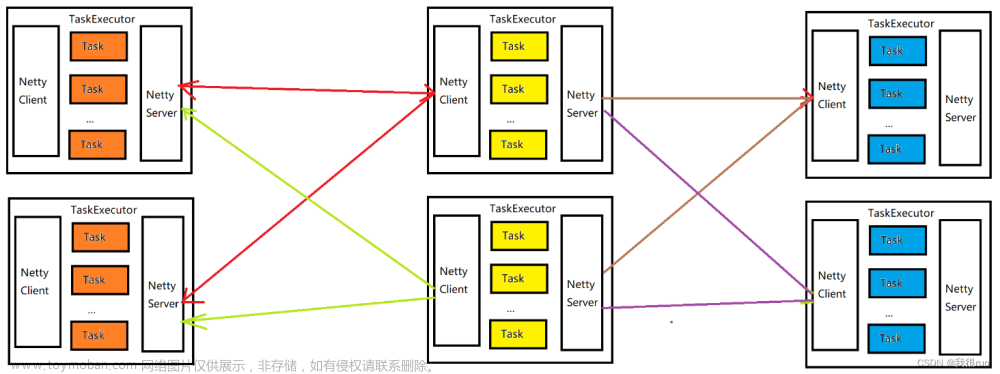
当 Task 发生故障时,Flink 可以重启出错的 Task 以及其他受到影响的 Task ,以使得作业恢复到正常执行状态。
Flink 通过重启策略和故障恢复策略来控制 Task 重启:
- 重启策略决定是否可以重启以及重启的间隔;
- 故障恢复策略决定哪些 Task 需要重启。
一. 重启策略种类(Restart Strategies)
参数 restart-strategy 定义了采取何种策略。
- 如果没有启用 checkpoint,就采用“不重启”策略。
- 如果启用了 checkpoint 且没有配置重启策略,那么就采用固定延时重启策略, 此时最大尝试重启次数由 Integer.MAX_VALUE 参数设置。
restart-strategy的种类
- none:没有重启策略 ,为默认策略
- fixed-delay:固定尝试次数重启策略
- failure-rate:失败率跟踪重启策略:这个策略会根据作业或任务的失败率以指数级递增的方式来计算重启的等待时间。
- exponential-delay:失败率跟踪重启策略,这个策略会根据作业或任务的失败率以指数级递增的方式来计算重启的等待时间。
可以通过 Flink 的配置文件 flink-conf.yaml 来设置默认的重启策略。
也可以通过编程语言动态的设置,这里使用java语法
例子:设置固定延时重启策略。
//如果发生故障,系统会重启作业 3 次,每两次连续的重启尝试之间等待 10 秒钟。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
));
1. Fixed Delay Restart Strategy
固定延时重启策略
按照给定的次数尝试重启作业,在两次连续的重试之间等待固定的时间。如果尝试超过了给定的最大次数,作业将失败。
通过在 flink-conf.yaml 中设置如下配置参数,默认启用此策略。
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
));
2. Failure Rate Restart Strategy
故障率重启策略
在故障发生之后重启作业,在两个连续的重启尝试之间等待固定的时间,当故障率(每个时间间隔发生故障的次数,也就说这个任务可以有多个这样的时间间隔)超过设定的限制时,作业最终会失败。
通过在 flink-conf.yaml 中设置如下配置参数,默认启用此策略。
# 失败率说明:五分钟内发生了超过三次故障,作业就失败。其中每次重试间隔为10秒
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
3. Fallback Restart Strategy
使用群集定义的重启策略。 这对于启用了 checkpoint 的流处理程序很有帮助。 如果没有定义其他重启策略,默认选择固定延时重启策略。
ing
4. No Restart Strategy
作业直接失败,不尝试重启。
restart-strategy: none
程序中设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
二. 故障恢复策略(Failover Strategies)
支持两种故障恢复策略:
1. (全图恢复策略)Restart All Failover Strategy
在全图重启故障恢复策略下,Task 发生故障时会重启作业中的所有 Task 进行故障恢复。
2. (基于region局部恢复策略)Restart Pipelined Region Failover Strategy
该策略会将作业中的所有 Task 划分为数个 Region。当有 Task 发生故障时,它会尝试找出进行故障恢复需要重启的最小 Region 集合。
相比于全局重启故障恢复策略,这种策略在一些场景下的故障恢复需要重启的 Task 会更少。
此处 Region 指以 Pipelined 形式进行数据交换的 Task 集合。(ing)
- DataStream 和 流式 Table/SQL 作业的所有数据交换都是 Pipelined 形式的。
- 批处理式 Table/SQL 作业的所有数据交换默认都是 Batch 形式的。
- DataSet 作业中的数据交换形式会根据 ExecutionConfig 中配置的 ExecutionMode 决定。
需要重启的 Region 的判断逻辑如下:
- 出错 Task 所在 Region 需要重启。
- 如果要重启的 Region 需要消费的数据有部分无法访问(丢失或损坏),产出该部分数据的 Region 也需要重启。
- 需要重启的 Region 的下游 Region 也需要重启。这是出于保障数据一致性的考虑,因为一些非确定性的计算或者分发会导致同一个 Result Partition 每次产生时包含的数据都不相同。
三. 各重启策略的适用场景
1. 失败率重启策略适用场景
1.1. 流式数据处理应用程序:
流式任务的数据源可能不稳定,这里指发生的时间不稳定,任务可能会由于输入数据的异常或负载波动而失败。当情况发生时,需要允许故障的发生,且在需要(可能发生多次)的时候进行有限次的重试,以保证任务运行的连续性。
失败率重启策略允许在一定时间窗口内容忍一定的任务失败,同时限制了过于频繁的重启,有助于稳定应用程序的运行。
1.2. 应用程序容忍性要求较低
在某些情况下,容忍任务失败可能不是首要任务,而是为了确保整个作业继续运行。Failure Rate 重启策略可以用于实现一定程度的容错,同时不会过于频繁地中断整个作业。
比如做大屏展示,要求每5分钟展示某些指标的聚合情况,这种任务有几个窗口的数据丢失影响不大,重点是持续运行。
1.3. 需要自适应容错性的任务
Failure Rate 重启策略还可以用于实现自适应容错性。当系统负载增加时,可能会增加失败率。通过动态调整失败率阈值,可以使系统在负载较高时更宽容,降低重启频率,从而提高整体性能。
1.4. 可配置性
Failure Rate 重启策略具有很高的可配置性,你可以根据具体应用程序和环境进行调整和配置,以确保达到期望的容错行为。
比如实时任务中的窗口聚合,可以根据窗口大小去设置失败率阈值、时间窗口和最大重试次数等参数,以满足应用程序的需求。
2. 固定延迟重启策略适用场景
2.1. 失败要求较为严格的任务
2.2. 任务执行时间可控(比如离线任务)
如果你的任务的执行时间相对较短且可预测,那么固定延迟重启策略更容易实现,因为你可以合理地估计任务需要的时间,以确定重启的延迟。
3. 无策略使用场景
适用于那些对于任何任务失败都不允许的应用程序。文章来源:https://www.toymoban.com/news/detail-756143.html
参考:
Task 故障恢复文章来源地址https://www.toymoban.com/news/detail-756143.html
到了这里,关于【flink】Task 故障恢复详解以及各重启策略适用场景说明的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!