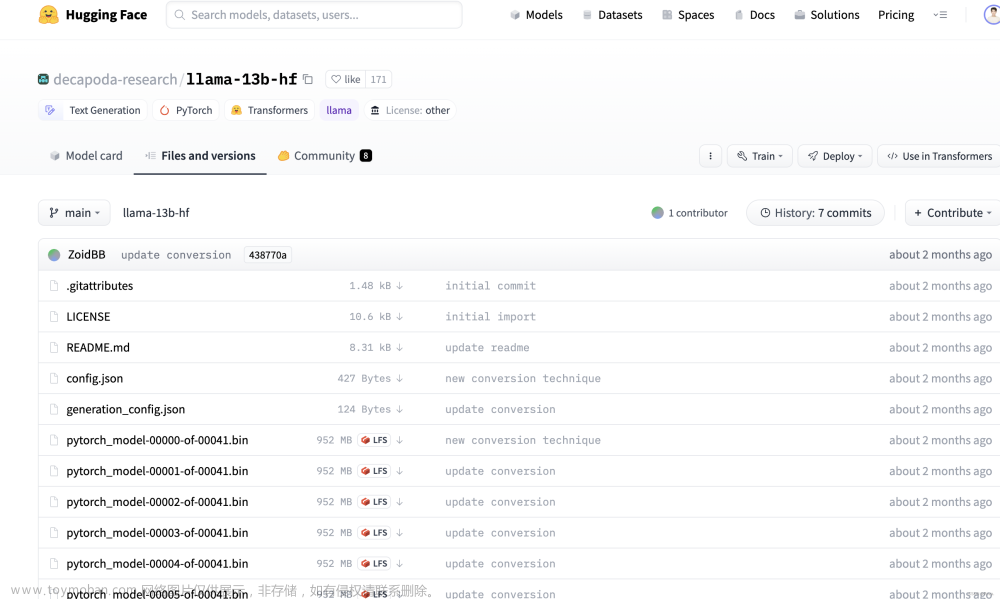
#源码里找到的
_MODELS = {
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large-v3": "https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt",
}
加速下载apt install aria2
aria2c -x 16 https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt --all-proxy=http://host.docker.internal:7890
我这是在容器里用代理,代理选项可去除
这是gpt4给我的代码:文章来源:https://www.toymoban.com/news/detail-755233.html
我想写一个python程序,在我发出“过”的语音时,打印“过”(实际上是执行某种操作,我会将它嵌入到其他程序中,目前只打印字符串),在我发出“下一个”的语音时,打印“下一个”,我想使用https://huggingface.co/openai/whisper-large-v3实现文章来源地址https://www.toymoban.com/news/detail-755233.html
import whisper
import sounddevice as sd
import numpy as np
# 录音设置
duration = 5 # 录音时长(秒)
samplerate = 16000 # 采样率
def record_audio(duration, samplerate):
"""录制音频"""
recording = sd.rec(
int(duration * samplerate), samplerate=samplerate, channels=1, dtype="float32"
)
sd.wait()
return recording
def transcribe_audio(audio, model):
"""使用Whisper模型转录音频"""
audio = np.squeeze(audio) # 确保音频是一维的
result = model.transcribe(audio)
return result["text"]
def main():
# 加载Whisper模型
model = whisper.load_model("large-v3")
while True:
print("开始录音...")
audio = record_audio(duration, samplerate)
print("录音结束,正在识别...")
# 识别语音
text = transcribe_audio(audio, model)
# 根据识别结果执行操作
if "过" in text:
print("过")
elif "下一个" in text:
print("下一个")
else:
print("未识别到指令")
print(text)
if __name__ == "__main__":
main()
到了这里,关于whisper large-v3 模型文件下载链接的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[NLP]Huggingface模型/数据文件下载方法](https://imgs.yssmx.com/Uploads/2024/02/603970-1.png)