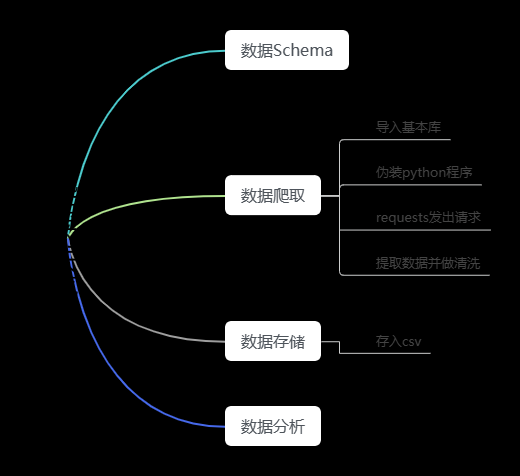
Python爬虫可以用来抓取拼多多商品数据,并对这些数据进行数据分析。以下是一个简单的示例,演示如何使用Python爬取拼多多商品数据并进行数据分析。
首先,需要使用Python的requests库和BeautifulSoup库来抓取拼多多商品页面。以下是一个简单的示例代码:
import requests
from bs4 import BeautifulSoup
# 定义页面URL
url = 'https://mobile.pinduoduo.com/goods-detail.html?goods_id=32955439328'
# 发送GET请求获取页面内容
response = requests.get(url)
html = response.content
# 使用BeautifulSoup解析HTML页面
soup = BeautifulSoup(html, 'html.parser')
# 从页面中提取商品信息
title = soup.find('h1', {'class': 'goods-title'}).text.strip()
price = soup.find('span', {'class': 'goods-price'}).text.strip()
sales = soup.find('span', {'class': 'goods-sales'}).text.strip()
# 打印商品信息
print('商品标题:', title)
print('商品价格:', price)
print('销量:', sales)在上面的代码中,我们使用requests库发送GET请求获取拼多多商品页面内容,然后使用BeautifulSoup库解析HTML页面,并从中提取商品信息。最后,我们将商品信息打印出来。
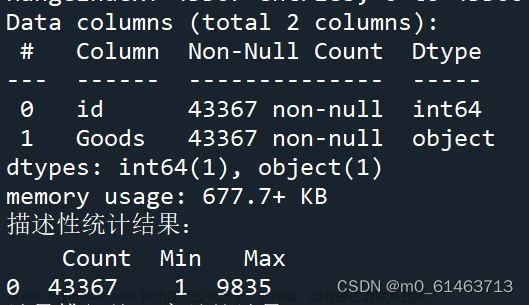
当我们获取了足够的商品数据后,可以使用Python的pandas库对这些数据进行数据分析。以下是一个简单的示例代码:
import pandas as pd
# 创建DataFrame存储商品数据
data = {
'标题': ['商品1', '商品2', '商品3'],
'价格': [100, 200, 150],
'销量': [1000, 500, 800]
}
df = pd.DataFrame(data)
# 计算平均价格和平均销量
mean_price = df['价格'].mean()
mean_sales = df['销量'].mean()
# 打印平均价格和平均销量
print('平均价格:', mean_price)
print('平均销量:', mean_sales)在上面的代码中,我们使用pandas库创建DataFrame存储商品数据,并计算平均价格和平均销量。最后,我们将计算结果打印出来。此外,我们还可以使用pandas库提供的其他函数和方法来进行更复杂的数据分析和处理。文章来源:https://www.toymoban.com/news/detail-754744.html
需要注意的是,爬取拼多多商品数据需要遵守拼多多的使用协议和规定,避免过度请求和滥用数据。文章来源地址https://www.toymoban.com/news/detail-754744.html
到了这里,关于Python 爬虫实战之爬拼多多商品并做数据分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)