的验证和处理。文章来源:https://www.toymoban.com/news/detail-754589.html -
错误处理:代码没有对插入节点时的内存分配失败进行错误处理。在实际应用中,应该检查内存分配函数(如
malloc())的返回值,以确保分配成功,并在分配失败时采取适当的错误处理措施。文章来源地址https://www.toymoban.com/news/detail-754589.html
到了这里,关于上机实验四 哈希表设计 西安石油大学数据结构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!