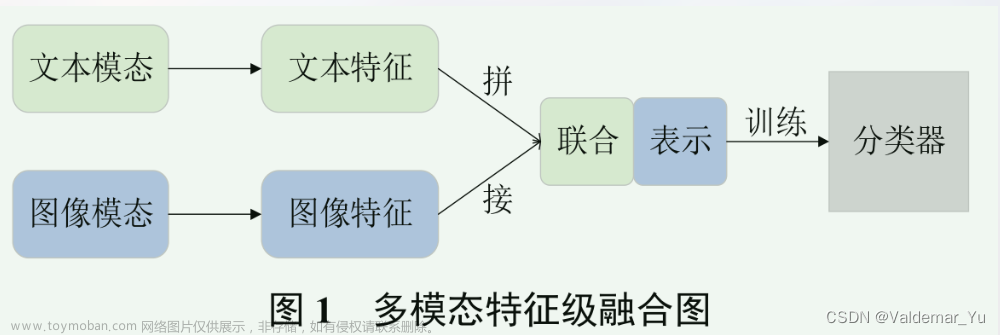
零. 背景
1. Introduction
多模态情感分析是一个活跃的研究领域,它利用多模态信号对用户生成的视频进行情感理解。解决这一任务的主要方法是开发复杂的融合技术。
(1)然而,信号的异质性造成了分布模式的差距,这带来了重大挑战。
https://blog.csdn.net/qq_40943760
2. My idea
(1)进行互注意力的特征表示学习
(2)引入预训练模块加强特征表示和特征泛化
一. MISA:多模态情感分析的模态不变和特定表示 ACMMM2020
1 Abstract
1.1 Motivation
(1)信号的异质性造成了分布模式的差距,这带来了重大挑战。
(2)在本文中,我们的目标是学习有效的模态表示来帮助融合过程。
1.2 Method
我们提出了一个新颖的框架 MISA,它将每个模态投射到两个不同的子空间。
第一个子空间是模态不变的,其中跨模态的表示学习它们的共性并减少模态差距。
第二个子空间是模态特定的,它对每个模态都是私有的,并捕获它们的特征。这些表示提供了多模态数据的整体视图,用于进行任务预测的融合。

图1 通过模态不变和特定子空间学习多模态表示。这些特征后来用于融合和随后的视频影响预测
1.3 Results
流行的情绪分析基准 MOSI 和 MOSEI 上进行的实验表明,与最先进的模型相比有显着的进步。
我们还考虑了多模态幽默检测的任务,并在最近提出的 UR_FUNNY 数据集上进行了实验。在这里,我们的模型也比强大的基线表现更好
2. Related Work
2.1 多模态情感分析
(1)Utterance-level
话语级:侧重于使用复杂的融合机制学习跨模态动力学
(2)Inter-utterance context
话语间语境:这些模型利用目标话语周围话语的上下文。设计为分层网络,它们在较低级别对单个话语进行建模,在第二级别对话语间顺序信息进行建模。
(3)Different
行·不使用上下文信息,也不关注复杂的融合机制。相反,我们强调融合前表征学习的重要性。尽管如此,如果需要,MISA 可以灵活地合并上述这些组件
2.2 多模态表示学习
(1)公共子空间表示
尝试学习跨模态公共子空间的作品可大致分为:(a)基于翻译的模型,使用序列到序列 [40]、循环翻译 [39] 和对抗性等方法将一种模态转换为另一种模态自动编码器;(b)基于相关性的模型 [50],使用典型相关分析 [3] 学习跨模态相关性;(c)使用对抗性学习等技术学习一个新的共享子空间,其中所有模态都被同时映射 [35, 37]。
(3)Different
与第三类类似,我们也学习了公共模态不变子空间。但是,我们不使用对抗性鉴别器来学习共享映射。此外,我们结合了正交模态特定的表示:一种在多模态学习任务中较少探索的特征
(2)分解表示
在子空间学习机制中,我们将注意力转向因式分解表示。虽然一项工作试图学习多模态数据的生成判别因素 [51],但我们的重点是学习模态不变和特定表示。为实现这一目标,我们从有关共享-私有表示的相关文献中汲取灵感。共享-私有 [5] 学习的起源可以在多视图组件分析 [48] 中找到。这些早期作品设计了具有单独的共享和私有潜在变量的潜在变量模型 (LVM) [9]。
(3)Different
与这些模型不同,我们的提议涉及一种判别式深度神经架构,它避免了对近似推理的需要。我们的框架与域分离网络 (DSN) [5] 密切相关,它提出了用于域适应的共享-私有模型。 DSN 在多任务文本分类等领域的类似模型的开发中具有影响力 [25]。尽管我们从 DSN 中获得灵感,但 MISA 包含关键区别:(a)与 DSN 不同,我们使用更高级的分布相似性度量——CMD(参见第 3.5 节),而不是对抗训练或 MMD;(b)我们在特定于模态的(私有)表示中合并了额外的正交损失(参见第 3.5.2 节);(c) 最后,虽然 DSN 仅使用共享表示进行任务预测,但 MISA 结合了不变和特定表示以进行融合,然后进行任务预测。
我们假设利用这两种模态表示有助于通过提供多模态数据的整体视图来帮助融合。

图2 MISA 采用话语级表示并将每个模态投射到两个子空间:模态不变和特定模态。之后,这些隐藏表示用于重建每个输入,也用于融合以进行任务预测。
3. 模型细节
3.1 模态特征表示


图3 模态特征学习,通过extract提取三个模态的特征后,会使用 3.2 节中的模态不变和模态特定的特征表示模型
3.2 模态不变和模态特定特征表示
(1)
h
m
c
\mathbf{h}_m^c
hmc 表示模态不变特征,
h
m
p
\mathbf{h}_m^p
hmp 表示模态特定特征
h
m
c
=
E
c
(
u
m
;
θ
c
)
,
h
m
p
=
E
p
(
u
m
;
θ
m
p
)
\mathbf{h}_m^c=E_c\left(\mathbf{u}_m ; \theta^c\right), \quad \mathbf{h}_m^p=E_p\left(\mathbf{u}_m ; \theta_m^p\right)
hmc=Ec(um;θc),hmp=Ep(um;θmp)

图4-1 共享编码器** E c E_c Ec** 和独立编码器** E p E_p Ep** 的代码细节,串联一层 前向传播层-Sigmoid 即可
(2) E c E_c Ec 表示跨模态的共享参数 θ c \theta^{c} θc 操作, E p E_p Ep 代表 独立模态的单独参数 $ \theta_{m}^{p}$ 操作

图4-2 贡献参数和独立参数的代码细节,额外设置一些单独的可学习变量即可
3.3 模态融合
在将模式投影到各自的表示形式后,我们将它们融合成一个联合向量,用于下游预测。我们设计了一个简单的融合机制,首先执行基于变压器[54]的自我关注,然后是所有六个转换后的模态向量的串联。
然后,我们对这些表示进行多头自我关注,使每个向量都知道其他交叉模态(和交叉子空间)表示。这样做可以让每个表征从其他表征中诱导潜在信息,这些信息对整体情感方向具有协同作用。这种跨模态匹配在最近的跨模态学习方法中非常突出。


图5 模态融合代码细节,将3.2节中学习到的6种特征表示先送入Transfomer再送入一个简单的融合层即可。模型最后的输出 o 将与对应的多个label进行loss计算(使用了四个loss进行联合方向传播)
4. 结果

图6 实验结果
5. 自己的思考
首先,这篇paper属于20年的baseline,针对负样本的学习还没有探究,这会限制模型性能。
此外,模型针对模态的不变特征表示考虑的并不深刻,其实还可以考虑不同模态之间的交互注意力。文章来源:https://www.toymoban.com/news/detail-755827.html
最后,如文章最后所说,最后的损失函数还有改进空间。文章来源地址https://www.toymoban.com/news/detail-755827.html
到了这里,关于多模态情感识别-MISA: baseline解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!