本文参考了许多官网和博客,肯定是存在抄袭的,请各位大哥不要喷我啊。
自己工作找到的是医学信号方向的算法工程师,所以以后和CV可能无缘了,将自己一个多星期的心血历程发表出来,希望大家接起我的CV火炬,接着前行,各位加油!(后面也学习了yolov5-6.0 yolov7的模型部署)
本人小白,没怎么发过博客,所以有点乱,标题也没整,太费时间了,我的态度真的是极差,不管了,哈哈哈。话不多说,开整吧
烧录环境: Ubuntu20.04 主机 (虚拟机也可以),为了下载资源,烧录用的ubuntu20.04主机需要预留大约100G的内存空间。
我的windows装了双系统,首先进入Ubuntu系统安装SDK Manager
SDK Manager下载链接:SDK Manager | NVIDIA 开发者(.com进不去,改成了.cn)
为了后续可以正常下载资源和烧录系统,请在NVIDAI DEVELOPER网站点击右上角的JOIN先注册一个账号

文章来源地址https://www.toymoban.com/news/detail-755500.html
- 将deb文件下载到ubuntu系统上,然后将deb文件复制到用户主目录下
- 打开终端运行以下程序安装sdk manager
sudo apt install ./这里是文件名.deb
备注:注意将指令中的[version]-[build#] 改成实际下载的文件名
硬件配置(进入recovery 模式)
- 用跳帽或者杜邦线短接FC REC和GND(我接的是2号和3号)引脚,位置如图,位于核心板底下
- 连接DC电源到圆形供电口, 稍等片刻
- 用USB线(注意要是数据线)连接Jetson主板的Micro USB接口到Ubuntu主机

烧录系统
打开ubuntu电脑终端,运行sdkmanager打开软件,登录账号,如果Jetson 主板有被正常识别到。sdk manager会检测并提示选项

- 开发板类型选择Jetson Xavier NX 选项(如果你使用的是官方套件, 选择另一选项)
- 在JetPack选项中,选择支持的最新系统即可(我选择的jetpack5.0.2),不勾选其他的SDK, 然后点击Continue
- 选择Jetson Linux, 并将Jetson SDK Components的选项去掉。勾选最下方的第一个协议

最后点击Continue 等待烧录完成即可。
第一次的时候烧写失败,重新烧写的说话会弹出
- 这里会默认选择开发板类型。 注意前面选择开发板类型的时候不要选择错误。
- 这里选择Manual Setup-Jetson ... (不同主板后缀提示不同)
- 这里可以选择runtime或者preconfig, 选择runtime的话,后续需要自己手动配置系统(用户名,密码,语言等), 选择preconfig,可以填入用户名和密码(可以自己定义),会在启动过程中自动配置主板

- 烧录完成之后,去掉底板的跳帽,接入显示器,重新上电(最好重新上电),按照提示进行开机配置(如果是设置的pre-config, 上电后直接进入系统)。
系统从ssd盘启动
打开ubuntu的自带的 Disks 工具(windows的win,然后输入disk)


点击format 这是格式化的流程
输入管理员密码

格式化完之后的结果如下,现在开始分区(我的是128g,直接分区就行了)

这里一定要选择Ext4才行,点击创建
开始复制系统文件到SSD盘
git clone https://github.com/jetsonhacks/rootOnNVMe.git
进入rootOnNvme
cd rootOnNVMe
执行复制脚本,结果如下
./copy-rootfs-ssd.sh
执行脚本,设置ssd为启动盘
./setup-service.sh

重启即可生效,reboot
sdk-manager安装cudn
这个安装可前面安装JetPack系统操作类似,然后将板子上Micro USB通过数据线和电脑链接。

换源: 使用操作指令之前对系统进行国内清华源的更换
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak sudo vim /etc/apt/sources.list
加入
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main universe restricted deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main universe restricted
然后退出
在终端输入
sudo apt update sudo apt-get install python3-pip
默认安装的PIP是 9.01 版本,需要把它升级到最新版
python3 -m pip install --upgrade pip
升级成功后,查看pip版本信息,发现有些问题
pip3 -V

python3 -m pip install --upgrade --force-reinstall pip
sudo reboot

换源
通过编辑pip的配置文件进行设置,方法如下:
mkdir ~/.pip
vim ~/.pip/pip.conf
添加内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
配置CUDA环境变量
安装完成后,输入ncvv -V,发现并不能读取CUDA的版本,这是因为环境变量还没有配置
输入vim ~/.bashrc命令打开文件,在文件结尾输入以下语句,保存。
export CUDA_HOME=/usr/local/cuda
export PATH=${CUDA_HOME}/bin:${PATH}
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:$LD_LIBRARY_PATH
source ~/.bashrc
然后再输入nvcc -V,就可以看到CUDA的版本信息了。
配置cuDNN
虽然安装了cuDNN,但没有将对应的头文件、库文件放到cuda目录。cuDNN的头文件在:/usr/include,库文件位于:/usr/lib/aarch64-linux-gnu。将头文件与库文件复制到cuda目录下:
cd /usr/include && sudo cp cudnn.h /usr/local/cuda/include
cd /usr/lib/aarch64-linux-gnu && sudo cp libcudnn* /usr/local/cuda/lib64
修改文件权限,修改复制完的头文件与库文件的权限,所有用户都可读,可写,可执行:
sudo chmod 777 /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
重新链接
cd /usr/local/cuda/lib64
sudo ln -sf libcudnn.so.8.4.0 libcudnn.so.8
sudo ln -sf libcudnn_ops_train.so.8.4.0 libcudnn_ops_train.so.8
sudo ln -sf libcudnn_ops_infer.so.8.4.0 libcudnn_ops_infer.so.8
sudo ln -sf libcudnn_adv_infer.so.8.4.0 libcudnn_adv_infer.so.8
sudo ln -sf libcudnn_cnn_infer.so.8.4.0 libcudnn_cnn_infer.so.8
sudo ln -sf libcudnn_cnn_train.so.8.4.0 libcudnn_cnn_train.so.8
sudo ln -sf libcudnn_adv_train.so.8.4.0 libcudnn_adv_train.so.8
sudo ldconfig
测试cuDNN
sudo cp -r /usr/src/cudnn_samples_v8/ ~/
cd ~/cudnn_samples_v8/mnistCUDNN
sudo chmod 777 ~/cudnn_samples_v8
sudo make clean && sudo make
./mnistCUDNN
报错
test.c:1:10: fatal error: FreeImage.h: 没有那个文件或目录 #include "FreeImage.h" ^~~~~~~~~~~~~
解决方法:
sudo apt-get install libfreeimage3 libfreeimage-dev
测试cuDNN
sudo cp -r /usr/src/cudnn_samples_v8/ ~/
cd ~/cudnn_samples_v8/mnistCUDNN
sudo chmod 777 ~/cudnn_samples_v8
sudo make clean && sudo make
./mnistCUDNN
如果配置成功 测试完成后会显示:“Test passed!”。
安装机器学习领域重要的包
sudo apt-get install python3-numpy
sudo apt-get install python3-scipy
sudo apt-get install python3-pandas
sudo apt-get install python3-matplotlib
sudo apt-get install python3-sklearn
安装pytorch
pytorch版本不能随意安装,必须安装英伟达编译的好的库文件,我的jetpack是5.0.2的,所以可以选择1.12.0版本的pytorch。点击链接然后下载。链接:https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048。
选择对应jetpack版本的pytorch文件。

下载依赖库
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev libopenblas-base libopenmpi-dev
会弹出有些包不满足依赖项的报错,sudo apt-get install 安装就好了
安装Pytorch
sudo pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
import torch报错
ImportError: libopenblas.so.0: cannot open shared object file
解决:
sudo apt-get install libopenblas-dev
验证Pytorch是否安装成功
python3
import torch
x = torch.rand(5, 3)
print(x)

查看版本信息
import torch
print(torch.__version__)

安装vision torchvision

v1.12.0版本的pytorch对应v0.13.0版本的vision torchvision,所以执行命令:
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
报错:

原因是:由于git默认缓存大小不足导致的。解决方法是:使用下面的命令增加缓存大小(自行根据实际情况确定):
git config --global http.postBuffer 2000000000
检查是否修改成功:
git config --list

重新
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision

还是报错:
使用过
pip3 install torchvision==0.13.0
会报错,原因是版本不匹配,卸载torchvision
pip3 uninstall torchvision
最后,直接在windows电脑上下载这个包,然后用U盘复制到jetson,打开网址GitHub - pytorch/vision: Datasets, Transforms and Models specific to Computer Vision,选择我需要的torchvision 0.13.0版本

然后下载
解压,将解压后的文件复制到U盘,然后复制到jetson的home目录下
然后在终端输入
cd vision-0.13.0
export BUILD_VERSION=0.13.0
sudo python3 setup.py install
然后这里报错,我是吐了,整了一晚上
sudo apt-get install python3-setuptools
解决
cd vision-0.13.0
export BUILD_VERSION=0.13.0
sudo python3 setup.py install

漫长的等待,大概十几二十分钟终于完成,测试版本
python3
import torchvision
print(torchvision.__version__)

# 安装Jtop工具
sudo -H pip3 install -U jetson-stats
安装好之后
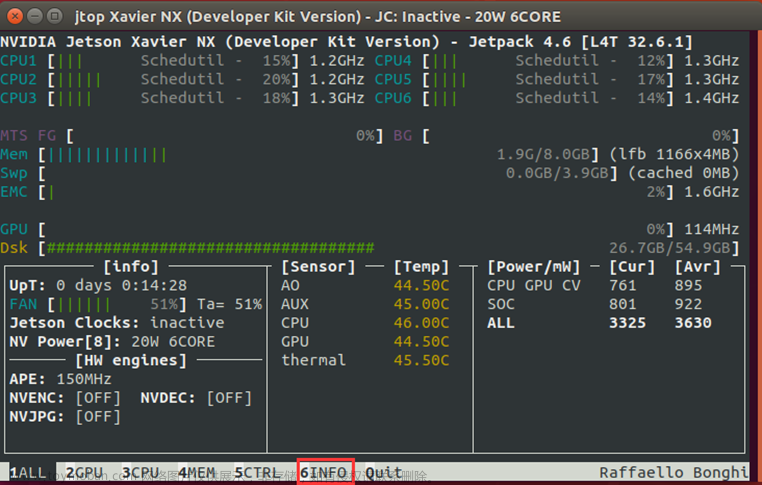
输入jtop,下面有一排选项可以点,我的系统配置是这样的

这里要手动启动风扇,我懒得开机了,好像是在最下面的6CTRL里面,自己百度搜一下就知道了
运行yolov5的detect.py出现下面的这个问题,有些包没安装自己安装就行了

那么我们跟着错误去上面的提示信息找方法
可以发现是关于"Upsample“和 'recompute_scale_factor',相关的提示是在这里

紧接着 ,按着提示文件路径一步一步的打开usampling.py,找到第155行附近
进入路径 cd /sur/local/lib。。。。上面圈出来的 sudo gedit upsampling.py

然后把第154行还有153行最后的逗号","删掉,再保存一下子

然后运行下detect.py,发现问题解决,但是会报别的错
numpy版本太新了
pip3 install numpy==1.20.0
就可以检测啦
sudo apt-get install gcc
sudo apt-get install g++
sudo apt-get install make
安装cmake
sudo apt-get update
sudo apt-get install git cmake libpython3-dev python3-numpy
可能需要安装修改一些依赖包
开始模型部署
GitHub - wang-xinyu/tensorrtx at yolov5-v5.0这个网址下载tensorrtx(要和自己的yolo版本对应)
.pt转.wts
tensorrtx项目通过tensorRT的Layer API一层层搭建模型,模型权重的加载则通过自定义方式实现,通过get_wts.py文件将yolov5模型的权重即yolov5.pt保存成yolov5.wts,生成的yolov5.wts文件即作者自定义的权重文件方便后续加载使用。将转换生成的yolov5.wts文件拷贝回到yolov5文件夹下
yolov5s.wts文件生成指令如下:
python gen_wts.py -w weights/yolov5s.pt yolov5s.wts
错误如下:
Traceback (most recent call last): File "gen_wts.py", line 6, in <module> from utils.torch_utils import select_device ModuleNotFoundError: No module named 'utils.torch_utils'
解决方案如下:
get_wts.py文件依赖于yolov5官方源码,需要下载yolov5官方源码并进行如下操作
git clone -b v6.0 https://github.com/ultralytics/yolov5.git // 下载yolov5-6.0源码
cp tensorrtx/yolov5/gen_wts.py yolov5-6.0 // 将get_wts.py文件和权重文件拷贝到yolov5源码中
python gen_wts.py -w yolov5s.pt -o yolov5s.wts // 生成wts文件
生成的wts权重文件部分内容如下图所示
.wts文件为纯文本文件
350为模型所有键对应的数目即表示它有多少行(不包括自身)
每一行形式是 [权重名称] [value count = N] [value1] [value2] … [valueN]
model.0.conv.weight为模型权重保存的第一个键的名称
3456为模型权重保存的第一个键对应值的总长度
后面的数字为模型权重保存的第一个键对应的值,以十六进制的形式进行保存
加载yolov5s.wts权重文件,并通过tensorRT序列化生成engine引擎文件。注意先修改下yololayer.h中的CLASS_NUM,修改为自训练模型的类别数。如下图所示,本次训练的模型类别数为2,故将CLASS_NUM修改为2。

修改完成后便可进行编译生成引擎文件,指令如下
cd tensorrtx/yolov5
mkdir build && cd build
cp ../yolov5s.wts ./
cmake .. && make
sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
make之后的图片

图解如下所示,执行完成之后会在build目录下生成yolov5s.engine引擎文件

通过tensorRT生成的engine文件进行模型推理,指令如下
sudo ./yolov5 -d yolov5s.engine ../images/
执行完成后会在build目录下生成推理完成后的图片,图解如下
 文章来源:https://www.toymoban.com/news/detail-755500.html
文章来源:https://www.toymoban.com/news/detail-755500.html
到了这里,关于jetson nx目标检测环境配置遇到的一万个坑,安装v1.12.0版本的pytorch和v0.13.0版本的vision torchvision,以及使用TensorRT部署YOLOv5.的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![【PC电脑windows环境下-[jetson-orin-NX]Linux环境下-下载工具esptool工具使用-相关细节-简单样例-实际操作】](https://imgs.yssmx.com/Uploads/2024/02/744760-1.jpeg)







