第1关:获取新闻url
任务描述
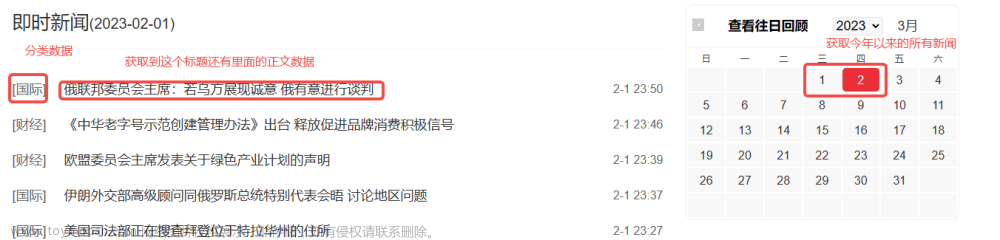
本关任务:编写一个爬虫,并使用正则表达式获取求是周刊2019年第一期的所有文章的url。详情请查看《求是》2019年第1期 。
相关知识
获取每个新闻的url有以下几个步骤:
-
首先获取
2019年第1期页面的源码,需要解决部分反爬机制; -
找到目标
url所在位置,观察其特征; -
编写正则表达式,获取目标数据。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码,使用正则表达式获取求是周刊2019年第一期的所有文章的url,返回的是一个包含所有url的列表。
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
预期输出:
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123924154.htmhttp://www.qstheory.cn/dukan/qs/2018-12/31/c_1123923896.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923886.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923852.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923828.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923817.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923778.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923740.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923715.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923686.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922609.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922550.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922484.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922467.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922434.htmhttp://www.qstheory.cn/dukan/qs/2019-01/01/c_1123924169.htm
开始你的任务吧,祝你成功!
此题需要用到正则表达式,以及soup中获取属性的函数get('href')
上代码:文章来源:https://www.toymoban.com/news/detail-756547.html
import requests
import bs4
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76'
}
def geturls():
# ********** Begin ********** #
responde = requests.get(f'http://www.qstheory.cn/dukan/qs/2014/2019-01/01/c_1123924172.htm')
responde.encoding ='utf-8'
content = responde.text
soup = bs4.BeautifulSoup(content,'html.parser')
all_a = soup.find_all('a')
urls = []
for a in all_a:
if re.findall(r'\w*dukan\w*', a.get('href')) and '1123932149' not in str(a.get('href')):
urls.append(a.get('href'))
# ********** End ********** #
return urls
if __name__ == "__main__":
urls = geturls()
for x in urls:
print(x)第2关:获取文章内容
任务描述
本关任务:编写一个爬虫,请求上一关获取的每个url,获取每篇文章的标题、作者、正文以及文章中全部图片的完整url。
相关知识
为了完成本关任务,你需要掌握xpath的基本使用。
选取节点:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore。注:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
编程要求
根据提示,在右侧编辑器Begin...End中补充代码,请求上一关获取的每个url,将每篇文章的标题、作者、正文以及文章中全部图片的完整url,并按照以下格式保存:
。。。。。。
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
在代码中我使用了xpath的查询语句和BeautifulSoup,感觉混合使用比较方便哈哈哈,还是功夫不到家。
上代码:
import requests
import bs4
import re
from lxml import etree
def parsepage(urls):
mainbody = []
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76'
}
for url in urls:
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = bs4.BeautifulSoup(response.text,'html.parser')
tree = etree.HTML(response.text)
# 获取图片的url
img_urls = tree.xpath('//div[@class="highlight"]//img/@src')
# 获取标题并去除首尾空格
title = tree.xpath('//h1/text()')[0].strip()
# 获取作者并去除首尾空格
author = tree.xpath('//span[@class="appellation"]/text()')[1].strip()[3:]
#获取正文内容
content_t =''
for p in soup.find_all('p'):
content_t += p.text.strip()
#保存提取的信息
mainbody.append({
'title': title,
'author': author,
'content': content_t,
'imgurl': img_urls
})
return mainbody都看到这里了,点个赞不过分吧( •̀ ω •́ )✧文章来源地址https://www.toymoban.com/news/detail-756547.html
到了这里,关于Python应用-爬虫实战-求是网周刊文章爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!