| ✌️✌️✌️大家好呀,你们的作业侠又轰轰轰的出现了,这次给大家带来的是python爬虫,实现的是爬取某城市的天气信息并使用matplotlib进行图形化分析✌️✌️✌️ |
要源码可私聊我。
大家的关注就是我作业侠源源不断的动力,大家喜欢的话,期待三连呀😊😊😊
往期源码回顾:
【Java】实现绘图板(完整版)
【C++】图书管理系统(完整板)
【Java】实现计算器(完整版)
有需要的小伙伴自取哦!
进入今天的正题:

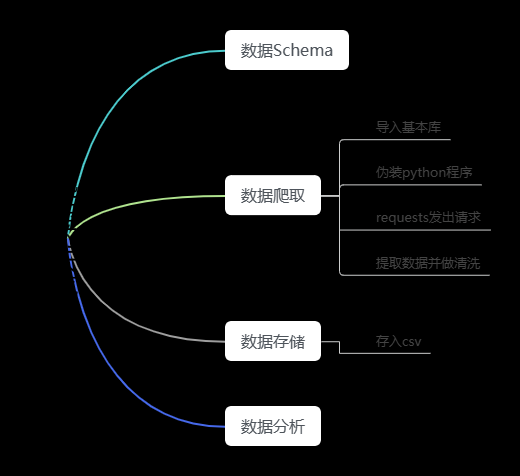
1.实现需求:
| 从网上(随便一个网址,我爬的网址会在评论区告诉大家,dddd)获取某一年的历史天气信息,包括每天最高气温、最低气温、天气状况、风向等,完成以下功能: (1)将获取的数据信息存储到csv格式的文件中,文件命名为”城市名称.csv”,其中每行数据格式为“日期,最高温,最低温,天气,风向”; (2)在数据中增加“平均温度”一列,其中:平均温度=(最高温+最低温)/2,在同一张图中绘制两个城市一年平均气温走势折线图; (3)统计两个城市各类天气的天数,并绘制条形图进行对比,假设适合旅游的城市指数由多云天气占比0.3,晴天占比0.4,阴天数占比0.3,试比较两个城市中哪个城市更适合旅游; (4)统计这两个城市每个月的平均气温,绘制折线图,并通过折线图分析该城市的哪个月最适合旅游; (5)统计出这两个城市一年中,平均气温在18~25度,风力小于5级的天数,并假设该类天气数越多,城市就越适宜居住,判断哪个城市更适合居住; |
爬虫代码:
import random
import time
from spider.data_storage import DataStorage
from spider.html_downloader import HtmlDownloader
from spider.html_parser import HtmlParser
class SpiderMain:
def __init__(self):
self.html_downloader=HtmlDownloader()
self.html_parser=HtmlParser()
self.data_storage=DataStorage()
def start(self):
"""
爬虫启动方法
将获取的url使用下载器进行下载
将html进行解析
数据存取
:return:
"""
for i in range(1,13): # 采用循环的方式进行依次爬取
time.sleep(random.randint(0, 10)) # 随机睡眠0到40s防止ip被封
url="XXXX"
if i<10:
url =url+"20210"+str(i)+".html" # 拼接url
else:
url=url+"2021"+str(i)+".html"
html=self.html_downloader.download(url)
resultWeather=self.html_parser.parser(html)
if i==1:
t = ["日期", "最高气温", "最低气温", "天气", "风向"]
resultWeather.insert(0,t)
self.data_storage.storage(resultWeather)
if __name__=="__main__":
main=SpiderMain()
main.start()
import requests as requests
class HtmlDownloader:
def download(self,url):
"""
根据给定的url下载网页
:param url:
:return: 下载好的文本
"""
headers = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0"}
result = requests.get(url,headers=headers)
return result.content.decode('utf-8')
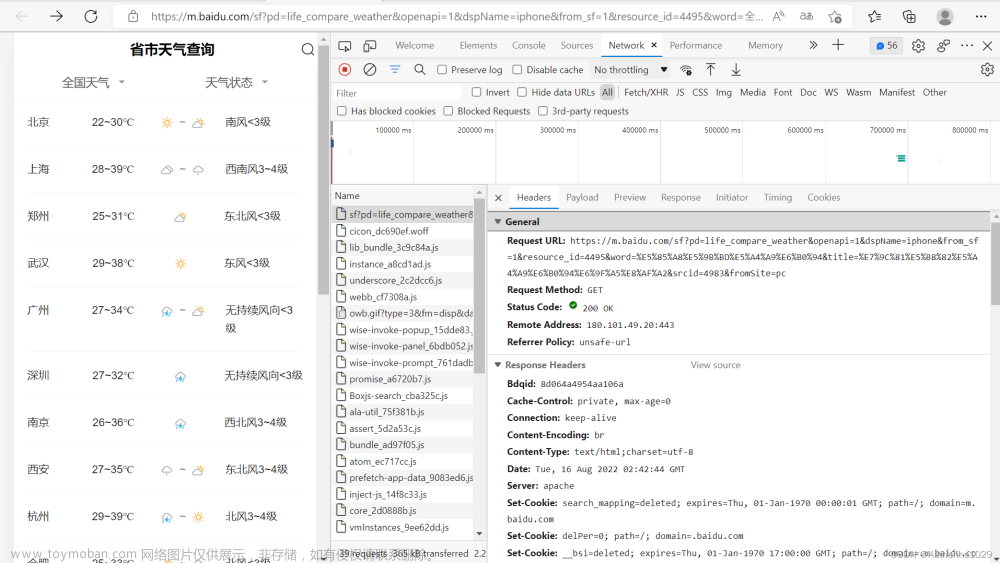
此处大家需要注意,将User-Agent换成自己浏览器访问该网址的,具体如何查看呢,其实很简单,只需大家进入网站后,右键网页,然后点击检查将出现这样的界面: 然后只需再点击网络,再随便点击一个请求,如下图:
然后只需再点击网络,再随便点击一个请求,如下图: 就可以进入如下图,然后再复制,图中User-Agent的内容就好了!
就可以进入如下图,然后再复制,图中User-Agent的内容就好了!

继续:
from bs4 import BeautifulSoup
class HtmlParser:
def parser(self,html):
"""
解析给定的html
:param html:
:return: area set
"""
weather = []
bs = BeautifulSoup(html, "html.parser")
body = bs.body # 获取html中的body部分
div = body.find('div', {'class:', 'tian_three'}) # 获取class为tian_three的<div></div>
ul = div.find('ul') # 获取div中的<ul></ul>
li = ul.find_all('li') # 获取ul中的所有<li></li>
for l in li:
tempWeather = []
div1 = l.find_all("div") # 获取当前li中的所有div
for i in div1:
tempStr = i.string.replace("℃", "") # 将℃进行替换
tempStr = tempStr.replace(" ", "") # 替换空格
tempWeather.append(tempStr)
weather.append(tempWeather)
return weather
import pandas as pd
class DataStorage:
def storage(self,weather):
"""
数据存储
:param weather list
:return:
"""
data = pd.DataFrame(columns=weather[0], data=weather[1:]) # 格式化数据
data.to_csv("C:\\Users\\86183\\Desktop\\成都.csv", index=False, sep=",",mode="a") # 保存到csv文件当中
注意,文件保存路径该成你们自己的哦!
ok,爬取代码就到这,接下来是图形化效果大致如下:



代码如下:文章来源:https://www.toymoban.com/news/detail-754628.html
需要完整源码,只需5元, 需要请加位心:ch18384322303,备注:xx源码
好的这次就到这儿吧,我们下次见哦!!!文章来源地址https://www.toymoban.com/news/detail-754628.html
到了这里,关于【Python】实现爬虫(完整版),爬取天气数据并进行可视化分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!