# 0 简介
今天学长向大家介绍适合作为毕设的项目:
毕设分享 基于Python实现的新闻搜索引擎(源码+论文)
项目获取:文章来源:https://www.toymoban.com/news/detail-754724.html
https://gitee.com/sinonfin/algorithm-sharing文章来源地址https://www.toymoban.com/news/detail-754724.html
基于Python实现的新闻搜索引擎
一、Scraper - 爬虫
使用的库有:
-
requests
-
BeautifulSoup4
爬虫分为两部分,网络通信部分(scraper.py)与适配器(adapers/*.py)部分。
1.1 网络通信部分
网络部分也分为两部分:
-
第一部分是初始化部分,使用适配器提供的链接,下载数据后发给适配器(适配器用这些链接捕获哪些链接是下一步需要爬取的)
-
第二部分是爬取新闻的部分,适配器在前一步里得到了大量的新闻链接,通信部分便用这些链接进行爬取。爬取之后,再将这些数据传入适配器,然后得到返回值(包含新闻的ID、标题、内容、日期、来源)
全部爬完之后,将新闻数据以json格式存入到文件里,其中新闻的内容是html,不是纯文本(保留了原网站的一些排版、外链图片等信息)。
这一部分是多线程(默认是10个线程)的,也就是说适配器必须要是线程安全的。
1.2 适配器部分
适配器部分为通信部分提供链接(url)、报文头(headers)、请求参数(params),需要实现7个函数:
-
hasNextInit():判断是否有下一个初始链接,有的话返回True -
nextInitParam():返回下一个初始链接的信息,包括op和上述的url、headers、params,其中op是你想加入的额外的信息 -
init(op, text):op表示上一个函数你所加入的额外的信息,text表示上一个函数请求的url所得到的html数据 -
hasNext():判断是否有下一个新闻链接,有的话返回True -
nextParam():返回下一个新闻链接的信息,包括op和上述的url、headers、params,其中op是你想加入的额外的信息 -
eval(op, text):op表示上一个函数你所加入的额外的信息,text表示上一个函数请求的url所得到的html数据 -
‘encoding()’:返回所爬取网页用的编码格式(用于网络部分解析html数据)
请一定注意,这些函数都必须要线程安全。
二、Web - 网页
2.1 前端
-
使用
Boostrap 3写的UI -
使用
JavaScript(大部分是jQuery)进行各种UI更新操作,比如分页、高亮、使用ajax获取各种服务器上的数据,动态更新网页等 -
包含三种页面:主页(
/)、搜索页(/s??wd=中国&bg=2001-01-25&ed=2018-01-25)、新闻详细页(/post?id=people_1)
2.2 后端
我使用的数据库是Django默认自带的SQLite,因此我只需要实现几个models就能实现数据的读写了。我一共写了4个models(位于/web/postdb/models.py):
-
WebInfo:存储每个适配器(adapter)的数据信息-
name:适配器的名字(比如people、xinhua) -
count:该适配器目前有多少数据从爬虫部分的json文件里导入进了数据库(用于下一次从该json文件里更新数据)
-
-
PostInfo:存储每篇新闻的数据信息-
NID(Number ID):每篇新闻的纯数字ID(从1开始),用于减少网络通信时数据传输的大小 -
TID(Text ID):每篇新闻的文本ID,是适配器名字_number这样命名,比如people_1,用于在/post?id=people_1里展示(而不是以纯数字的方式,因为这样难以区分) -
time:新闻发表的时间,用datetime类型存储 -
category:新闻的分类(中文),比如“社会”、“时政”、“军事”等 -
title:新闻的标题 -
content:新闻的内容(html) -
plain:新闻的内容(纯文本) -
url:新闻是从哪里爬取的?就是从该url爬取的 -
sourceLink:新闻的来源链接(每篇新闻都有个来源,不一定就是url) -
sourceText:新闻的来源文本(比如“新华网”、“人民网”)
-
-
IndexInfo:存储每个词语对应的新闻(倒排列表索引),同时存储新闻的一些信息-
key:词语 -
value:该词语所对应的倒排列表(list),这个列表的每一个元素的格式为[在该新闻里的出现次数, 该新闻的NID,该新闻的发表时间], 比如[1234, '3', datetime(2018, 1, 2)]。该列表会转化成json格式的字符串存储在value内
-
-
PostRelation:存储每篇新闻相关联的几篇新闻(默认是3篇),将其作为该新闻的推荐新闻-
NID:新闻的NID -
relation:相关联新闻的列表(list),这个列表的每一个元素的格式为{'title': 关联新闻的标题, 'TID': 关联新闻的ITD}。该列表会转化成json格式的字符串存储在relation内
-
2.3 新闻搜索算法
先介绍IndexInfo数据库的建立。
将每篇新闻的纯文本进行分词(使用thulac),同时统计每个词出现的次数。然后根据格式存入IndexInfo里的value。
对于每一个搜索的字符串,我们将这个字符串也分词。对于每个词语,我们从IndexInfo里取出倒排列表,将每个新闻的出现次数累加。最后根据每条新闻的累加次数,从大到小排个序,然后返回这些新闻的NID。
2.4 推荐新闻算法
用一个最简单的办法:将这篇新闻的标题拿去新闻搜索算法里进行搜索,然后取出前几条新闻即可。这是因为,新闻的标题有高度的概括性(而且是人为的),在一定程度上可以代表整篇文章。
我们用该办法预处理一下每篇新闻,然后存入PostRelation数据库里即可。
三、界面
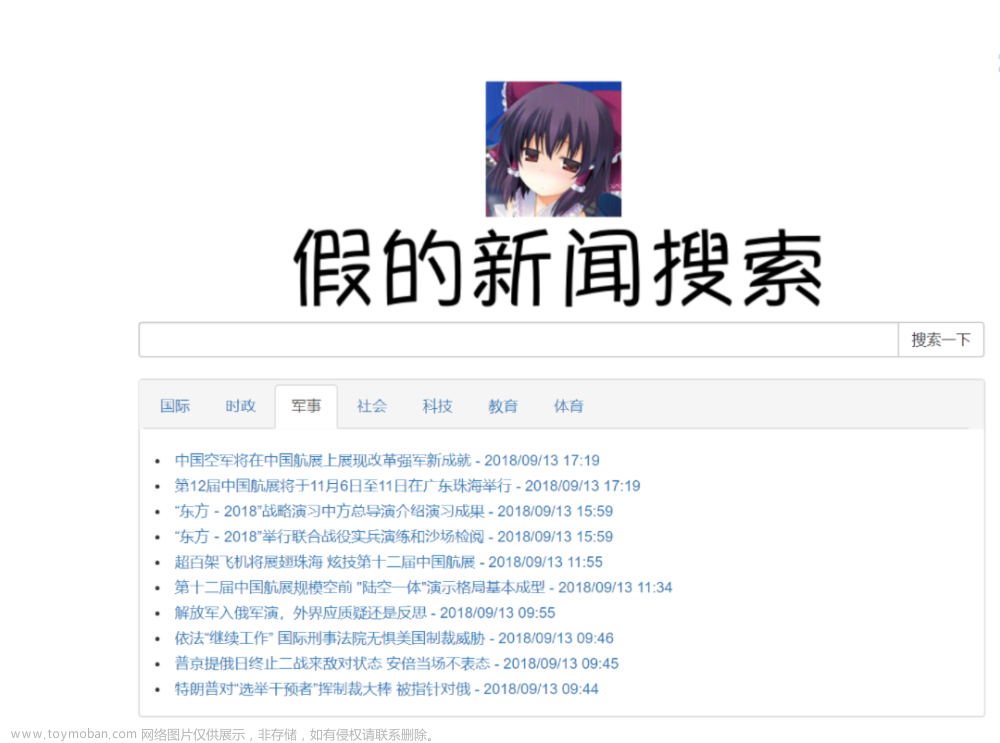
首页

搜索新闻
推荐展示
四、使用说明
4.1 本机环境
-
Python 3.7.0
-
Django 2.1.1
-
requests 2.19.1
-
BeautifulSoup4 4.6.3
-
thulac
4.2 使用
首先使用scraper文件夹下的爬虫scraper.py对“人民网”、“新华网”的新闻进行爬取:
python scraper.py
之后会将爬取的数据存储到people.json和xinhua.json中,然后在web文件夹下,运行:
python manage.py makemigrations
python manage.py migrate
初始化数据库,然后再执行:
python manage.py updateDB
将爬取的数据导入到数据库中(这可能会等很长时间),之后再执行:
python manage.py updateRelation
更新文章推荐的数据库,最后:
python manage.py runserver
启动服务器即可,你就可以通过127.0.0.1:8000进行访问网站了。
目前的效率是,17000篇新闻的话,在i5-7200U的机子上查询新闻只要0.1s左右。(反正Django自带的sqlite有多快我这个就有多快)
项目分享
项目获取:
https://gitee.com/sinonfin/algorithm-sharing
到了这里,关于毕设 基于Python实现的新闻搜索引擎(源码+论文)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!