回顾上一篇博客,我们已经成功地训练了我们的模型,并将其保存下来。这是一个重要的里程碑,因为训练好的模型是我们进行文本生成的基础。
现在,接下来的步骤是加载这个训练好的模型,然后使用它来生成古诗。
本章的内容属于文本生成阶段。在这一阶段,我将详细介绍古诗生成的代码实现。这部分是项目中非常激动人心的一环,因为我们将看到我们的模型如何利用先前学习的知识来创造出新的古诗文本。让我们一起深入探索古诗生成的过程,并理解背后的技术细节。

[1] 开始生成
生成的代码仍然和模型训练很相像,只是在文本生成时需要额外写些代码。整体代码如下:
def create_trainer(wrapper):
# 分词器, 模型
model = wrapper.model
args = TrainingArguments(
'./checkpoints', # 模型保存的输出目录
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
)
trainer = Trainer(
model,
args
)
return trainer
def softmax( f ):
# 坏的实现: 数值问题
return np.exp(f) / np.sum(np.exp(f))
def main():
# ##
# @通用配置
# ##
with open('config.yaml', 'r', encoding='utf-8') as f:
conf = yaml.load(f.read(), Loader=yaml.FullLoader)
conf_pre = conf['pre']
conf_sys = conf['sys']
# 系统设置初始化
System(conf_sys).init_system()
# 初始化任务加载器
Task = TASKS[conf_pre['task_name']]()
data = Task.get_train_examples(conf_pre['dataset_url'])
# 初始化数据预处理器
Processor = PROCESSORS[conf_pre['task_name']](data, conf_pre['max_seq_len'], conf_pre['vocab_path'])
tokenizer = lambda text: Processor.tokenizer(text, add_end=False)
vocab = Processor.vocab
# 初始化模型包装配置
wrapper_config = WrapperConfig(
tokenizer=tokenizer,
max_seq_len=conf_pre['max_seq_len'],
vocab_num=len(Processor.vocab),
word2vec_path=conf_pre['word2vec_path']
)
x = import_module(f'main.model.{conf_pre["model_name"]}')
wrapper = NNModelWrapper(wrapper_config, x.Model)
trainer = create_trainer(wrapper)
wrapper.model.load_state_dict(torch.load(conf_pre['model_save_dir'] + conf_pre['task_name'] + '/' + conf_pre['model_name'] + '/' + 'pytorch_model.bin', map_location=torch.device('cpu')))
poem = '天'
l = len(poem)
for i in range(l, 32):
test_data = Task.get_single_examples(poem)
test_dataset = wrapper.generate_dataset(test_data, labeled=False)
output = trainer.predict(test_dataset=test_dataset)[0][0]
# 逐字生成
pred = output[i]
pred = softmax(pred)
pred /= np.sum(pred)
sample = np.random.choice(np.arange(len(pred)), p=pred)
# sample = np.argmax(pred)
if sample > len(vocab):
new_word = ' '
else:
# vocab通过键查找key
new_word = vocab[sample]
poem += new_word
print(poem)
在这部分内容中,我们将探讨如何使用预训练的模型来生成文本,例如古诗。整个过程包括以下步骤:
* 从config.yaml文件中加载配置。
* 初始化系统设置和任务加载器task。
* 加载数据并初始化数据预处理器processor。
* 创建模型包装配置WrapperConfig。
* 动态加载模型类并创建NNModelWrapper实例。
* 创建训练器trainer,用于预测。
* 加载预训练的模型权重。
* 生成文本:从初始文本(例如“天”)开始,逐字生成新的文本,直到达到指定长度(如32个字符)。
在文本生成部分,关键步骤包括:
* 使用模型预测下一个字符的概率分布。
* 应用softmax函数得到标准化的概率分布。
* 从概率分布中随机抽取下一个字符(或选择概率最高的字符)。
* 将新字符添加到现有文本中,并重复上述过程。
[2] 生成模式
在古诗生成的过程中,我们可以采用几种不同的生成模式:
1. 补词生成:输入古诗的前几个字,然后让模型补齐剩余部分。
2. 无词生成:不输入任何前缀,直接让模型生成完整的古诗。
3. 藏头诗:输入四个字ABCD,手动在第1、9、17、25个位置赋值A、B、C、D,其余部分由模型生成。
[3] 展望
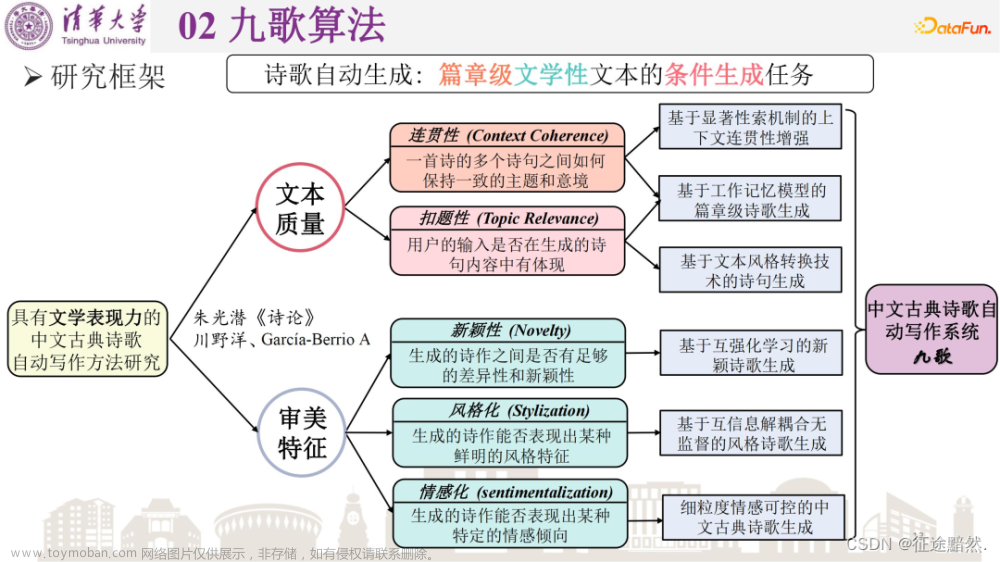
在评价生成的古诗质量时,我们需要考虑以下几个关键因素:
· 语境连贯(Context Coherence):生成的文本应逻辑上与上下文相符,并贯穿始终保持一致性。
· 主题相关(Topic Relevance):内容应与预定的主题或主旨相关。
· 新颖性(Novelty):文本应引入新颖、创造性或创新元素。
· 风格化(Stylization):文本应展示特定的风格或审美质量。
· 情感化(Sentimentalization):文本应有效且恰当地表达情感。
高质量的文本生成,尤其是在诗歌这样的创意领域,不仅仅是串联词语那么简单。它必须在语境连贯、主题相关、创新性、风格和情感深度等多个层面上产生共鸣。文章来源:https://www.toymoban.com/news/detail-756715.html
本实战项目只提供了基础的古诗生成功能,在以上这些注意点上并没有过多探究。如果想更进一步研究和提升生成文本的质量,可以参考相关的学术论文进行深入研究。文章来源地址https://www.toymoban.com/news/detail-756715.html
到了这里,关于【古诗生成AI实战】之五——加载模型进行古诗生成的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[AI绘图教程]stable-diffusion webui加载模型与插件. 实战AI绘画](https://imgs.yssmx.com/Uploads/2024/01/407805-1.png)