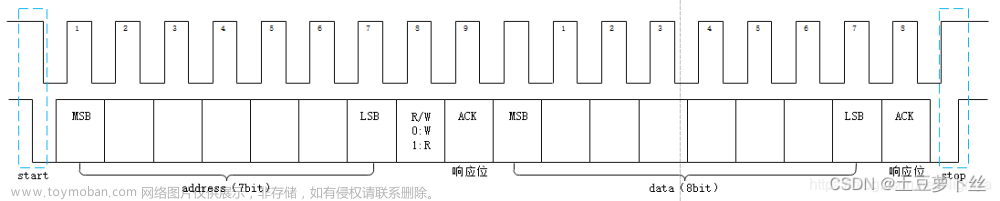
首先我们需要了解,什么是DMA?
DMA的中文名称叫做 直接内存访问 (Direct Memory Access),是一种不需要CPU参与,就能实现数据传输的技术(从一个地址空间到另一个地址空间)。也就是说,在不需要CPU插手的情况下,完成内存与外存之间的数据传输,从而CPU可以被解放出来,从事其他的工作。
在S32K3XX系列单片机的参考手册中,直接称呼为Enhanced Direct Memory Access (eDMA),显然是与传统意义上的DMA有所不同。那么,eDMA究竟是何方神圣?与普通的DMA又有什么区别呢?
1 简介
1.1 DMA系统框图
首先一起来看看S32K3XX单片机DMA系统的庐山真面目
从上图中可以看出,eDMA主要由两部分构成,一部分是 eDMA引擎,负责仲裁,控制,数据传输等工作;另一部分是传输控制描述符,存储了各个通道操作所需的属性数据,比方说,传输数据的源地址,目的地址等。整个系统设计得精巧而优雅。
eDMA引擎主要有两个功能:
地址计算
数据传输
传输控制描述符主要负责32个通道中每个通道传输控制描述符的存储。
1.2 各模块简介
Address path
- 第一通道和第二通道(抢占通道)的
TCD保存 - 管理所有主机总线的地址计算
允许一个通道在数据完成读写任务时被抢占。
当一个通道被激活的时候,它会一直运行直到小循环完成,除非被一个更高优先级的通道抢占。
当选择执行任何通道时,将从本地内存中读取其TCD的内容,并将其加载到地址路径通道x寄存器中进行正常启动,并将其加载到通道y寄存器中进行抢占启动。在小循环完成执行后,地址路径硬件将TCDn_{SADDR, DADDR, CITER}的新值写回本地内存。如果主迭代(大循环)计数耗尽,则执行额外的处理,包括最终地址指针更新,重新加载TCDn_CITER字段,以及作为分散/收集操作的一部分可能从内存中获取新的TCDn。有关详细信息,请参考动态分散/收集(Dynamic scatter/gather)部分。
Data path
这个模块实现了总线主读/写数据路径。它包含一个数据缓存和必要的复杂逻辑来支持任何需要进行的数据对齐。内部的读数据总线是主输入,内部的写数据总线是主输出。
地址和数据路径模块可直接支持两级流水式内部总线。地址路径模块代表了第一级流水式总线,数据路径模块代表了第二级流水式总线。
Program model/channel arbitration
该模块实现了eDMA编程模型的第一部分以及通道仲裁逻辑。可编程的模块寄存器与内部的外设总线相连。eDMA的外设请求输入和中断请求输出也可以通过这个模块相连。
传输控制描述符(TCD)可分成两部分:Memory controller和Memory array
Memory controller
该逻辑实现了所需的双端口控制器,并管理来自eDMA引擎的访问以及来自内部外围总线的引用。如前所述,在同步访问中,eDMA引擎被赋予优先级,外围事务被停止。
Memory arrayTCD存储的用于每个通道的传输配置文件。也就是所要执行的通道数据的各种相关信息。
1.3 特点
eDMA是一种高度可编程的数据传输引擎,可以最大限度地减少主机处理器所需的任何干预,eDMA模块具有以下特点:
-
所有的数据移动都通过双地址传输:从数据的源头读出到目标写入
— 可编程的源地址和目标地址以及传输大小
— 支持复杂地址计算 -
在最少干预主机处理器的前提下,实现了32通道的复杂数据传输。
— 内部数据buffer,被用作所有数据传输的临时存储器
— 连接到 crossbar switch,以控制总线的数据移动 -
TCD支持两层深的嵌套传输操作
— 每个通道的32字节TCD保存
— 由小字节传输计数定义的内部数据传输循环
— 由主迭代计数定义的外部数据传输循环 -
可通过三种方法让通道处于活动状态
— 直接软件初始化
— 通过连续转换中的通道连接机制进行初始化
— 每个通道一个Peripheral-paced的硬件请求 -
固定优先级和轮询通道仲裁
-
通过可编程中断请求报告通道完成情况
— 每个通道都可以独立产生中断,可以在主循环计数完成时产生断言
— 每个通道的可编程错误结果,被逻辑地加在一起形成一个中断控制器的错误中断 -
可编程支持分散/收集DMA处理
-
支持复杂数据结构
2 工作流程概述
2.1 基本工作流程
2.1.1 通道激活

本例使用eDMA外设请求信号的断言来请求通道n的服务。通过软件和TCDn_CSR[START]字段激活通道遵循与外设请求相同的基本流程(也就是说,软件和硬件的通道激活方式基本一致)。
eDMA请求输入信号在内部注册,然后通过eDMA引擎:首先通过控制模块,然后进入程序模块和通道仲裁。
在下个周期中,通道仲裁采用固定优先级和可选的循环算法进行仲裁。在仲裁执行完毕后,激活的通道号通过地址路径发送,并转换为访问TCDn本地存储器所需的地址,接下来,访问TCD内存,并从本地内存读取所需的描述符,然后将其加载到eDMA引擎地址路径的主通道或辅助通道执行寄存器中。TCD内存为64位宽,以尽量减少获取激活通道描述符并将其加载到地址路径寄存器所需的时间。
2.1.2 数据传输(数据流动)

与数据传输相关的模块(地址路径、数据路径和控制)通过所需的源读取和目标写入序列来执行实际的数据移动。源读取被启动,获取的数据被临时存储在数据路径块中,直到在目标写入期间将其传输到内部总线上。这个从源头读取/从目标写入操作一直持续到字节数(NBYTES)传输结束。
2.1.3 更新内存,申请中断

搬运NBYTES的数据后,执行基本数据流的最后阶段。在此段中,地址路径逻辑对一些TCD中的某些字段(例如,SADDR、DADDR、CITER)执行所需的更新。
如果主要迭代(大循环)计数耗尽,则执行额外的操作。这包括最后的地址调整和将BITER字段重新加载到CITER字段中。此时还会发生可选中断请求的断言,以及使用描述符中包含的scatter/gather地址指针(如果启用了scatter/gather)从内存中取出一个新的TCD。TCD内存的更新和中断请求的断言显示在上面的图中。
注:相关寄存器/字段解释
NBYTES:TCD Transfer Size
定义了每次DMA请求需要搬运的字节数
BITER:TCD Beginning Major Loop Count
通道最开始设定的主循环次数
CITER :Current Major Iteration Count
通道的当前主循环计数。每次通道完成一个服务请求并将其写回TCD内存时,它都会减少
2.2 故障报告和处理
通道错误在错误状态寄存器(CHn_CSR和TCDn_CSR)中报告,可能由以下任何一种原因引起:
- 配置错误,传输控制描述符中的某些/个设置是非法的
- 通过“ 错误取消传输”的硬件或软件请求 取消已经被激活的通道
- TCD内存错误
- 总线主机读或写周期的错误终止
而当报告配置错误时,可能由下面这些因素的状态不一致引起的:
- 起始地址或者目的地址
- 起始或目的地址偏移
- 小循环字节计数
- 传输大小
造成这些错误的原因可能源于以下几个方面:
- 地址和偏移必须与零模传输大小的边界对齐
- 小循环的计数大小必须起始和目的传输大小的整数倍
- 所有源读取和目标写入都必须配置为程序传输大小的自然边界
- 如果一个分散/收集操作在通道完成时使能,但分散/收集地址(
DLAST_SGA)没有对齐到32字节的边界,这时候就会报告配置错误。 - 如果在通道完成时使能小环路通道连接,如果
TCDn_CITER[ELINK]字段不等于TCDn_BITER[ELINK]字段,则在尝试连接时报告配置错误。
2.3 通道抢占
- 通道抢占允许在更高优先级的通道请求数据传输的时候,当前通道被挂起;
- 不支持嵌套抢占,也就是说,已经抢占的通道,不能被抢占;
- 通道的抢占被禁用时,失去了抢占功能,即使是优先级更低的通道,依然不能被抢占;
- 为了避免相互占用,可以都设置为低优先级(也就是
0)。
3 核心原理
3.1 大循环和小循环
下图显示了每个DMA请求如何启动一个小循环传输,或者迭代。DMA仲裁可在每个小循环后发生,并且允许一个级别的小循环DMA抢占。大循环中的小循环的数量由开始迭代计数(BITER)指定。
其实大循环和小循环的很多属性都可以很灵活地进行配置,详情请移步4.1小节。
3.2 eDMA仲裁机制简介
eDMA由多个优先级组成分层仲裁方案。采用固定优先级仲裁,在特定条件下也可以选择轮询仲裁。优先级顺序如下图所示:
仲裁组优先:每个通道都可以通过配置 CHn_GRPRI 寄存器来设置通道优先级,总共有32个优先级(0-31),数值越大,优先级越高。
通道优先:每个通道都可以通过配置 CHn_PRI 寄存器来设置通道优先级,总共有8个优先级(0-7),数值越大,优先级越高。
通道数(通道编号):当两个及其以上的通道有相同的仲裁组优先级和通道优先级的时候,就需要通过通道编号来区分优先级,通道编号越高,优先级越高,不可自定义。
轮询:启用轮询时,任何配置了轮询的通道操作在仲裁组中优先级最低。通过将CSR[ERCA]字段设置为1来启用轮询。启用后,通道优先级为0 (CHn_PRI=0)的通道将被使用轮询仲裁。轮循仲裁将在仲裁组中请求服务的通道(CHn_PRI=0)之间轮换通道选择。如果请求服务将在任何循环通道中被选择,仲裁组内的任何非零通道将继续使用固定优先级仲裁。
任何通道优先级大于0的通道都会在循环之前得到服务。
3.2.1 固定组仲裁,固定通道仲裁
在该模式下,eDMA从最高优先级组中最高优先级的通道中选择执行通道业务请求。如果对eDMA进行编程,使高优先级组内的通道具有大量请求或大量数据传输,则该组可能会消耗eDMA控制器的所有带宽。也就是说,如果在控制器仲裁下一个DMA请求时,在最高优先级组中的通道上总是有至少一个DMA请求待处理,则不会为低优先级组提供服务DMA请求。这种方案的优点是:通道的延迟可能很小。
3.2.2 固定组仲裁,轮询通道仲裁
请求的优先级最高的组先得到服务。如果高优先级组中不存在挂起请求,则为低优先级组提供服务。
在组内,非零通道优先级的通道优先得到服务。对于所有优先级为0的通道,优先选择通道编号较高的请求进行服务,然后一次到请求服务的最低通道。通道仲裁可以为低优先级通道提供一种公平机制。
这种方案可能引起与固定组仲裁,固定通道仲裁相同的带宽消耗问题,最高优先级组中的所有通道都将得到服务。最高优先级组上的服务延迟很短,但随着组优先级的降低,服务延迟可能会长得多。
4 相关操作
4.1 执行DMA转换
4.1.1 单次请求
比方说,我们需要传输16个字节的数据。eDMA可编程为一个大循环,每次传输16字节。在源内存有个1字节宽度的内存接口,地址为0x1000。数据终点地址为0x2000,有32位的接口。地址偏移量以增量方式编程以匹配传输大小,读取四次数据,才会写一次数据。相关配置程序如下:
TCDn_CITER = TCDn_BITER = 1
TCDn_NBYTES = 16
TCDn_SADDR = 0x1000
TCDn_SOFF = 1
TCDn_ATTR[SSIZE] = 0
TCDn_SLAST = -16
TCDn_DADDR = 0x2000
TCDn_DOFF = 4
TCDn_ATTR[DSIZE] = 2
TCDn_DLAST_SGA= –16
TCDn_CSR[INTMAJ] = 1
TCDn_CSR[START] = 1 (should be written last after all other fields have been initialized)
All other TCDn fields = 0
以上的配置,会按照如下顺序执行:
- 用户将
TCDn_CSR[START]写入数据进行通道服务请求 - 通过通道仲裁后,该通道被选择
- eDMA引擎写入:
CHn_CSR[DONE] = 0
TCDn_CSR[START] = 0
CHn_CSR[ACTIVE] = 1
-
eDMA引擎读取:从局部内存中读取通道的TCD数据到内部寄存器文件
-
从源头到终点的传输流程如下:
从0x1000、0x1001、0x1002、0x1003各读取一个字节的数据。
写32位的数据到0x2000,进行小循环第一次迭代从
0x1004、0x1005、0x1006、0x1007各读取一个字节的数据。
写32位的数据到0x2004,进行小循环第二次迭代从
0x1008、0x1009、0x100A、0x100B各读取一个字节的数据。
写32位的数据到0x2008,进行小循环第三次迭代从
0x100C、0x100D、0x100E、0x100F各读取一个字节的数据。
写32位的数据到0x200C,进行小循环第四次迭代,大循环迭代完成 -
eDMA引擎写入:
TCDn_SADDR = 0x1000,TCDn_DADDR = 0x2000,TCDn_CITER = 1 (TCDn_BITER)。 -
eDMA引擎写入:
CHn_CSR[ACTIVE] = 0,CHn_CSR[DONE] = 1,CHn_INT[INT] = 1。 -
通道退出,
eDMA进入空闲状态,或者服务下一个通道。
具体流程大致如下图所示:
4.1.2 多次请求
如果说我们需要搬运32字节的数据,这个时候就需要两次硬件请求,其他都和上述的单次请求一致。这个时候我们只需要修改主循环的次数和最后的地址偏移。变成两次主循环,每次搬运16字节数据,最后我们通过CHn_CSR[ERQ]寄存器字段使能硬件请求,可初始化从机的通道服务请求。配置如下:
TCDn_CITER = TCDn_BITER = 2
TCDn_SLAST = –32
TCDn_DLAST_SGA = –32
执行的基本流程如下:
- 第一个硬件通道请求
- 通过通道仲裁后,该通道被选择
- eDMA引擎写入:
CHn_CSR[DONE] = 0
TCDn_CSR[START] = 0
CHn_CSR[ACTIVE] = 1
-
eDMA引擎读取:从局部内存中读取通道的TCD数据到内部寄存器文件
-
从源头到终点的传输流程如下:
从0x1000、0x1001、0x1002、0x1003各读取一个字节的数据。
写32位的数据到0x2000,进行小循环第一次迭代从
0x1004、0x1005、0x1006、0x1007各读取一个字节的数据。
写32位的数据到0x2004,进行小循环第二次迭代从
0x1008、0x1009、0x100A、0x100B各读取一个字节的数据。
写32位的数据到0x2008,进行小循环第三次迭代从
0x100C、0x100D、0x100E、0x100F各读取一个字节的数据。
写32位的数据到0x200C,小循环迭代完成 -
eDMA引擎写入:
TCDn_SADDR = 0x1010,TCDn_DADDR = 0x2010,TCDn_CITER = 1。 -
eDMA引擎写入:
CHn_CSR[ACTIVE] = 0。 -
通道退出,主循环的一次迭代结束,
eDMA进入空闲状态,或者服务下一个通道。 -
第二个硬件通道请求
-
通过通道仲裁后,该通道被选择
-
eDMA引擎写入:
CHn_CSR[DONE] = 0
TCDn_CSR[START] = 0
CHn_CSR[ACTIVE] = 1
-
eDMA引擎读取:从局部内存中读取通道的TCD数据到内部寄存器文件
-
从源头到终点的传输流程如下:
从0x1010、0x1011、0x1012、0x1013各读取一个字节的数据。
写32位的数据到0x2010,进行小循环第一次迭代从
0x1014、0x1015、0x1016、0x1017各读取一个字节的数据。
写32位的数据到0x2014,进行小循环第二次迭代从
0x1018、0x1019、0x101A、0x101B各读取一个字节的数据。
写32位的数据到0x2018,进行小循环第三次迭代从
0x101C、0x101D、0x101E、0x101F各读取一个字节的数据。
写32位的数据到0x201C,进行小循环第四次迭代,大循环完成 -
eDMA引擎写入:
TCDn_SADDR = 0x1000,TCDn_DADDR = 0x2000,TCDn_CITER = 2 (TCDn_BITER)。 -
eDMA引擎写入:
CHn_CSR[ACTIVE] = 0,CHn_CSR[DONE] = 1,CHn_INT[INT] = 1。 -
通道退出,主循环结束,
eDMA进入空闲状态,或者服务下一个通道。
具体流程大致如下图所示:
4.2 监视描述符状态
4.2.1 测试小循环是否完成
两种方法可以测试小循环(次循环)的状态
- 读取
TCDn_CITER字段,并测试其是否有更改 - 读取下表相应字段,根据数值判断状态

当使用硬件发起的(即外设发起的)服务请求时,测试小循环完成的最佳方法是读取TCDn_CITER字段并测试更改。硬件请求和确认握手信号在程序员的模型中是不可见的。
TCD状态字段为硬件激活的通道执行以下序列:
4.2.2 读取激活通道的传输描述符状态
如果在通道执行时读取TCDn_SADDR、TCDn_DADDR和TCDn_NBYTES的值,eDMA将回读它们的真实值。SADDR、DADDR和NBYTES的真实值是eDMA引擎当前在其内部寄存器文件中使用的值,而不是该通道的TCD本地内存中的值。
4.2.3 检查通道抢占状态
抢占的情况是启用了抢占的通道正在执行,而高优先级的请求变为活动的情况。
启用轮循仲裁模式时,通道优先级为0的优先级被视为相等,即不断轮换。
被抢占通道的CHn_CSR[ACTIVE]字段在整个抢占过程中保持断言。当抢占通道执行一次主循环迭代时,被抢占的通道被暂时挂起。如果在全局TCD映射中同时设置了两个CHn_CSR[ACTIVE]字段,则高优先级通道正在主动抢占低优先级通道。
4.3 通道连接(通道链接)
通道连接(或链接)是一种机制,其中一个通道设置另一个通道(或其自身)的TCDn_CSR[START]字段,从而为该通道发起服务请求。在配置得当时,eDMA引擎会在大循环或小循环完成时自动执行此操作。
注:相关寄存器/字段解释
START:如果此标志为1,则通道正在请求服务。eDMA硬件在通道开始执行后自动将此标志清除为0。
小循环通道连接发生在小循环(或大循环的一次迭代)完成时。TCDn_CITER[ELINK]字段决定是否请求小环路连接。启用后,除了最后一次迭代之外,每次大循环迭代之后都会建立通道链接。当主环路耗尽时,仅使用大环路通道link字段来确定是否应该建立通道链路。例如,若采用如下配置:
TCDn_CITER[ELINK] = 1
TCDn_CITER[LINKCH] = 0xC
TCDn_CITER[CITER] value = 0x4
TCDn_CSR[MAJORELINK] = 1
TCDn_CSR[MAJORLINKCH] = 0x7
则执行过程如下:
小循环完成——>设置TCD12_CSR[START]字段
小循环完成——>设置TCD12_CSR[START]字段
小循环完成——>设置TCD12_CSR[START]字段
小循环完成,大循环完成——>设置TCD7_CSR[START]字段
注:相关寄存器/字段解释
TCDn_CITER[CITER]:Current Major Iteration Count
表示通道的当前主循环计数。每次通道完成一个服务请求并将其写回TCD内存时,它都会减少。
从以上配置来看,一个大循环包含了四个小循环。
下面的表格总结了一个DMA通道如何连接到其他DMA通道,也就是在一次循环结束后,使用其他通道的TCD。
4.4 动态程序设计
在通道的执行过程中,也可以改变eDMA的一些配置。
4.4.1 动态改变通道优先级
若想改变组或者通道的优先级可以这样做:
- 通过将
CSR[HALT]字段写1来终止DMA写入 - 改变想改变的组或者通道的优先级
- 通过将
CSR[HALT]字段写0来重新启动DMA操作
4.4.2 动态通道连接(动态通道链接)
动态通道连接是通设置TCDn_CSR[MAJORELINK]字段来实现的,这个字段从TCD的局部内存中读取的,因此可以在DMA通道运行的时使用该特性。为了保险起见,建议采用下面的步骤。
- 给
TCDn_CSR[MAJORELINK]字段写1 - 读取
TCDn_CSR[MAJORELINK]字段的值 - 测试
TCDn_CSR[MAJORELINK]请求状态
如果为1,则动态连接尝试成功
如果为0,则动态连接尝试失败
4.4.3 动态分散/聚集
自动加载一个新的TCD到一个通道,允许同时使用多个TCD,然后进行多个DMA数据的搬运。
有两种方法可以实现动态分散/聚集
Method 1 (不使用大循环连接)
如果通道没有使用大循环连接,则可以使用动态分散/收集请求。
Method 2 (使用大循环连接)
如果通道使用了大循环连接,则仍然可以使用动态分散/收集请求。此方法使用TCDn_DLAST_SGA字段作为TCD的标识。
注:字段/寄存器解释
TCDn_DLAST_SGA :TCD Last Destination Address Adjustment / Scatter Gather Address
调整要加载到此通道的下一个传输控制描述符的最后一个目标地址或内存地址。
4.5 挂起/重启一个已经激活的通道
挂起一个被激活的通道:
- 停止其
DMA请求服务; - 通过读取
DMA的Hardware Request Status (HRS)确保没有服务请求的通道被挂起。
如果需要挂起一个DMA/DSPI传输环路。需要执行以下步骤:
- 通过将
DSPI_RSER[TFFF_RE]字段置0来禁用中断服务请求。 - 验证
DSPI_RSER[TFFF_RE]为0,确保没有来自DSPI的DMA服务请求被执行。如果没有被执行,则通过将ERQ字段置零来禁用硬件服务请求。
注:相关术语解释
DSPI :Dual Serial Peripheral Interface(不能100%确实是这个意思)
双线串行外设接口
我们发现标准SPI通信时发送和接收时主机和从机都只能使用自己的那根数据线进行数据传输,Dual SPI无论是接收还是发送都是使用两根数据线进行的,所以单向数据传输速度上是标准SPI的双倍。
关于什么是标准的SPI通信,可以看这篇帖子:SPI通信协议详解
5 后记
通道仲裁的基本逻辑与《操作系统》中的调度算法非常类似,相关内容可以看这篇帖子:《操作系统》第二章 2.2处理机调度文章来源:https://www.toymoban.com/news/detail-757251.html
没有比人更高的山,没有比脚更长的路。在学习eDMA的过程中,遇到了比较多的困难,关于这种特殊的DMA网上的资料并不多,只能硬着头皮去看官网的文档,一点一点地分析,比较,推理。但这也是一条充满乐趣的道路!文章来源地址https://www.toymoban.com/news/detail-757251.html
到了这里,关于S32K3XX单片机DMA原理深度解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!