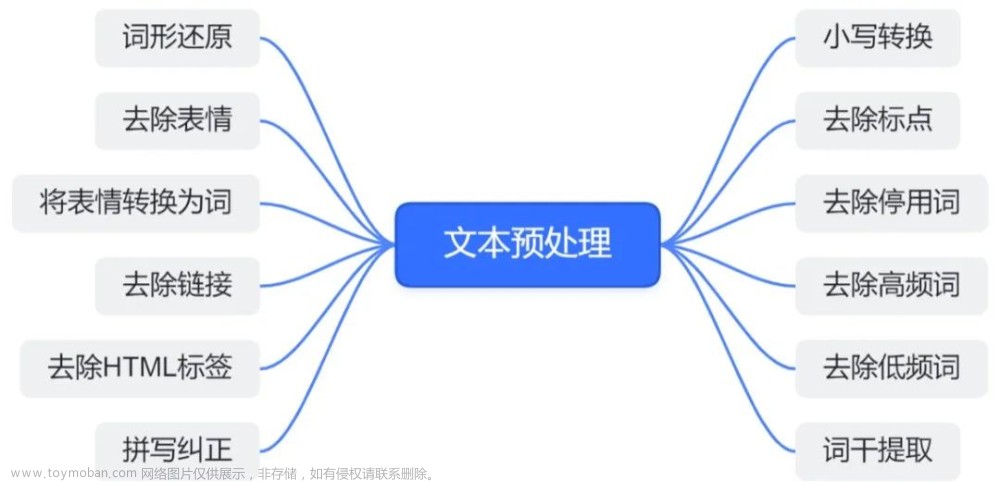
文本预处理是自然语言处理中非常重要的一步,它是为了使得文本数据能够被机器学习模型所处理而进行的一系列操作。其中,去除停用词、词形还原、词干提取等技巧是比较常用的。本文将介绍这些技巧的原理,并提供使用Python实现的代码示例,帮助读者更好地理解和实践。
1.停用词
停用词指在自然语言文本中非常常见的单词,它们通常不携带特定含义,例如“the”、“a”、“an”、“in”等。在文本分析中,这些词语可能会干扰模型的训练效果,因此需要将它们从文本中移除。
在Python中,我们可以使用nltk库来完成停用词的去除。nltk中已经包含了一些常用的停用词列表,我们可以直接使用它们。
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
上述代码首先下载了nltk中的停用词列表,然后使用了英文的停用词列表。使用时,我们可以遍历文本中的所有单词,判断它是否为停用词。如果是,就将它从文本中移除。
text = "this is an example sentence to remove stop words"
words = text.split()
filtered_words = [word for word in words if word.lower() not in stop_words]
filtered_text = " ".join(filtered_words)
print(filtered_text)
上述代码中,我们首先将文本分成单词,然后遍历每个单词。如果单词不是停用词,就将其加入到一个新的列表中。最后,我们将新的列表中的单词重新拼接成一个新的文本。
除了英文停用词之外,中文也有很多常用的停用词。中文停用词的特点是数量较多,而且由于中文词汇结构比英文复杂,所以中文停用词的判断也更加困难。
在中文文本中,一些通用的停用词包括:“的”、“了”、“和”、“是”、“在”、“有”、“不”、“我”、“他”、“你”等。这些词出现的频率很高,但在文本分析中通常没有什么意义。
常见的中文停用词表可以在网上下载,例如中文停用词表:https://github.com/goto456/stopwords。
在Python中,我们可以将中文停用词存储在一个列表中,然后在分词后对文本进行处理,去掉其中的停用词。以下是一个使用中文停用词的代码示例:
import jieba
# 加载中文停用词表
stopwords_path = 'path/to/stopwords.txt'
with open(stopwords_path, 'r', encoding='utf-8') as f:
stopwords = [line.strip() for line in f.readlines()]
# 分词并去除停用词
text = '今天天气真好,适合出去玩。'
words = jieba.cut(text)
clean_words = [word for word in words if word not in stopwords]
print(clean_words)
输出结果为:
['今天', '天气', '真好', '适合', '出去', '玩']
在这个示例中,我们使用jieba库对文本进行分词,并去掉了其中的停用词。
2.词形还原
词形还原 (Lemmatization) 是指将单词转换为它们的原始形式,这个原始形式称为词元 (Lemma) 或基本形式 (Base form)。与词干提取不同,词形还原会考虑单词的上下文语境和词性,因此得到的结果更加准确。
词形还原的处理步骤包括:
- 利用分词技术将文本转换为单词列表。
- 利用词性标注技术为每个单词标注词性。
- 根据每个单词的词性和上下文语境,将单词还原为它们的原始形式。
在自然语言处理中,常用的词形还原算法有基于规则的和基于统计的两种。其中基于规则的算法使用预定义的规则将单词还原为它们的原始形式,而基于统计的算法则根据语料库中单词的出现频率和上下文语境来推断单词的原始形式。
下面是一个使用Python的nltk库进行词形还原的例子:
import nltk
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
wordnet_lemmatizer = WordNetLemmatizer()
text = "My cat is walking on the carpet"
tokens = nltk.word_tokenize(text)
result = []
for token in tokens:
result.append(wordnet_lemmatizer.lemmatize(token, pos='v'))
print(result)
在上述代码中,我们首先使用nltk库的word_tokenize()函数将文本转换为单词列表。然后,我们创建了一个WordNetLemmatizer对象,并使用它的lemmatize()方法将单词还原为它们的原始形式。在这个例子中,我们将单词还原为它们的动词原形。输出结果为:[‘My’, ‘cat’, ‘be’, ‘walk’, ‘on’, ‘the’, ‘carpet’]。
在实际应用中,词形还原通常与停用词去除、词干提取等技术结合使用,以提高文本预处理的效果。
在中文中,词形变化相对英文单词较少,但是词语之间的组合方式比较灵活,同一个词可能会有多种不同的形态。中文的词形还原与英文略有不同,它通常指的是将词语的不同形态转换为它的原始形态。例如,将“吃饭了”和“吃了饭”都还原为“吃饭”。
中文词形还原的实现通常需要借助中文分词技术和词性标注技术。中文分词是将一段文本分解成词语的过程,而词性标注是对每个词语进行词性标记的过程。通过这两个步骤,我们可以识别出每个词语的原始形态,并将其还原。
下面是一个使用中文分词库jieba和词性标注库pynlpir进行中文词形还原的示例代码:
import jieba
import pynlpir
# 加载停用词表
stopwords = []
with open('stopwords.txt', 'r', encoding='utf-8') as f:
for line in f:
stopwords.append(line.strip())
# 初始化分词库和词性标注库
jieba.initialize()
pynlpir.open()
def lemmatize_chinese(text):
"""
中文词形还原函数,输入为一段中文文本,输出为还原后的文本。
"""
words = jieba.cut(text)
lemmatized_words = []
for word in words:
if word not in stopwords: # 去除停用词
pos = pynlpir.segment(word)[0][1] # 获取词性
if pos.startswith('n'): # 名词
lemmatized_words.append(pynlpir.noun_lemmatize(word))
elif pos.startswith('v'): # 动词
lemmatized_words.append(pynlpir.verb_lemmatize(word))
else:
lemmatized_words.append(word)
return ''.join(lemmatized_words)
# 测试
text = "今天天气不错,适合去散步。"
lemmatized_text = lemmatize_chinese(text)
print(lemmatized_text)
在上面的代码中,我们使用了jieba分词库对中文文本进行分词,然后使用pynlpir词性标注库获取每个词语的词性。最后,根据词性使用pynlpir的名词还原和动词还原方法进行词形还原。需要注意的是,在中文中,名词和动词的还原方法通常是不同的。
3.词干提取
词干提取(stemming)是另一种文本预处理技术,它试图从单词中去除词缀,使得词干可以被识别为同一单词的变体。它的目的是将一个单词的各种变体归并为同一个词干,这样可以减少单词形态变化带来的干扰,同时缩小特征空间的规模。
与词形还原不同,词干提取仅仅是将单词的后缀去掉,而不考虑其上下文和语法,因此可能会产生一些无意义的词干。
对于英文单词,Porter stemming算法是最常用的词干提取算法。
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
word_list = ['running', 'runner', 'ran', 'runs']
for word in word_list:
print(f"Stemming '{word}' results in '{stemmer.stem(word)}'")
输出结果如下所示:
Stemming 'running' results in 'run'
Stemming 'runner' results in 'runner'
Stemming 'ran' results in 'ran'
Stemming 'runs' results in 'run'
可以看到,PorterStemmer将所有单词都转换为它们的词干形式,但这并不总是符合语法规则,因为它只是应用了一些简单的规则和规律。在某些情况下,它可能会将不同的单词转换为相同的词干,或将相同的单词转换为不同的词干。因此,在使用词干提取时,需要根据特定的应用场景和数据集来决定是否使用它。
对于中文,中文的分词就可以看作是词干提取的过程。中文分词将句子划分为词语的序列,这些词语是语言中最小的、能够独立运用的语言单位。通常使用一些开源的中文分词工具,如jieba分词、中科院的ictclas分词器等。
以下是使用Python中的jieba分词库进行中文分词的示例代码:
import jieba
text = "我爱自然语言处理技术"
seg_list = jieba.cut(text, cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 输出分词结果
输出结果如下:文章来源:https://www.toymoban.com/news/detail-755503.html
Default Mode: 我/ 爱/ 自然语言处理/ 技术
除了中文分词外,一些专业领域中,还可以使用专门的领域词干提取算法。例如,生物医学领域中的BioStem算法可以用于提取生物词汇的词干。文章来源地址https://www.toymoban.com/news/detail-755503.html
到了这里,关于文本预处理技巧:去除停用词、词形还原、词干提取等的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!