kinship矩阵 和 IBS矩阵
亲缘关系矩阵(kinship matrix)和同源性矩阵(IBS matrix)是基于遗传数据计算得到的两种矩阵,用于描述个体之间的亲缘关系和遗传相似度。

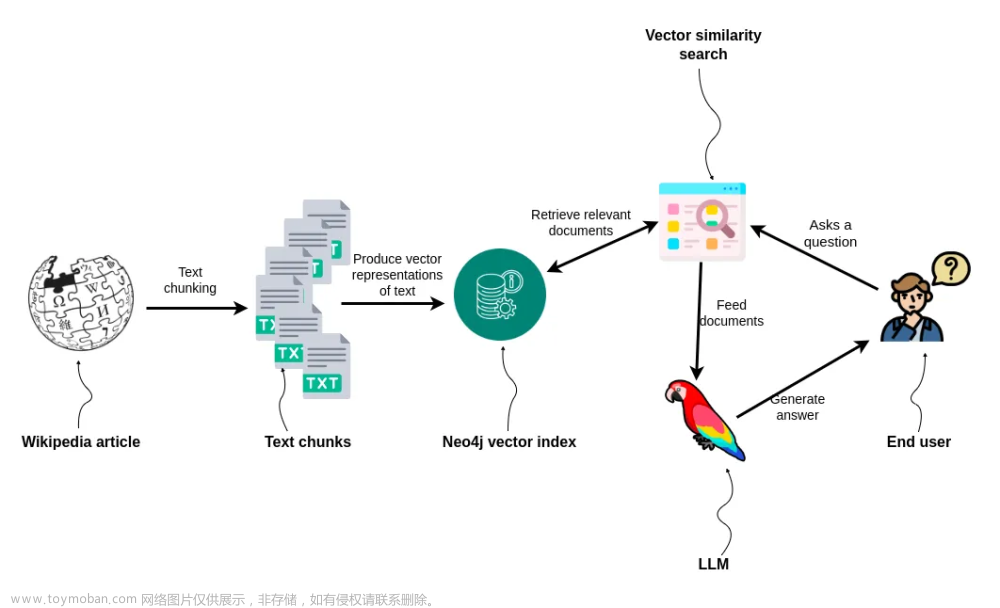
重测序数据发掘亲缘关系
构建基于重测序数据的亲缘关系矩阵(kinship matrix)和同源性矩阵(IBS matrix)是基因组学研究中常见的任务之一,下面介绍操作方法:
读取重测序数据
您可以使用 read.table() 或 readr::read_tsv() 函数从文件中读取数据,并将其存储为数据框。
library(readr)
seq_data <- read_tsv("path/to/sequencing/data/file.tsv")
过滤和清理数据
您需要根据自己的研究问题和目标样本集合,选择适当的过滤和清理策略来处理重测序数据。例如,去除缺失位点、低覆盖度位点或过滤掉与疾病相关的位点等。
# 假设要去除缺失位点和低覆盖度位点
filtered_data <- seq_data[complete.cases(seq_data), ]
filtered_data <- filtered_data[filtered_data$Coverage > 10, ]
计算杂合率
杂合率是指在某个位点上两个等位基因的频率之和,通常用于估计个体的基因型质量。您可以使用 VCFtools 或其他软件包计算杂合率并将其添加到数据框中。
# 假设杂合率的列名为 "HetRate"
filtered_data$HetRate <- calculate_heterozygosity(filtered_data)
计算亲缘关系矩阵和同源性矩阵
在 R 中,您可以使用 snpStats 或 GenABEL 包中的函数来计算亲缘关系矩阵和同源性矩阵。您需要提供一个包含所有样本的基因型信息的矩阵对象,并指定矩阵的类型(例如,二倍体或多倍体)和计算方法(例如,经典MLE或EM-REML)。
library(snpStats)
geno_matrix <- read.plink("path/to/genotype/data/file")
ibs_matrix <- ibs(geno_matrix)
kinship_matrix <- ibs2kin(ibs_matrix, type = "RR", Nind = ncol(geno_matrix))
可视化结果
您可以使用 ggplot2 或其他可视化软件包来可视化亲缘关系矩阵和同源性矩阵。例如,下面的代码使用 ggplot2 包绘制了一个基于 kinship 矩阵的 heatmap。
library(ggplot2)
kinship_df <- as.data.frame(as.matrix(kinship_matrix))
ggplot(kinship_df, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() +
scale_fill_gradient(low = "white", high = "blue") +
theme(axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank())
补充介绍
亲缘关系矩阵衡量了不同个体之间亲缘关系的程度,通常使用 Pearson 相关系数或 Euclidean 距离来表示。亲缘关系矩阵的对角线元素为 1,表示每个个体与自己的亲缘关系是最近的。而非对角线元素的大小表示不同个体之间的亲缘关系程度,例如,越接近 1 表示越近亲。
同源性矩阵是指在某个位点上,两个个体所拥有的等位基因是否相同。同源性矩阵可以用三种方式(AA, AB, BB)表示两个个体在某个位点上的等位基因状态,其中 A 代表一个等位基因,B 代表另一个等位基因。同源性矩阵是通过计算每对个体之间在所有位点上的同源性程度得到的。
作用与应用场景
一般情况下,亲缘关系矩阵和同源性矩阵是通过重测序数据或 SNP array 数据计算得到的。对于 SNP array 数据,同源性矩阵可以直接从样本的基因型数据计算得到。而亲缘关系矩阵则需要进一步转换。亲缘关系矩阵和同源性矩阵在基因组学研究中具有重要作用。
以上内容整理并参考了Chatgpt3.5,每天分享一个生信知识点,欢迎后台提问,将优先考虑粉丝提出的问题并整理答案~文章来源:https://www.toymoban.com/news/detail-756802.html
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-756802.html
到了这里,关于每天一个小知识丨如何利用重测序数据构建kinship矩阵和IBS矩阵?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!