KafKa
首先自然是要列出Kafka官网地址啦:https://kafka.apache.org/
概述
定义
Kafka 是一个分布式的---基于发布/订阅模式的消息队列(Message Queue),主要应用于 大数据实时处理领域。
发布/订阅模式
原文链接:https://blog.csdn.net/tjvictor/article/details/5223309
定义了一种一对多的依赖关系,让多个订阅者对象同时监听某一个主题对象。这个主题对象在自身状态变化时,会通知所有订阅者对象,使它们能够自动更新自己的状态。
将一个系统分割成一系列相互协作的类有一个很不好的副作用,那就是需要维护相应对象间的一致性,这样会给维护、扩展和重用都带来不便。当一个对象的改变需要同时改变其他对象,而且它不知道具体有多少对象需要改变时,就可以使用订阅发布模式了。
观察 Kafka 的最初一些设计特性可发现以下几点内容。
- 它可以作为一个写在磁盘上的缓存来使用,或者说,并不是仅基于内存来存储流数据,它可以保证数据包不被及时消费时,依然可用且不被丢失;
- 同一话题中,数据中发布与消费等序,由于位移的存在提供了逻辑上的顺序,在同一个话题上,第一个数据比第二个数据最先被发布的时候,也可保证在消费时也是永远第一个数据比第二个数据先被消费;
- 因为 Kafka 是一个公有的大数据中转站,就是说,所有的数据只要在 Kafka 上,永远可以在 Kafka 周围进行业务的开发或者认知事物的开发。
消息队列
应用场景
MQ传统应用场景之异步处理

上述所说同步处理:
- 填写注册信息
- 注册信息写入数据库
- 调用发送短信接口
- 发送短信
- 页面响应注册成功
此5步操作成同步串执行,效率太低。
异步处理:
- 填写注册信息
- 注册信息写入数据库(同时用户已经获取到了页面响应注册成功的反馈)
- 发送短信请求道MQ,MQ自己去执行发送短信
将可以延迟处理的任务放入到消息队列中自动排序执行,保证不会丢失,但是队列也是有一定容量的,如果任务出现并发峰值,可以做到削峰。
但是如果**持续**并发请求数 >= 峰值处理容量,即便是MQ到了一定的程度也是会崩溃的。
使用的好处
当然,MQ到底有什么魔力呢?要去使用它。
-
解耦 :允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
-
可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所 以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
-
缓冲:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致 的情况。 更多的是生产>消费。
-
灵活性 & 峰值处理能力 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列 能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
-
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户 把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要 的时候再去处理它们。
将所有的容器技术核心
两种模式
一、点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。 消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
点对点模式(一对一,消费主动拉取数据,消息收到消息清除)
消息生产生产消息发送Queue中,然后消息消费者从队列中取出兵器消费的消息,队列支持存在多个消费者,但是对一个消息而言,就会有一个消费者可以消费。

二、发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消 息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。

在后面的所有的consumer中维护着一个**长轮询**队列,间隔一定的时间会去消息队列中询问是否有新消息
这种情况就可能会导致一个极端的现象会出现:
就是如果==生产者(producer)长时间不生产新的消息==
消费者(consumer)就会在规定的时间间隔内一直不断重复询问是否有新的消息出现,这个过程,这样的条件下,非常消耗资源!
发布/订阅模式也存在两种细分就是在实际运行情况下获取数据:
- 消费者主动拉取的数据:也就是当消费者定期去队列中获取数据的时候,有时是有新的数据,有时却是没有新的数据接收,也就是拉取空数据。
- 消息队列推送的数据。
点对点和发布订阅模式的区别
- 一对多:点对点也称一对一,而发布订阅模式却可以给到多个人收到,也是一对多的模式。
- 消费者消费速度自己决定:自己订阅的模式,也就是消费者的消费速度可以由自己来决定。
架构图
-
Producer:消息生产者,就是向 kafka broker 发消息的客户端; -
Consumer:消息消费者,向 kafka broker 取消息的客户端; -
Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负 责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所 有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。 -
Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。 -
Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic; -
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列; -
Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。 -
leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对 象都是 leader。 -
follower:提供备份,每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower。分布式的消息队所以需要提供高可用的架构当然leader和follower不可能在同一台机器上,在同一台机器上将数据分两次,而这台机器如果宕机,分两次的数据全部都没有,显然没有什么意义
所以,leader和follower是分在不同的机器上的,follower可以看成是副leader只是在当leader挂掉之后用于替代leader的备份作用,正常工作时生产者和消费者都是找的leader。
 如图所示:红色的圈
如图所示:红色的圈
一个分区只能被一个消费者组里面的某一个消费者所消费。
那么什么情况下并发效率最高呢?
当然就是当**分区数量 = 消费者数量**,一一对应情况才是效益最大化。
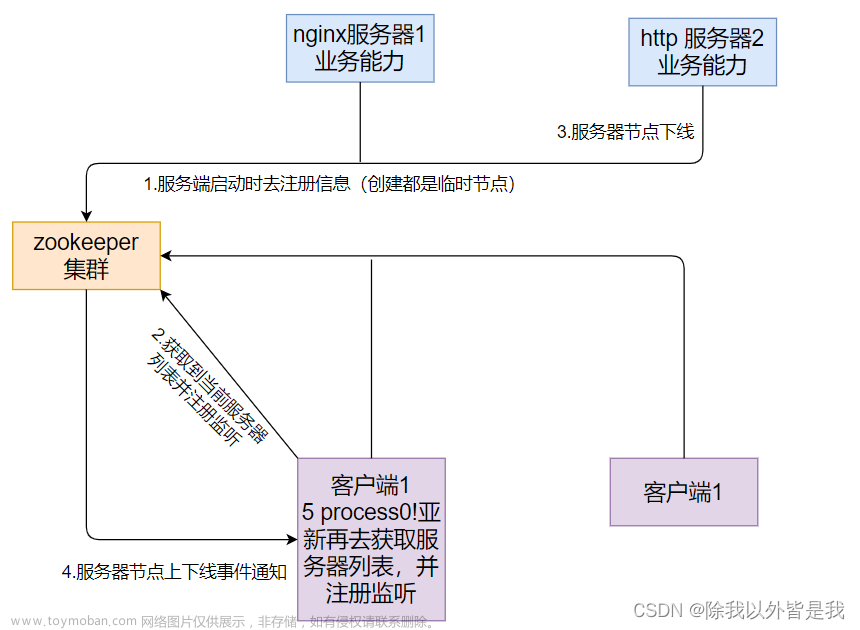
在这里架构中说是Kafka必须要依赖于Zookeeper,那么这个zookeeper做了什么呢?
-
为kafka集群存储了一些数据,例如:存储消费到的位置信息(数据被哪个消费了的记录)0.9又存回kafka某个主题(业就是上图中的Topic)之中了(存在磁盘,默认保留7天)。
其实无论存储在哪里,总而言之就是起到了一个作用:
- 记录消费位置,也就是如果突然挂掉,再重新运行可以从之前记录的消费位置开始正常执行。
流程叙述

如图所述流程:
- 生产者生产消息,到A-0通道(ProducerA 和 Consumer A二者的消息传递都会通过此通道)中(一台服务器可以容纳多个通道)
- 注意:这里有一点就是在消费者(Consumer)中:
- **同一组的消费者(Consumer)**不可以访问同一组中其它消费者与生产者所建立的单独的通道。
- 但是**其它组的消费者(Consumer)**却可以访问由本组消费者和生产者建立的通道。
- 为了保证架构的高可用,在Kafka集群中相互服务器都会存住此通道的副本(以一个Leader + Follower为例:如果在A服务器上存储的是Leader,那么在服务器B上对应的就是Follower)。相互对应,交互同步数据,以保证如果其中一台服务器宕机,另一台服务器尽可能的可以接替他的工作,以达到高可用的目的。
- Zookeeper用于达到一个目的,就是突然关机之后,再重新启动,依旧都可以找到自己运行的位置,丝毫不乱,可以保持断电前的进度,接着剩下的任务继续完成,Zookerper可以作为此架构图中的注册中心。
环境搭建
安装部署
集群规划
hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka 2.1.2 jar 包下载 http://kafka.apache.org/downloads.html
虚拟机搭建集群
centOS7位置:D:\其它\安装包\镜像\CentOS-7-x86_64-DVD-1810.iso
虚拟机搭建linux环境文档:E:\学习视频\kafka\虚拟集群环境\虚拟机安装Linux(Edge打开)
1.先启动虚拟机相关服务

注意:当设置服务类型为自动时出现拒绝访问,这里火绒的保护机制在生效:
1.对其设置相关
2.关闭火绒
Kafka3.X
官网地址:https://kafka.apache.org/
引入

前端,埋点记录用户购买当前商品的行为数据(浏览、点赞、收藏、评论等)。

当Flume采集速度 = Hadoop上传速度时,按理来说日常应该是没有什么问题的。
但假设此时双十一来临的时候,Flume采集速度 远> Hadoop的收集速度的时候,处理不了怎么办呢?
此时就提现出来Kafka的重要性,大部分时候它还是当作消息队列缓冲的作用来使用的。

Kafka概述
定义
Kafka传统定义
Kafka是一个分布式的基于==发布/订阅模式==的消息队列(Message Queue),主要应用于大数据实时处理领域。
发布/订阅;消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息
最新定义
Kafka是一个开源的**分布式事件流平台**(Event streaming Platform),被数千家公司用于高性能==数据管道、流分析、数据集成和关键任务应用==。
消息队列
传统的应用场景
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
缓冲/消峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。

解耦
解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。

假设
- 数据源是厂家:厂家有五粮液,茅台…
- 目的地是顾客:每个顾客喜好的酒的品牌不同
- 那么肯定顾客不能直接从厂家手中购买,人家也不零售
- MQ是超市:此时中间添加一个MQ(存放各种不同品牌酒的超市)
- 此时目的地(顾客)就可以从MQ(超市)中购买自己喜欢的数据(酒)
异步通信
异步通信:允许用户把一个消息放入队列,但并不立即处理它,当在需要的时候再去处理它们

其实,当用户1.填写的注册信息 2.写入到数据库了的时候就可以执行 5.注册成功了!
发送短信在后面慢慢发也可以

总结:
- 同步处理有点像死磕的道理,死板不灵活,非要等到短信发送完成之后才给页面相应成功。
- 当用户访问量比较大的时候这样的细小的死磕就真的很死了。
- 而利用消息队列异步处理则要灵活的多,响应速度也会更快。
- 异步处理就是**先将核心的事情紧要的事情先处理完毕,后续再处理那些相对并不是很重要的部分,哪怕是失败了,也不会影响核心任务的完成**。
两种模式
点对点模式
消费者主动拉取数据,消息收到后清除信息。
步骤
- producer生产数据给到MQ,MQ将其按照队列方式存储
- 然后MQ将存储的消息按照顺序发送给consumer
- consumer确认收到后发送给MQ确认收到的信号
- MQ就将已经确认发送的消息在队列中删除

发布/订阅模式
- 可以有**多个topic**主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者**相互独立,都可以消费到数据**
步骤
- producer生产数据发送给MQ
- MQ按照主题分类存储数据
- 消费者按照订阅的主题收到相关主题的数据
- 消费者也可以订阅多个不同的主题,消费者之间选择的主题可以相同,MQ不删除数据

总结
点对点模式处理的业务场景较为单一
而发布/订阅处理的模式可以适用于比较复杂的业务场景。
Kafka基础架构
多个分区
- 为了方便扩展,并提高吞吐量,一个topic分为多个partition(分区)
并行消费
- 配合分区的设计,提出消费组的概念,组内每个消费者并行消费。

注意:一个分区(TopicA)内的数据,只允许一个分组(group)中一个消费者(Consumer)消费。
此时考虑一个问题,一个分区内的数据只允许一个分组中的特定的消费者消费,那么当前分区要是挂掉了呢?怎么办?还怎么消费?
增加副本
- 为了提高可用性,为每个partition增加若干副本,类似NameNode HA

那么既然要新增副本,是为了应对kafka当前分区中挂掉的时候,那么副本与当前分区之间的关系是怎么样的呢?
当前分区是怎么起作用的呢?
Kafka是这么定义的:
- 当前分区:leader 平时Consumer消费的数据都是从leader中获取,生产者生产的数据也是由leader接收
- 当前分区的副本:follower 平时就是复制leader中的数据,备份使用。
假设:此时当前分区leader挂掉了
此时对应的follower可以晋升为leader,代替当前分区继续执行其职责。
Kafka还有一部分数据是存储在Zookeeper中的
-
记录集群中哪个服务器上线了,正在工作,只要工作在相关节点上就有记录
/brokers/ids/[0,1,2]
-
记录服务器节点运行的状态
-
记录每一个分区谁是leader及其相关信息
-
当然,在Kafka2.8.0之前,必须依赖于Zookeeper,但是之后则此依赖为可选,并不强制。
注意:随着Kafka的不断发展,Zookeeper逐渐成为Kafka的一个发展瓶颈,所以去Zookeeper化为大势所趋
总结图

注意:无论生产还是消费都只是针对leader而已。
Kafka快速入门
前置环境

关闭防火墙、静态IP、主机名称
关闭防火墙
#关闭防火墙
systemctl stop firewalld
#重启机器也不开启
systemctl disable firewalld
静态IP
#注意:ifcfg-ens33是默认网卡名,看个人主机配置而定
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static //static静态IP地址,dhcp动态IP地址
主机名称
#进入etc
cd etc/
#编辑hosts配置文件
vim hosts
#在文件底部追加
10.0.0.11 hadoop103
10.0.0.12 hadoop104
10.0.0.10 hadoop102
cd ..
#更新yum
yum update
集群分发脚本
scp
- scp(cecure copy) 安全拷贝
- scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
rsync
远程同步工具
- rsync 主要用于备份和镜像。具有速度快、避免复制相同内容核支持符号链接的优点。
- 区别:用rsync做文件的赋值要比scp速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
期望脚本在任何路径都可以使用
将脚本放在声明了全局环境变量的路径
echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/lihao/.local/bin:/home/lihao/bin:/opt/module/kafka/bin
sudo vim /etc/profile.d/my_env.sh
#添加如下内容
#XSYNC_HOME
export XSYNC_HOME=/home/lihao/
export PATH=$PATH:$XSYNC_HOME/bin
#记得哪怕分发也是,最后都要source一下使环境变量生效
source /etc/profile
ssh免密登录
原理

步骤
首先来到/home/lihao目录下
#查看所有隐藏文件
ls -al
#进入.ssh包下
cd .ssh/
#输入连接hadoop103
ssh-copy-id hadoop103
#第一次访问需要输入密码
123456
#再次测试
ssh hadoop103
#此时已无需密码
#退出,即可返回102
exit
返回数据:
登出
Connection to hadoop103 closed.
#继续打通104
#输入连接hadoop104
ssh-copy-id hadoop104
#记得最后自己也要打通
ssh-copy-id hadoop102
#打通104
返回
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop104's password: 输入密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop104'"
and check to make sure that only the key(s) you wanted were added.
#测试
ssh hadoop104
#连接成功
#查看密钥
cat authorized_keys
至此想要从103对102和104也配置免密登录
ssh-keygen -t rsa
#三个回车
ssh-copy-id hadoop102
#第一次输入密码
#测试是否需要密码
ssh hadoop102
#测试成功无需密码
#退出返回
exit
#继续104
ssh-copy-id hadoop104
#输入密码
#exit
ssh hadoop104
#测试免密成功
#返回
exit
#自己来一下
ssh-copy-id hadoop103
#输入
yes
#输入密码
测试即可
104也是如此
最终测试
在hadoop102上使用xsync分发文件
#在home新建一个a.txt文件
cd home/
#新建a.txt
Jdk1.8
长久还是根据下面步骤,此方法虽然简单无需配置环境变量,但是不能自定义安装目录反而不好
安装之前先检查一下系统有没有自带open-jdk
命令:
rpm -qa |grep java
rpm -qa |grep jdk
rpm -qa |grep gcj
如果没有输入信息表示没有安装。
#如果安装可以使用
#批量卸载所有带有Java的文件,这句命令的关键字是java
rpm -qa | grep java | xargs rpm -e --nodeps
#首先检索包含java的列表
yum list java*
#检索1.8的列表
yum list java-1.8*
#安装1.8.0的所有文件
yum install java-1.8.0-openjdk* -y
#使用命令检查是否安装成功
java -version
到此安装结束了。这样安装有一个好处就是不需要对path进行设置,自动就设置好了
官网下载
#将官网下载的安装包放入到software目录下,然后解压目录
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/module/
#配置环境变量
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_321
export PATH=$PATH:$JAVA_HOME/bin
#source 一下/etc/profile 文件,让新的环境变量 PATH 生效
source /etc/profile
#分发解压安装目录
xsync /opt/module/jdk1.8.0_321/
#分发环境变量文件
vim /etc/profile.d/my_env.sh
#记得全部要source一下使生效
Hadoop
安装
下载
#1.进入目录
cd /opt/software/
#2.将安装包放入此目录下
安装包在E:\学习视频\Hadoop\hadoop-3.1.3.tar.gz
#3.解压到module下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
#4.查看是否解压成功
ls /opt/module/hadoop-3.1.3
#返回目录信息解压成功
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
#5.添加环境变量
#5.1获取Hadoop安装路径
pwd
/opt/module/hadoop-3.1.3
#5.2打开/etc/profile.d/my_env.sh 文件
sudo vim /etc/profile.d/my_env.sh
#5.3粘贴环境变量到文件末尾(shift + g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#5.4保存并退出
esc + :wq
#5.5分发刚刚配置环境文件
xsync /etc/profile.d/my_env.sh
#5.6使修改后的文件生效(每一台机器)
source /etc/profile
#可选步骤,当hadoop命令不能用的时候
#重启(如果 Hadoop 命令不能用再重启虚拟机)
sudo reboot
配置文件
集群部署规划 注意: ➢ NameNode 和 SecondaryNameNode 不要安装在同一台服务器 ➢ ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在 同一台机器上。

Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认 配置值时,才需要修改自定义配置文件,更改相应属性值。

自定义配置文件: core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
1.配置core-site.xml
#进入配置文件目录
cd $HADOOP_HOME/etc/hadoop
#编辑配置文件
vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>lihao</value>
</property>
</configuration>
2.配置 hdfs-site.xml
#编辑配置文件
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
3.配置 yarn-site.xml
#编辑配置文件
vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
4.配置 mapred-site.xml
#编辑配置文件
vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.集群分发
#1.分发上述配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
#出现错误
does not exists!
#没有将安装后的hadoop分发出去
xsync /opt/module/hadoop3.1.3 /opt/module/
#继续分发1
#2.在103和104查看分发情况
[root@hadoop103 hadoop]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[root@hadoop104 hadoop]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
6.群起集群
#编辑配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
#文件修改为(内容不允许有空格,不允许有换行)
hadoop102
hadoop103
hadoop104
#分发同步所有配置文件
xsync /opt/module/hadoop-3.1.3/etc/
如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode
(注意:格式 化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找 不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停 止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式 化。)

错误
/etc/java
ERROR: JAVA_HOME is not set and could not be found.
#查看java安装环境
rpm-qa|grep java
#强制卸载
rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch
rpm -e --nodeps tzdata-java-2022a-1.el7.noarch
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.322.b06-1.el7_9.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
rpm -e --nodeps java-1.8.0-openjdk-accessibility-1.8.0.322.b06-1.el7_9.x86_64
rpm -e --nodeps java-1.8.0-openjdk-src-1.8.0.322.b06-1.el7_9.x86_64
rpm -e --nodeps java-1.8.0-openjdk-javadoc-zip-1.8.0.322.b06-1.el7_9.noarch
rpm -e --nodeps java-1.8.0-openjdk-demo-1.8.0.322.b06-1.el7_9.x86_64
rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch
rpm -e --nodeps java-atk-wrapper-0.30.4-5.el7.x86_64
jdk-8u212-linuxx64.tar.gz
#将官网下载的安装包放入到software目录下,然后解压目录
tar -zxvf jdk-8u321-linux-aarch64.tar.gz -C /opt/module/
#启动
[root@hadoop104 hadoop-3.1.3]# sbin/start-dfs.sh
ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ER
在Hadoop安装目录下找到sbin文件夹
在里面修改四个文件
[root@hadoop102 sbin]# vim start-dfs.sh
[root@hadoop102 sbin]# vim stop-dfs.sh
[root@hadoop102 sbin]# vim start-yarn.sh
[root@hadoop102 sbin]# vim stop-yarn.sh
1.对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2.对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.重启测试
[root@hadoop104 hadoop-3.1.3]# sbin/start-dfs.sh
Error: could not find libjava.so
Error: Could not find Java SE Runtime Environment.
#编辑环境变量修改配置
vim /etc/profile.d/my_env.sh
#找到错误,将java环境变量配置替换为此四条命令
export JAVA_HOME=/opt/module/jdk1.8.0_321
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#最后sudo一下使得配置文件生效(不可分发)
source /etc/profile
#修改配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
#添加
export JAVA_HOME=/opt/module/jdk1.8.0_321
ZooKeeper
安装
将zk安装包放入的opt/software包中
#1.注意:是带bin的
apache-zookeeper-3.5.7-bin.tar.gz
#2.解压到指定路径/opt/module/中
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
#3.到解压安装路径/opt/module/中更改名称
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
#4.进入到conf目录下,将zoo_sample.cfg更改名称
mv zoo_sample.cfg zoo.cfg
修改配置
#在zookeeper-3.5.7包下mkdir一个zkData用于存储zk相关数据
cd /opt/module/zookeeper-3.5.7
mkdir zkData
#此时在zk安装目录下的conf包下
vim zoo.cfg
#修改数据存储路径
dataDir=/opt/module/zookeeper-3.5.7/zkData
启动测试
1.先启动服务端
#在zookeeper-3.5.7解压安装目录下
./bin/zkServer.sh start
#输入jps其中QuorumPeerMain就是,不放心则看一下全名
jps
返回数据:
23848 Jps
23817 QuorumPeerMain
#查看进程全名
jps -l
返回数据:
23859 sun.tools.jps.Jps
23817 org.apache.zookeeper.server.quorum.QuorumPeerMain
2.启动客户端
#在zookeeper-3.5.7解压安装目录下
#注意,启动客户端无需在后面加start命令
./bin/zkCli.sh
#查看启动是否成功
ls /
返回:
[zookeeper]
#退出命令
quit
#查看zk当前状态,同样在安装目录下
./bin/zkServer.sh status
返回:
#standalone为本地模式
Mode: standalone
#停止服务,同样的在安装目录下运行
./bin/zkServer.sh stop
返回数据:
Stopping zookeeper ... STOPPED
即正在停止
安装zk集群
如果是10台服务器,需要部署多少台Zookeeper?
除了上述一直到创建zkData步骤为止,前面的步骤都是一样的
- 创建zkData在zookeeper-3.5.7目录下。
- 在zkData目录下创建一个myid文件
vi myid
#相当于唯一的身份标识符
#由于在102服务器上写,即写入0即可
#102 ——> 0
#103 ——> 1
#104 ——> 2
#注意上下左右都不要有空格和换行
0
拷贝配置好的zookeeper到其它机器上
#xsync为同步分发脚本
/home/lihao/bin/xsync zookeeper-3.5.7/
#同步将zkData中myid配置按照上述逐个修改内容
vim myid
上述配置都已经修改完毕后,在102服务器下要在zoo.cfg文件增加如下配置信息
#在zk安装目录下的config包下
vim zoo.cfg
#######################cluster######################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888

配置参数解读
server.A=B:C:D
-
A表示一个数字(第几号服务器),也就是上述myid中写入的数字标识符
集群模式下配置文件myid,zookeeper启动时读取此文件
拿到里面的标识符(数据)与zoo.cfg里面的配置信息对比
从而判断到底哪个是server
-
B是这个服务器的地址
-
C是服务器Follower与集群的Leader服务器交换信息的端口
-
D是万一集群中的Leader服务器挂掉了,需要一个端口重新进行选举,选出一个新的Leader服务器
别忘了最后还需要将此配置分发给其它服务器
/home/lihao/bin/xsync zoo.cfg
错误:权限不够
#进入到脚本包下
cd /home/lihao/bin
#在当前目录下为.sh的所有脚本增加权限
chmod u+x *.sh
最终进入到103和104服务器中查看对应位置的zoo.cfg文件是否有全部修改对应
启动zk集群
在102下的安装目录(zookeeper-3.5.7)下
先启动服务端
bin/zkServer.sh start
查看zk状态
bin/zkServer.sh status
#返回
Error contacting service. It is probably not running.
启动失败原因,因为这是一个集群,单台启动,启动数没有超过半数
此时就不会选出对应的leader
集群就没法工作
总结:也就是说必须要超过半数以上的服务器是好的,才能正常工作
来到103安装目录下启动
bin/zkServer.sh start
#启动完成后查看状态显示103为leader
启动停止脚本
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ------------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
}
;;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ------------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
}
;;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ------------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
}
;;
esac
安装部署
集群规划
分为三台
| 服务器名称 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 安装 | Zookeeper | Zookeeper | Zookeeper |
| 安装 | Kafka | Kafka | Kafka |
下载地址
Kafka官网下载地址:https://kafka.apache.org/downloads

Kafka的代码是由两种语言来编写的
producer(Java) ——> breaker(Scala) ——> comsumer(Java)
其实区别就是在于中间breaker中编写的Scala版本区别为2.12与2.13
集群环境
虚拟机集群环境搭建
新建虚拟机
- 打开vmware
- 文件——>新建虚拟机
- 典型
- 稍后安装操作系统




注意:多个虚拟机文件要以文件夹分开放

编辑虚拟机配置

定义镜像放置的位置

最终:网络进去再配

开启此虚拟机

安装过程中使用中文好了

网络打开


根据需要是否需要创建用户,默认不创建登录root用户
等待完成重启

重启进入root用户
输入账号密码登录

修改配置
原文链接:https://blog.csdn.net/weixin_42275702/article/details/112604912
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#注意:ifcfg-ens33是默认网卡名,看个人主机配置而定
修改配置

实际配置

注意:最下面的DNS1中的1是数字可配置多个

注意:UUID这一行不删除在克隆的时候会重复。
#博文中的参考配置
TYPE=Ethernet
BOOTPROTO=static //static静态IP地址,dhcp动态IP地址
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=34bbe4fa-f0b9-4ced-828a-f7f7e1094e4a//记得这一行要删除
DEVICE=eno16777736
ONBOOT=yes //将ONBOOT="no"改为ONBOOT="yes",开启网卡自动连接
PEERDNS=yes
PEERROUTES=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPADDR=192.168.179.3 //ip地址
NETMASK=255.255.255.0 //子网掩码
GATEWAY=192.168.179.2 //网关
DNS1=8.8.8.8 //修改DNS服务器
重启网卡使配置生效
systemctl restart network
#ping百度测试一下
ping www.baidu.com
#Ctrl + c结束
集群中只有IPADDR不同分别为
#hadoop102
IPADDR=10.0.0.10
#hadoop103
IPADDR=10.0.0.11
#hadoop104
IPADDR=10.0.0.12
三台都ping测试一下,至此虚拟机集群配置完毕
Kafka安装
安装
#安装包放置目录
cd /opt/software/
1.放入kafka安装包版本
kafka_2.12-3.0.0.tgz
2.解压
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
#进入/opt/module/解压后的目录
cd /opt/module
#修改一下目录名称,改为为kafka
mv kafka_2.12-3.0.0/ kafka
#进入此目录(此为安装解压目录)
cd kafka
#查看一下当前目录
pwd
/opt/module/kafka
目录结构
bin
查看bin中配置信息
#其中包含kafka的各种脚本
cd bin/

kafka对应三个模块
- producer
- topics
- consumer
结论
- 以后在编写代码时
- 存在多个模块
- 每一个模块就对应一个配置信息和脚本
- 这样管理起来更加方便容易一些
config
conf || etc || config 类似这样命名的文件夹里面一般都是存储着配置信息。

包含消费者生产者和服务端的三个配置文件
libs
通常此目录中都是引入的第三方jar包
licenses + site-docs
接下来的注意事项和一些文档,并不是很重要
配置kafka集群
步骤
1.进入kafka解压安装目录,config中
cd kafka/config
下载vim命令
yum install -y vim*
2.启动kafka集群,修改配置
vim server.properties
3.配置信息中的三个参数修改
broker.id
#相当于整个kafka集群中的身份唯一标识
broker.id=2
说明:
- 如果在hadoop102中配置 broker.id=2
- 那么hadoop103则为 broker.id=3
- hadoop104为 broker.id=4
log.dirs
#【重要】kafka存储数据的目录位置定义
log.dirs=/tmp/kafka-logs(默认)
#存放实际数据的地方非常重要!!!
#放在自定义目录下方便管理
#在对应位置创建此目录并修改为
log.dirs=/opt/module/kafka/datas
zookeeper.connect
kafka采用目录树结构进行存储的。
#默认值为localhost
#修改为
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
注意:
- 如果不采用目录树下放一个kafka文件夹进行存储的话,那么kafka的信息就会散乱到Zookeeper中去。
- 如果后续kafka需要注销或删除的话,要手动在zookeeper中一个一个找到对应信息并删除。
#按下ESC, 输入:wq保存退出
:wq
分发
#退出到module目录下
cd module
#对kafka进行分发
xsync kafka/
完毕

环境变量
分发完毕后,一定要来到接下来两个服务器的kafka安装解压目录的config目录
将:broker.id环境修改好,三个就是0,1,2这样

配置环境变量
上面三台服务器都改完了之后设置对应的环境变量
在102上开始设置
sudo vim /etc/profile.d/my_env.sh

#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#先source一下
source /etc/profile
#再将配置文件分发到103和104上
#xsync为脚本在资料中相关脚本文件夹中存在
sudo /home/lihao/bin/xsync /etc/profile.d/my_env.sh
如果没有配置root用户对应的xsync脚本,一般此时需要输入密码

测试
查看配置是否分发成功
- 进入到hadoop103中的kafka解压安装目录的config中
- 输入命令:
sudo vim /etc/profile.d/my_env.sh
-
查看对应kafka在102中已经配置的环境是否同样存在于103的此配置中。
-
最后在103中当前config目录下source一下即可
source /etc/profile
- 104同样也source一下
启动停止
先启动ZK
如果kafka依赖于Zookeeper的话:
- 启动kafka集群之前一定要
- 先启动Zookeeper集群
来到hadoop102上的kafka解压安装的module路径下
cd /opt/module/zookeeper
bin/zkServer.sh start
然后到103和104重复此操作
启动完毕之后查看一下进程
xcall jps

此图表示启动已成功
启动kafka
采用单节点方式一个一个启动
进入hadoop102的kafka目录下
#意为:用修改后的配置覆盖原有默认的初始配置
/opt/module/kafka/bin/kafka-server-start.sh -daemon config/server.properties
#测试输入
jps

重复操作
接下来在103和104重复上述启动kafka的操作即可
最终在102输入命令检查全部
xcall jps

启动停止脚本
#当前目录
/home/lihao/bin
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo "--- 启动 $i kafka ---"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo "--- 停止 $i kafka ---"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
;;
esac
注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper 集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止, Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了。
Kafka命令行操作
主题命令行操作

查看操作主题命令参数
#在/opt/module/kafka/bin目录下输入
kafka-topics.sh
#用于连接上kafka客户端服务
--bootstrap-server <String: server to REQUIRED: The Kafka server to connect
connect to> to.
#对topic进行操作(增删改查)
--topic <String: topic> The topic to create, alter, describe
or delete. It also accepts a regular
expression, except for --create
option. Put topic name in double
quotes and use the '\' prefix to
escape regular expression symbols; e.
g. "test\.topic".
#查看整个集群中有多少个topic
--list List all available topics.
#查看某一个topic中的详情信息
--describe List details for the given topics.
#指定分区
--partitions <Integer: # of partitions> The number of partitions for the topic
being created or altered (WARNING:
If partitions are increased for a
topic that has a key, the partition
logic or ordering of the messages
will be affected). If not supplied
for create, defaults to the cluster
default.
#指定设置多少个副本
--replication-factor <Integer: The replication factor for each
replication factor> partition in the topic being
created. If not supplied, defaults
to the cluster default.
命令归纳
关于topic模块的操作命令
| 参数 | 描述 |
|---|---|
| –bootstrap-server<String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic<String: topic> | 操作的 topic 名称。 |
| –create | 创建主题。 |
| –delete | 删除主题。 |
| –alter | 修改主题。 |
| –list | 查看所有主题。 |
| –describe | 查看主题详细描述。 |
| –partitions<Integer:# of partitions> | 设置分区数。 |
| –replication-factor<Integer: replication factor> | 设置分区副本 |
| –config<String: name=value> | 更新系统默认的配置。 |
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
[2022-04-12 15:33:33,906] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
[2022-04-12 15:33:34,425] INFO Setting -D jdk.tls.rejectClientInitiatedRenegotiation=true to disable client-initiated TLS renegotiation (org.apache.zookeeper.common.X509Util)
[2022-04-12 15:33:34,541] INFO Registered signal handlers for TERM, INT, HUP (org.apache.kafka.common.utils.LoggingSignalHandler)
[2022-04-12 15:33:34,544] INFO starting (kafka.server.KafkaServer)
[2022-04-12 15:33:34,545] INFO Connecting to zookeeper on hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka (kafka.server.KafkaServer)
[2022-04-12 15:33:34,566] INFO [ZooKeeperClient Kafka server] Initializing a new session to hadoop102:2181,hadoop103:2181,hadoop104:2181. (kafka.zookeeper.ZooKeeperClient)
[2022-04-12 15:33:34,594] INFO Client environment:zookeeper.version=3.6.3--6401e4ad2087061bc6b9f80dec2d69f2e3c8660a, built on 04/08/2021 16:35 GMT (org.apache.zookeeper.ZooKeeper)
[2022-04-12 15:33:34,594] INFO Client environment:host.name=hadoop102 (org.apache.zookeeper.ZooKeeper)
[2022-04-12 15:33:34,594] INFO Client environment:java.version=1.8.0_322 (org.apache.zookeeper.ZooKeeper)
[2022-04-12 15:33:34,594] INFO Client environment:java.vendor=Red Hat, Inc. (org.apache.zookeeper.ZooKeeper)
[2022-04-12 15:33:34,594] INFO Client environment:java.home=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/jre (org.apache.zookeeper.ZooKeeper)
安装hadoop文章来源:https://www.toymoban.com/news/detail-757029.html
测试成功后,使用快照文章来源地址https://www.toymoban.com/news/detail-757029.html
到了这里,关于消息队列——kafka基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!