ceph
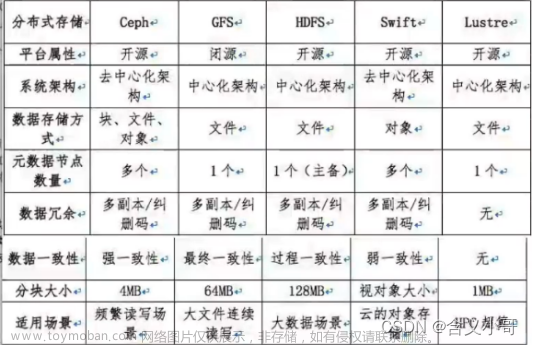
Ceph(分布式存储系统)是一个开源的分布式存储系统,设计用于提供高性能、高可靠性和可扩展性的存储服务,可以避免单点故障,支持块存储、对象存储以及文件系统存储应用。使用C++语言开发。ceph能够通过网络将数据分散存储在多台独立设备上
ceph具有可扩展性:
-
水平扩展,新的节点加入集群后只需要和原有集群连接到同一网络,无需对现有节点进行重大修改或中断
-
节点扩展后,旧数据会自动迁移到新节点,实现负载均衡,避免单点过热的情况
-
使用crush算法来确定数据在存储集群中的位置
组件

-
OSD: OSD(Object Storage Daemon)用于集群中所有对象与数据的存储,处理集群数据的复制、恢复、负载均衡。也能够自动检测存储磁盘的监控状况,定期向Monitor节点报告自身的状态和性能指标
读取数据时,多台OSD会同时对外传输数据,于是传输的速度会比较块
当ceph集群设定数据有两个副本时,至少需要两个OSD进程即OSD节点,集群才能达到active+clean状态
-
MON: MON(Monitor)负责维护Ceph存储集群的状态信息、配置信息和监控信息,维护集群的cluster MAP二进制表,保证集群数据的一致性,cluster MAP描述了对象块存储的物理位置,以及一个将设备聚合到物理位置的桶列表
-
MDS: MDS(Metadata Server)元数据服务器,提供元数据计算,缓存与同步。在ceph中,元数据也是存储在osd节点中的,mds类似于元数据的代理缓存服务器。mds是 CephFS(Ceph 文件系统)的组成部分,cep块设备和ceph对象存储不使用mds
-
Manager: ceph-mgr,用于收集ceph集群状态、性能指标、配置信息。
manager通过RESTful API和Web-based Dashboard向外提供信息
ceph结构包含两个部分
ceph client,访问ceph底层服务或组件,对外提供各种接口
ceph node,底层服务提端,也就是ceph存储集群
存储类型
块存储
块存储(RBD - RADOS Block Device),存储数据以块为单位,可被映射为块设备,适用于直接附加到虚拟机或物理服务器。类似于传统的硬盘
块存储通过Raid与LVM等手段,对数据提供了保护,多块磁盘组合可以提高容量,也可以做逻辑盘,提高读写效率
但主机之间无法共享数据
块存储应用于docker容器、虚拟机磁盘分配;日志存储;文件存储
文件存储
文件存储(CephFS)可以克服块存储无法共享的问题。如FTP、NFS服务器
文件存储允许多个节点通过标准文件系统接口访问相同的文件和目录。它支持文件的读写、权限控制等 POSIX 文件系统语义
对象存储
一个文件具有属性metadata,也称元数据,包含该文件的大小、修改时间、存储路径等
在对象存储(RADOS)中,数据以对象的形式存储,每个对象都有唯一的标识符。它会将文件的元数据独立出来,控制节点叫元数据服务器(服务器+对象存储管理软件),主要负责存储对象的属性。文件的数据部分主要由OSD存储
当用户访问对象时,会首先访问元数据服务器,元数据服务器反馈对象存储在哪些OSD,用户再去访问那些OSD读取数据
对象存储主要用于存储大量非结构化数据,如图像、音频、视频、日志等文章来源:https://www.toymoban.com/news/detail-754985.html
存储过程
 文章来源地址https://www.toymoban.com/news/detail-754985.html
文章来源地址https://www.toymoban.com/news/detail-754985.html
- 用户访问一个文件File,其存储的数据会被切分成多个对象Objects,Objects的大小可以由管理员调整
- 每个对象都有一个唯一的oid,这个iod由文件file的id,ino,和分片objects的编号ono组成。oid可以唯一标识每个不同的对象,并存储了对象与文件的存储关系
- PG,placement group归置组是一个逻辑概念,它在数据寻址时相当于数据库中的索引,每个对象都会固定映射进一个PG中。所以当需要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG,无需遍历所有对象。并且在迁移数据时,也是以PG作为基本单位迁移
- 对象映射进PG,首先会对oid做hash取出特征码,用特征码与PG的数量去模,得到序号pgid
- 最后PG会根据管理员设置的副本数量进行复制,通过crush算法存储到不同的OSD节点上,第一个OSD为主节点,其余均为从节点
到了这里,关于初识Ceph --组件、存储类型、存储原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!