以下是一些可以查询英国国家数据的网站:
1. 英国政府网站(www.gov.uk):提供各个政府部门的数据和统计信息,包括经济、人口、教育、健康、环境等领域。
2. 英国国家统计局(www.ons.gov.uk):英国的官方统计机构,提供广泛的统计数据和报告,涵盖经济、劳动力、人口、社会等各个领域。
3. 英国国家档案馆(www.nationalarchives.gov.uk):保存和提供英国历史档案和记录的机构,可以查询历史数据和文件。
4. 英国经济与社会研究理事会(www.esrc.ac.uk):该机构提供经济、社会和人文科学领域的研究报告和数据。
5. 英国卫生与社会保健信息中心(www.hscic.gov.uk):提供英国卫生和社会保健领域的数据和报告。
6. 英国金融行为监管局(www.fca.org.uk):提供金融服务行业的监管数据和报告。
以上是一些常用的查询英国国家数据的网站,您可以根据自己的需求选择相应的网站进行查询。
import pandas as pd
import math
import numpy as np
# Import data from Excel
data = pd.read_excel('C:/Users/26861/Desktop/eg2.xlsx')
# 提取指标列
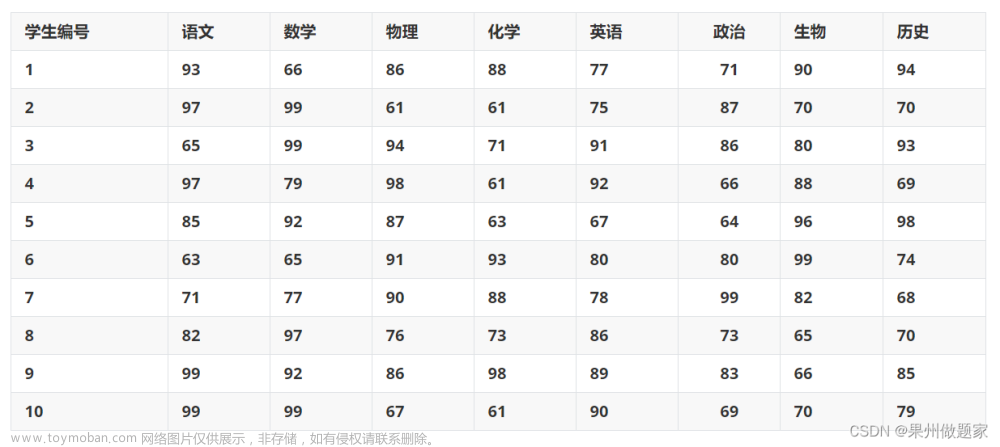
indicators = data.iloc[:, 1:]
# 计算指标的熵值
indicator_entropy = -np.sum(indicators * np.log2(indicators), axis=0)
# 计算指标的权重
weights = (1 - indicator_entropy) / np.sum(1 - indicator_entropy)
# 输出权重
for i, weight in enumerate(weights):
print(f"指标{i+1}的权重为:{weight}")
import pandas as pd
import matplotlib.pyplot as plt
# 设置字体为微软雅黑
plt.rcParams['font.family'] = 'Microsoft YaHei'
# 从Excel导入数据
data = pd.read_excel('C:/Users/26861/Desktop/eg2.xlsx')
# 根据公式计算指标值
data['score'] = 0.202*data['GDP增长标准化'] + 0.063*data['GDP标准化']+ 0.1*data['恐怖主义指数标准化'] + 0.086*data['政府预算标准化']+ 0.147*data['就业率标准化'] + 0.147*data['失业率标准化']+ 0.088*data['CPI标准化'] + 0.167*data['贸易差额标准化']
# 可视化展示
plt.figure(figsize=(8, 4))
plt.plot(data['score'])
plt.xlabel('Years')
plt.ylabel('Relative national strength')
plt.title('Changes in the relative national power of the United Kingdom over the years')
plt.xticks(rotation=45)
# 设置x轴刻度
start_year = 2013
end_year = start_year + len(data) - 1
years = range(start_year, end_year + 1)
plt.xticks(range(len(data)), years, rotation=45)
plt.yticks([]) # 隐藏y刻度
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
1.利用EXCEL快速处理数据
2.查找数据后进行建模积累了初步的经验
3.熵权法,评价方法
import pandas as pd
import numpy as np
# 从Excel导入数据
data = pd.read_excel('data.xlsx')
# 提取指标列
indicators = data.iloc[:, 1:]
# 计算指标的归一化值
normalized_indicators = indicators.apply(lambda x: (x - min(x)) / (max(x) - min(x)))
# 计算指标的熵值
entropy_values = normalized_indicators.apply(lambda x: -np.sum(x * np.log2(x)))
# 计算权重
weights = (1 - entropy_values / np.sum(entropy_values))
# 输出权重
for i, weight in enumerate(weights):
print(f"指标{i+1}的权重为:{weight}")
4.数据网站,定义、选取指标经验
5.可视化
可以修改、隐蔽两坐标轴刻度
import pandas as pd
import matplotlib.pyplot as plt
# 设置字体为微软雅黑
plt.rcParams['font.family'] = 'Microsoft YaHei'
# 从Excel导入数据
data = pd.read_excel('C:/Users/26861/Desktop/eg2.xlsx')
# 根据公式计算指标值
data['score'] = 0.202 * data['GDP增长标准化'] + 0.063 * data['GDP标准化'] + 0.1 * data['恐怖主义指数标准化'] + 0.086 * data['政府预算标准化'] + 0.147 * data['就业率标准化'] + 0.147 * data['失业率标准化'] + 0.088 * data['CPI标准化'] + 0.167 * data['贸易差额标准化']
# 可视化展示
plt.figure(figsize=(8, 4))
plt.plot(data['score'])
plt.xlabel('指标')
plt.ylabel('权值')
plt.title('各指标权值')
# 设置x轴刻度
start_year = 2013
end_year = start_year + len(data) - 1
years = range(start_year, end_year + 1)
plt.xticks(range(len(data)), years, rotation=45)
plt.yticks([]) # 隐藏y刻度
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
运行修改后的代码后,将会显示一个折线图,x轴刻度从2013年开始,并以年份为单位进行间隔。文章来源:https://www.toymoban.com/news/detail-755652.html
对y轴隐蔽刻度文章来源地址https://www.toymoban.com/news/detail-755652.html
到了这里,关于12.9建模复盘——EXCEL批量处理数据、查找数据、熵权法、可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!