前言
哈希查找(Hash Search)是一种基于哈希表实现的数据查找算法,也可以被称为散列查找。
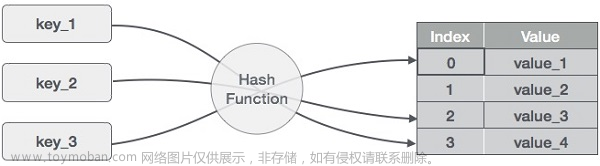
在哈希查找中,首先根据给定的键值通过哈希函数计算出对应的哈希值,然后利用该哈希值在哈希表中定位到具有相同哈希值的一个桶(Bucket),再在桶中进行线性查找和比较,以确定目标记录是否存在。若存在,则返回该记录在哈希表中存放的位置;若不存在,则说明该记录未被存储在哈希表中。
哈希表(Hash Table):
哈希表也叫散列表,是一种根据关键码值(Key-value)而直接进行访问的数据结构。通常情况下,它通过把关键码值映射到一个表中的位置来访问记录,以加快查找的速度。换句话说,哈希表就是一种以键值对作为存储基本单位的数据结构。
哈希函数(Hash Function):
哈希函数是一种将任意长度的输入(也叫“键”或“关键字”)映射到固定长度的输出(也叫“哈希值”或“散列值”的)的函数。通常情况下,哈希函数需要具有以下特点:
- 可以接受不同长度的输入,但输出长度固定。
- 对于相同的输入,必须输出相同的结果。
- 对于不同的输入,输出的哈希值应尽可能均匀地分布在整个哈希表中。
- 计算速度快、容易实现且不会出现哈希冲突(即不同的输入映射到了同一个哈希值上)等要求
目录
前言
哈希函数的构造方法
处理哈希冲突的方法
哈希查找算法实现
开放定址法处理冲突的哈希表
链地址法处理冲突的哈希表
总结
哈希函数的构造方法
哈希函数的构造方法有很多种,常见的包括以下几种:
- 直接定址法(Direct Addressing):将关键字直接作为地址使用,适用于关键字较小且连续的情况。例如对于关键字 k,哈希函数可以设置为 f(k) = a * k + b,其中 a、b 是常数。
- 数字分析法(Digital Analysis):根据关键字的分布规律来设计哈希函数,适用于数据中存在一定规律的情况。例如对于电话号码(11 位数字),可以将前三位和后两位分别乘以某个常数相加得到哈希值。
- 平方取中法(The Mid-square Method):将关键字平方后取中间几位作为哈希值,适用于关键字位数较多的情况,可增加哈希函数的随机性和分布性。
- 除留余数法(Modular division method):将关键字除以一个常数 m,取余数作为哈希值,即 f(k) = k % m。除留余数法是哈希函数设计中最常用的方法之一,容易实现且效果不错。
- 折叠法(Folding method):将关键字分割成若干段,取每段的和作为哈希地址。适用于关键字长度较长的情况。
- 随机数法(Random Number):使用随机函数生成随机数来产生哈希值,这种方法虽然能够尽可能避免哈希冲突,但也会带来效率上的问题。
哈希函数的构造方法应该根据实际情况进行选择和设计,要尽可能避免哈希冲突、保证哈希表的均匀性和稳定性,并满足计算速度快、易于实现等要求。同时需要注意的是,不同的哈希函数适用于不同类型的数据,需要根据具体数据进行选择。
处理哈希冲突的方法
哈希函数在将关键字映射到哈希表的数组下标时,可能会遇到多个不同的关键字被映射到同一个单元格的情况,即发生哈希冲突。处理哈希冲突的方法有以下几种:
- 链地址法(Chaining)也叫拉链法:将哈希表中每个单元格视为链表的头节点,所有哈希值相同的关键字放在该单元格对应链表的末尾。这种方法不会浪费空间,但需要消耗时间查找链表。
- 开放定址法(Open addressing):当哈希值发生冲突时,依次检查哈希表中下一个位置是否空闲,直到找到一个合适的位置存储该关键字。开放定址法中有几种常见的变种策略,如线性探测、二次探测和双重散列等。
- 再哈希法(Rehashing):使用另一种哈希函数再次计算冲突的关键字的哈希值,并重新安排其在哈希表中的存储位置。这样可以分摊哈希冲突,并减少链表长度。但是,此方式的代价较大,因为需要对数据结构进行重新哈希操作。

根据实际应用场景选择适当的哈希冲突解决方案,可以提高哈希表的查询效率和空间利用率。
哈希查找算法实现
哈希查找流程主要包括建立哈希表、插入数据、查找数据和删除数据这几个步骤。其中,哈希函数的设计和冲突处理方法的选择是实现哈希查找算法时的关键。
具体实现流程如下:
- 建立哈希表:选定合适的哈希函数、定义好哈希表及其相关属性,给哈希表分配足够的空间。
- 插入数据:将要查找的数据通过哈希函数转化为对应的哈希码,并确定在哈希表中对应的位置;进而将数据储存在该位置上。如果发生冲突,则采用相应的冲突处理方法来解决冲突,保证数据被正确储存。
- 查找数据:需要查询数据时,先通过相同的哈希函数计算出要查找的数据的哈希码,然后根据哈希码得到在哈希表中的位置。若该位置上没有数据,则说明所查找的数据不存在;否则,在该位置上遍历查找,并返回所找到的数据。
- 删除数据:删除数据时,需要先通过哈希表查找到所要删除数据的位置,并将其从哈希表中移除。同时,需要使用相应的冲突解决方法,重新整理该位置上的其他数据,以确保这些数据的正确性不受影响。
以下介绍常用的两种哈希表:
开放定址法处理冲突的哈希表
开放定址哈希表是一种基于数组实现的哈希表,可以采用线性探测、二次探测、双重散列等方式处理哈希冲突。其中,线性探测法是最简单的方法,其思路是依次访问下一个(i+1)个槽位,直到发现空闲槽位为止。
下面是使用线性探测法创建哈希表的示例代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#define NIL 0
typedef struct {
int* Table;//储存哈希节点的数组基地址
int size;//哈希表长度
}HashTable;
//初始化哈希表
HashTable* InitHashTabel(int size) {
HashTable* H = malloc(sizeof(HashTable));
H->size = size;
H->Table = (int*)malloc(sizeof(int) * size);
//将所以槽位初始化为空闲状态
while (size > 0) H->Table[--size] = NIL;
return H;
}
//哈希函数
int Hash(int data, int size) {
return data % size;//除留余数法
}
//线性探测法解决哈希冲突
int LinearProbe(HashTable* H, int data) {
int Pos = Hash(data, H->size);//通过哈希函数计算得到其哈希地址
//若当前位置被占用
while (H->Table[Pos] != NIL) {
//若已存在当前键
if (H->Table[Pos] == data) {
return Pos;//返回其位置
}
Pos = (Pos + 1) % H->size;//线性探测下一个槽位
}
return Pos;//返回空闲位置
}
//插入哈希节点
int Insert(HashTable* H, int key) {
int Pos = LinearProbe(H, key);//获取该关键字应所在位置
//判断该关键字是否在哈希表中
if (H->Table[Pos] != key) {
H->Table[Pos] = key;
return 1;//插入成功
}
return 0;//插入失败
}
//查询哈希节点
int Search(HashTable* H, int key) {
//线性探测查找key是否在哈希表中
int Pos = LinearProbe(H, key);
if (H->Table[Pos] != NIL)
return Pos;
return -1;//所查元素不存在
}
//删除哈希节点
int Delete(HashTable* H, int key) {
int Pos = Search(H, key);//查找该关键字
if (Pos != -1) {
H->Table[Pos] = NIL;//直接将槽位置空
return 1;//删除成功,返回1
}
return 0;//删除失败,返回0
}
//打印哈希表节点
void print(HashTable* H) {
for (int i = 0; i < H->size; i++) {
if (H->Table[i] == NIL)
printf("NIL ");
else printf("%d ", H->Table[i]);
}
}
int main() {
HashTable* H = InitHashTabel(10);
printf("插入元素10、34、20、13、11、2:\n");
Insert(H, 10);
Insert(H, 34);
Insert(H, 20);
Insert(H, 13);
Insert(H, 11);
Insert(H, 2);
print(H);
printf("\n删除13和20:\n");
Delete(H, 13);
Delete(H, 20);
print(H);
}运行程序初始化哈希表,进行插入、删除操作:

链地址法处理冲突的哈希表
使用链地址法处理冲突的哈希表通常被称为“散列表”(hash table)或“哈希映射”(hash map)。和开放地址法相比,链地址法能够更好地处理哈希冲突,并且不需要考虑如何重新计算哈希码。因此,在实际应用中,链地址法的散列表在很多情况下更为常见。
下面为使用无头结点链表的哈希表:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
//储存一个元素的结构体
typedef struct {
int key;
//可添加其他元素
char* value;//字符串元素
}ElementType;
//链表节点结构体
typedef struct node {
ElementType data;
struct node* next;
}Node;
//哈希表结构体
typedef struct {
Node** Table;//哈希表指针数组基地址
int Hash_size;//表长
}HashTable;
//初始化
HashTable* InitHashTable(int TableSize) {
HashTable* H = malloc(sizeof(HashTable));
H->Hash_size = TableSize;
H->Table = (Node**)malloc(sizeof(Node*) * H->Hash_size);
//初始化数组内每个指针
for (int i = 0; i < H->Hash_size; i++) {
H->Table[i] = NULL;
}
return H;
}
//哈希函数
int Hash(HashTable* H, int key) {
return key % H->Hash_size;
}
//查找
Node* Search(HashTable* H, int key) {
Node* p;
int Pos;
Pos = Hash(H, key);//计算哈希值
p = H->Table[Pos];//该关键字应在链表的基地址
//搜索该链表
while (p != NULL && p->data.key != key)
p = p->next;
return p;
}
//插入
void Insert(HashTable* H, ElementType elem) {
Node* p;
int Pos;
p = Search(H, elem.key);//查找该关键字
if (p == NULL) {
//若哈希表中不存在该关键字,头插法插入新节点。
Pos = Hash(H, elem.key);
p = (Node*)malloc(sizeof(Node));
p->data = elem;
p->next = H->Table[Pos];
H->Table[Pos] = p;
}
}
//删除
void Delete(HashTable* H, int key) {
//查找该关键字是否在哈希表中
if (Search(H, key) != NULL) {
int Pos = Hash(H, key);
Node* p1, * p2;
p1 = H->Table[Pos];
//若删除的节点为头结点
if (p1->next == NULL) {
H->Table[Pos] = NULL;
free(p1);
}
else {
while (p1->next->data.key != key)
p1 = p1->next;
p2 = p1->next;
p1->next = p2->next;
free(p2);
}
}
}
int main() {
HashTable* H = InitHashTable(10);
ElementType elem;
Node* p;
elem.key = 13;
elem.value = "^_^";
Insert(H, elem);
elem.key = 6;
elem.value = "QWQ";
Insert(H, elem);
p = Search(H, 13);
printf("%d : %s\n", p->data.key, p->data.value);
p = Search(H, 6);
printf("%d : %s\n", p->data.key, p->data.value);
Delete(H, 6);
}运行代码,插入两个元素,然后删除一个;

总结
在计算机科学领域中,哈希表是一种高效的数据结构,具有快速存储和查找数据的特点。它的应用非常广泛,可以用于字典或关联数组、缓存、数据库索引、去重、计数器等场景。
虽然哈希表看起来很简单,但要实现一个健壮且高效的哈希表并不容易。需要考虑许多因素,如哈希函数的设计、处理冲突的方法、负载因子、自动扩容等等。
同时,哈希表也有其局限性,如空间利用率较低、哈希冲突会导致性能下降、不支持顺序遍历等问题。因此,在实际应用中,我们需要根据具体情况选择最适合的数据结构。文章来源:https://www.toymoban.com/news/detail-756344.html
总之,哈希表是一种非常重要的数据结构,并在大量的计算机科学和工程应用中发挥重要作用。了解哈希表的原理和实现方式,将有助于我们更好地理解这个数据结构以及如何应用它来解决实际问题。文章来源地址https://www.toymoban.com/news/detail-756344.html
到了这里,关于C语言 哈希查找(哈希表的创建、处理冲突、查找等)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!