一、散列简介
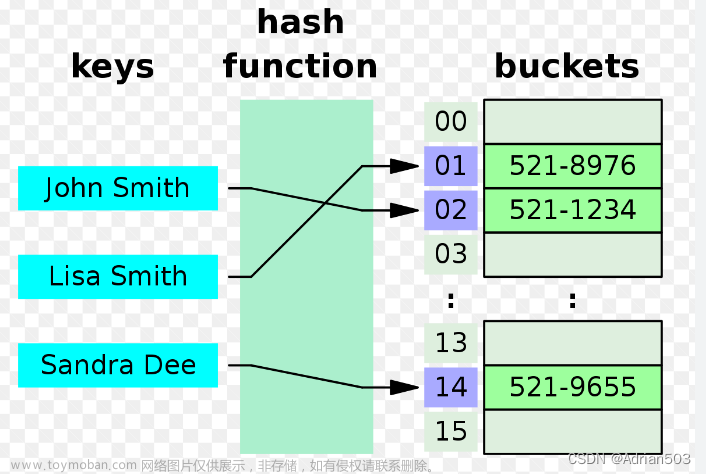
散列表,又叫哈希表(Hash Table),是能够通过给定的关键字的值直接访问到具体对应的值的一个数据结构。也就是说,把关键字映射到一个表中的位置来直接访问记录,以加快访问速度。
通常,把这个关键字称为 Key,把对应的记录称为 Value,所以也可以说是通过 Key 访问一个映射表来得到 Value 的地址。而这个映射表,也叫作散列函数或者哈希函数,存放记录的数组叫作散列表
冲突:不同的关键码映射到同一个散列地址

二、散列函数
1)除留余数法
h(key)=key mod M
key为关键字值,mod代表采用取模运算,M为散列表的长度。
M的取值十分重要,M选取不当可能造成严重冲突。如果key是十进制数,则M应当避免取10的幂。
一般而言,选择一个不超过M的最大的素数P,令散列函数h(key)=key mod P
2)平方取中法
这是一种常用的哈希函数构造方法。这个方法是先取关键字的平方,然后根据可使用空间的大小,选取平方数是中间几位为哈希地址。
哈希函数 H(key)=“key2的中间几位”因为这种方法的原理是通过取平方扩大差别,平方值的中间几位和这个数的每一位都相关,则对不同的关键字得到的哈希函数值不易产生冲突,由此产生的哈希地址也较为均匀。

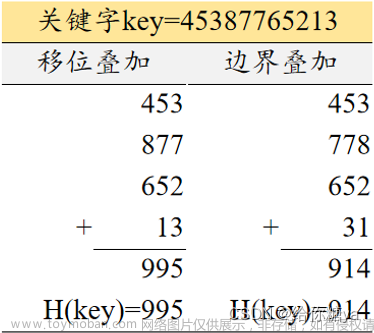
3)折叠法
折叠法是将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位),这方法称为折叠法。
4)数字分析法
数字分析法是取数据元素关键字中某些取值较均匀的数字位作为哈希地址的方法。即当关键字的位数很多时,可以通过对关键字的各位进行分析,丢掉分布不均匀的位,作为哈希值它只适合于所有关键字值已知的情况。通过分析分布情况把关键字取值区间转化为一个较小的关键字取值区间

三、散列冲突处理办法
1)拉链法
拉链法的基本思想:相同散列地址的记录链成一单链表,m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构

缺点:极端情况下,所有元素可能都聚集于一个散列地址对应的单链表中,所以最坏情况下完成一个关键字的搜索需要检查全部的n个元素
2)开地址法

线性探测法

需要注意的是, 这里的h(key)就已经进行了一次取模运算

以上图为例,h(key)=key mod 11
①35 mod 11=2 ,2号位置已经被24占用,因此向后探测②(2+1)mod 11=3,3号位置已经被80占用,因此向后探测③(2+2)mod 11=4,4号位置已经被58占用,因此向后探测④(2+3)mod 11=5,5号位置为空,将35放入该位置
缺点:由于是逐个位置向后排列,散列表中的元素产生聚集效应,也就是同义词元素在散列表中密集连续存储,这将导致散列表在镜像元素查找是探查的次数增加,从而影响搜索效率
二次探测法

需要注意的是, 这里的h(key)就已经进行了一次取模运算

以上图为例,h(key)=key mod 11
①35 mod 11=2 ,2号位置已经被24占用,需要探测②(2+1^2)mod 11=3,3号位置已经被80占用,重新探测③(2-1^2)mod 11=1,1号位置为空,将35放入该位置
双散列法

双散列法使用的两个散列函数分别是h1和h2。第一个散列函数用于计算探查序列的起始值,第二个散列函数用于辅助计算候选地址。
h2的作用:对h1散列值产生一个固定增量,实现跳跃式探查;改善二次聚集,对两个散列函数都为同义词的关键字很少
四、性能分析
使用平均查找长度ASL来衡量查找算法,ASL取决于:散列函数,处理冲突办法,装填因子
散列表中已存储集合元素个数n与散列表长M的比例n/M,称为散列表的装填因子。装填因子越大,说明表中记录数越多,表越满,发生冲突的可能性就越大,查找时比较次数就越多
 文章来源:https://www.toymoban.com/news/detail-757444.html
文章来源:https://www.toymoban.com/news/detail-757444.html
拉链法优于开地址法;除留余数法作散列函数优于其他类型函数文章来源地址https://www.toymoban.com/news/detail-757444.html
到了这里,关于数据结构基础--散列表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!