前言
最近在学go操作excel,毕竟在web开发里,操作excel是非常非常常见的。这里我选择用 excelize 库来实现操作excel。
为了方便和通用,我们需要把导入导出进行封装,这样以后就可以很方便的拿来用,或者进行扩展。

我参考的是这篇文章:【GO】excelize导入导出封装
功能
这个导入导出封装,除了基本的导入导出,我还需要一些其他功能。例如:设置隔行背景色、自适应行高、忽略指定字段或导出指定字段、复杂表头 等等。
因为实际项目中,操作excel不可能只是导出一个很简单的excel,实际项目中的要求往往要复杂的多。

导入
导入有以下几个通用的实现
- 导入单个sheet的数据(已完成)
- 导入指定sheet的数据(已完成)
- 导入多个sheet的数据(已完成)
导出
导出呢,就要复杂很多了,一级表头的普通导出是最简单的,实际项目中往往还会有多级表头,然后不管是一级还是多级表头,还需要有各种要求的样式,隔行背景色、自适应行高这种已经算简单的了,复杂点的还有一对多的纵向单元格合并。
所以导出需要实现以下这些:
- 普通导出(已完成)
- 一级表头
- 单个sheet
- 复杂表头、树形结构表头导出(未完成)
- 多个sheet导出(未完成)
- 基于map导出(未完成)
- 一对多纵向合并单元格(未完成)
- 动态导出列(已完成)
- 忽略指定字段
- 导出指定字段
- 动态更改表头名称
- 隔行背景色样式(已完成)
- 自适应行高样式(已完成)
这篇文章我们就来实现那几个已完成(未完成的还没开始实现呢,还有好多没实现,哭了)

其实上面这些功能,我之前早就在Java中实现了。感兴趣的话可以去这篇文章看看,有完整代码:
poi+easypoi实现表头多层循环,多级动态表头、树形结构动态表头、纵向合并单元格、多个sheet导出
实现
我们先在项目中,创建一个excel文件夹,里面放的就是我们封装的实现函数

准备
既然是通用的导入导出,那每次导入导出不同表格时,不可能说写死导入哪些列(列名),而是应该是按照不同表格对应的不同结构体来进行解析数据或导出数据。
所以我们可以定义一个专门用于解析excel的tag结构体(类似于easypoi的@Excel注解),在这个tag结构体定义几个字段,什么表头名称、列下标、列宽啊这些
用的时候呢,就是在不同结构体中,使用反引号去定义 表头名称、列下标、列宽 这些的值。
在 excel.go 中
自定义一个tag结构体
package excel
import (
"github.com/pkg/errors"
"github.com/xuri/excelize/v2"
"regexp"
"strconv"
"strings"
)
// 定义正则表达式模式
const (
ExcelTagKey = "excel"
Pattern = "name:(.*?);|index:(.*?);|width:(.*?);|needMerge:(.*?);|replace:(.*?);"
)
type ExcelTag struct {
Value interface{}
Name string // 表头标题
Index int // 列下标(从0开始)
Width int // 列宽
NeedMerge bool // 是否需要合并
Replace string // 替换(需要替换的内容_替换后的内容。比如:1_未开始 ==> 表示1替换为未开始)
}
// 构造函数,返回一个带有默认值的 ExcelTag 实例
func NewExcelTag() ExcelTag {
return ExcelTag{
// 导入时会根据这个下标来拿单元格的值,当目标结构体字段没有设置index时,
// 解析字段tag值时Index没读到就一直默认为0,拿单元格的值时,就始终拿的是第一列的值
Index: -1, // 设置 Index 的默认值为 -1
}
}
定义好了tag结构体,我们还需要给它绑定解析tag的方法
// 读取字段tag值
func (e *ExcelTag) GetTag(tag string) (err error) {
// 编译正则表达式
re := regexp.MustCompile(Pattern)
matches := re.FindAllStringSubmatch(tag, -1)
if len(matches) > 0 {
for _, match := range matches {
for i, val := range match {
if i != 0 && val != "" {
e.setValue(match, val)
}
}
}
} else {
err = errors.New("未匹配到值")
return
}
return
}
// 设置ExcelTag 对应字段的值
func (e *ExcelTag) setValue(tag []string, value string) {
if strings.Contains(tag[0], "name") {
e.Name = value
}
if strings.Contains(tag[0], "index") {
v, _ := strconv.ParseInt(value, 10, 8)
e.Index = int(v)
}
if strings.Contains(tag[0], "width") {
v, _ := strconv.ParseInt(value, 10, 8)
e.Width = int(v)
}
if strings.Contains(tag[0], "needMerge") {
v, _ := strconv.ParseBool(value)
e.NeedMerge = v
}
if strings.Contains(tag[0], "replace") {
e.Replace = value
}
}
用的时候,比如在某个用户信息结构体中

自定义一个excel对象结构体
定义好了tag结构体,同样是在 excel.go 文件中,我们还需要一个excel对象结构体,里面有excel file对象、样式等属性,然后再给它绑定设置样式的方法。
type Excel struct {
F *excelize.File // excel 对象
TitleStyle int // 表头样式
HeadStyle int // 表头样式
ContentStyle1 int // 主体样式1,无背景色
ContentStyle2 int // 主体样式2,有背景色
}
// 初始化
func ExcelInit() (e *Excel) {
e = &Excel{}
// excel构建
e.F = excelize.NewFile()
// 初始化样式
e.getTitleRowStyle()
e.getHeadRowStyle()
e.getDataRowStyle()
return e
}
// 获取边框样式
func getBorder() []excelize.Border {
return []excelize.Border{ // 边框
{Type: "top", Color: "000000", Style: 1},
{Type: "bottom", Color: "000000", Style: 1},
{Type: "left", Color: "000000", Style: 1},
{Type: "right", Color: "000000", Style: 1},
}
}
// 标题样式
func (e *Excel) getTitleRowStyle() {
e.TitleStyle, _ = e.F.NewStyle(&excelize.Style{
Alignment: &excelize.Alignment{ // 对齐方式
Horizontal: "center", // 水平对齐居中
Vertical: "center", // 垂直对齐居中
},
Fill: excelize.Fill{ // 背景颜色
Type: "pattern",
Color: []string{"#fff2cc"},
Pattern: 1,
},
Font: &excelize.Font{ // 字体
Bold: true,
Size: 16,
},
Border: getBorder(),
})
}
// 列头行样式
func (e *Excel) getHeadRowStyle() {
e.HeadStyle, _ = e.F.NewStyle(&excelize.Style{
Alignment: &excelize.Alignment{ // 对齐方式
Horizontal: "center", // 水平对齐居中
Vertical: "center", // 垂直对齐居中
WrapText: true, // 自动换行
},
Fill: excelize.Fill{ // 背景颜色
Type: "pattern",
Color: []string{"#FDE9D8"},
Pattern: 1,
},
Font: &excelize.Font{ // 字体
Bold: true,
Size: 14,
},
Border: getBorder(),
})
}
// 数据行样式
func (e *Excel) getDataRowStyle() {
style := excelize.Style{}
style.Border = getBorder()
style.Alignment = &excelize.Alignment{
Horizontal: "center", // 水平对齐居中
Vertical: "center", // 垂直对齐居中
WrapText: true, // 自动换行
}
style.Font = &excelize.Font{
Size: 12,
}
e.ContentStyle1, _ = e.F.NewStyle(&style)
style.Fill = excelize.Fill{ // 背景颜色
Type: "pattern",
Color: []string{"#cce7f5"},
Pattern: 1,
}
e.ContentStyle2, _ = e.F.NewStyle(&style)
}
导入
接下来我们就可以来实现导入函数的封装了,在 excel_import.go 文件中
package excel
import (
"github.com/pkg/errors"
"github.com/xuri/excelize/v2"
"go-web/util"
"reflect"
"strconv"
)
// ImportExcel 导入数据(单个sheet)
// 需要在传入的结构体中的字段加上tag:excel:"title:列头名称;"
// f 获取到的excel对象、dst 导入目标对象【传指针】
// headIndex 表头的索引,从0开始(用于获取表头名字)
// startRow 头行行数(从第startRow+1行开始扫)
func ImportExcel(f *excelize.File, dst interface{}, headIndex, startRow int) (err error) {
sheetName := f.GetSheetName(0) // 单个sheet时,默认读取第一个sheet
err = importData(f, dst, sheetName, headIndex, startRow)
return
}
// ImportBySheet 导入数据(读取指定sheet)sheetName Sheet名称
func ImportBySheet(f *excelize.File, dst interface{}, sheetName string, headIndex, startRow int) (err error) {
// 当需要读取多个sheet时,可以通过下面的方式,来调用 ImportBySheet 这个函数
//sheetList := f.GetSheetList()
//for _, sheetName := range sheetList {
// ImportBySheet(f,dst,sheetName,headIndex,startRow)
//}
err = importData(f, dst, sheetName, headIndex, startRow)
return
}
// 解析数据
func importData(f *excelize.File, dst interface{}, sheetName string, headIndex, startRow int) (err error) {
rows, err := f.GetRows(sheetName) // 获取所有行
if err != nil {
err = errors.New(sheetName + "工作表不存在")
return
}
dataValue := reflect.ValueOf(dst) // 取目标对象的元素类型、字段类型和 tag
// 判断数据的类型
if dataValue.Kind() != reflect.Ptr || dataValue.Elem().Kind() != reflect.Slice {
err = errors.New("Invalid data type")
}
heads := []string{} // 表头
dataType := dataValue.Elem().Type().Elem() // 获取导入目标对象的类型信息
// 遍历行,解析数据并填充到目标对象中
for rowIndex, row := range rows {
if rowIndex == headIndex {
heads = row
}
if rowIndex < startRow { // 跳过头行
continue
}
newData := reflect.New(dataType).Elem() // 创建新的目标对象
// 遍历目标对象的字段
for i := 0; i < dataType.NumField(); i++ {
// 这里要用构造函数,构造函数里指定了Index默认值为-1,当目标结构体的tag没有指定index的话,那么 excelTag.Index 就一直为0
// 那么 row[excelizeIndex] 就始终是 row[0],始终拿的是第一列的数据
var excelTag = NewExcelTag()
field := dataType.Field(i) // 获取字段信息和tag
tag := field.Tag.Get(ExcelTagKey)
if tag == "" { // 如果tag不存在,则跳过
continue
}
err = excelTag.GetTag(tag)
if err != nil {
return
}
cellValue := ""
if excelTag.Index >= 0 { // 当tag里指定了index时,根据这个index来拿数据
excelizeIndex := excelTag.Index // 解析tag的值
if excelizeIndex >= len(row) { // 防止下标越界
continue
}
cellValue = row[excelizeIndex] // 获取单元格的值
} else { // 否则根据表头名称来拿数据
if util.IsContain(heads, excelTag.Name) { // 当tag里的表头名称和excel表格里面的表头名称相匹配时
if i >= len(row) { // 防止下标越界
continue
}
cellValue = row[i] // 获取单元格的值
}
}
// 根据字段类型设置值
switch field.Type.Kind() {
case reflect.Int:
v, _ := strconv.ParseInt(cellValue, 10, 64)
newData.Field(i).SetInt(v)
case reflect.String:
newData.Field(i).SetString(cellValue)
}
}
// 将新的目标对象添加到导入目标对象的slice中
dataValue.Elem().Set(reflect.Append(dataValue.Elem(), newData))
}
return
}
导入这里用到了一个 IsContain 函数,代码如下:
// 判断数组中是否包含指定元素
func IsContain(items interface{}, item interface{}) bool {
switch items.(type) {
case []int:
intArr := items.([]int)
for _, value := range intArr {
if value == item.(int) {
return true
}
}
case []string:
strArr := items.([]string)
for _, value := range strArr {
if value == item.(string) {
return true
}
}
default:
return false
}
return false
}
导出
在 excel_export.go 文件中
package excel
import (
"fmt"
"github.com/pkg/errors"
"github.com/xuri/excelize/v2"
"net/http"
"reflect"
"sort"
"strings"
)
// GetExcelColumnName 根据列数生成 Excel 列名
func GetExcelColumnName(columnNumber int) string {
columnName := ""
for columnNumber > 0 {
columnNumber--
columnName = string('A'+columnNumber%26) + columnName
columnNumber /= 26
}
return columnName
}
// ExportExcel excel导出
func ExportExcel(sheet, title, fields string, isGhbj, isIgnore bool, list interface{}, changeHead map[string]string, e *Excel) (err error) {
index, _ := e.F.GetSheetIndex(sheet)
if index < 0 { // 如果sheet名称不存在
e.F.NewSheet(sheet)
}
// 构造excel表格
// 取目标对象的元素类型、字段类型和 tag
dataValue := reflect.ValueOf(list)
// 判断数据的类型
if dataValue.Kind() != reflect.Slice {
err = errors.New("invalid data type")
return
}
// 构造表头
endColName, dataRow, err := normalBuildTitle(e, sheet, title, fields, isIgnore, changeHead, dataValue)
if err != nil {
return
}
// 构造数据行
err = normalBuildDataRow(e, sheet, endColName, fields, dataRow, isGhbj, isIgnore, dataValue)
return
}
// ================================= 普通导出 =================================
// NormalDownLoad 导出excel并下载(单个sheet)
func NormalDownLoad(fileName, sheet, title string, isGhbj bool, list interface{}, res http.ResponseWriter) error {
f, err := NormalDynamicExport(list, sheet, title, "", isGhbj, false, nil)
if err != nil {
return err
}
DownLoadExcel(fileName, res, f)
return nil
}
// NormalDynamicDownLoad 动态导出excel并下载(单个sheet)
// isIgnore 是否忽略指定字段(true 要忽略的字段 false 要导出的字段)
// fields 选择的字段,多个字段用逗号隔开,最后一个字段后面也要加逗号,如:字段1,字段2,字段3,
// changeHead 要改变表头的字段,格式是{"字段1":"更改的表头1","字段2":"更改的表头2"}
func NormalDynamicDownLoad(fileName, sheet, title, fields string, isGhbj, isIgnore bool,
list interface{}, changeHead map[string]string, res http.ResponseWriter) error {
f, err := NormalDynamicExport(list, sheet, title, fields, isGhbj, isIgnore, changeHead)
if err != nil {
return err
}
DownLoadExcel(fileName, res, f)
return nil
}
// NormalDynamicExport 导出excel
// ** 需要在传入的结构体中的字段加上tag:excelize:"title:列头名称;index:列下标(从0开始);"
// list 需要导出的对象数组、sheet sheet名称、title 标题、isGhbj 是否设置隔行背景色
func NormalDynamicExport(list interface{}, sheet, title, fields string, isGhbj, isIgnore bool, changeHead map[string]string) (file *excelize.File, err error) {
e := ExcelInit()
err = ExportExcel(sheet, title, fields, isGhbj, isIgnore, list, changeHead, e)
if err != nil {
return
}
return e.F, err
}
// 构造表头(endColName 最后一列的列名 dataRow 数据行开始的行号)
func normalBuildTitle(e *Excel, sheet, title, fields string, isIgnore bool, changeHead map[string]string, dataValue reflect.Value) (endColName string, dataRow int, err error) {
dataType := dataValue.Type().Elem() // 获取导入目标对象的类型信息
var exportTitle []ExcelTag // 遍历目标对象的字段
for i := 0; i < dataType.NumField(); i++ {
var excelTag ExcelTag
field := dataType.Field(i) // 获取字段信息和tag
tag := field.Tag.Get(ExcelTagKey)
if tag == "" { // 如果非导出则跳过
continue
}
if fields != "" { // 选择要导出或要忽略的字段
if isIgnore && strings.Contains(fields, field.Name+",") { // 忽略指定字段
continue
}
if !isIgnore && !strings.Contains(fields, field.Name+",") { // 导出指定字段
continue
}
}
err = excelTag.GetTag(tag)
if err != nil {
return
}
// 更改指定字段的表头标题
if changeHead != nil && changeHead[field.Name] != "" {
excelTag.Name = changeHead[field.Name]
}
exportTitle = append(exportTitle, excelTag)
}
// 排序
sort.Slice(exportTitle, func(i, j int) bool {
return exportTitle[i].Index < exportTitle[j].Index
})
var titleRowData []interface{} // 列头行
for i, colTitle := range exportTitle {
endColName := GetExcelColumnName(i + 1)
if colTitle.Width > 0 { // 根据给定的宽度设置列宽
_ = e.F.SetColWidth(sheet, endColName, endColName, float64(colTitle.Width))
} else {
_ = e.F.SetColWidth(sheet, endColName, endColName, float64(20)) // 默认宽度为20
}
titleRowData = append(titleRowData, colTitle.Name)
}
endColName = GetExcelColumnName(len(titleRowData)) // 根据列数生成 Excel 列名
if title != "" {
dataRow = 3 // 如果有title,那么从第3行开始就是数据行,第1行是title,第2行是表头
e.F.SetCellValue(sheet, "A1", title)
e.F.MergeCell(sheet, "A1", endColName+"1") // 合并标题单元格
e.F.SetCellStyle(sheet, "A1", endColName+"1", e.TitleStyle)
e.F.SetRowHeight(sheet, 1, float64(30)) // 第一行行高
e.F.SetRowHeight(sheet, 2, float64(30)) // 第二行行高
e.F.SetCellStyle(sheet, "A2", endColName+"2", e.HeadStyle)
if err = e.F.SetSheetRow(sheet, "A2", &titleRowData); err != nil {
return
}
} else {
dataRow = 2 // 如果没有title,那么从第2行开始就是数据行,第1行是表头
e.F.SetRowHeight(sheet, 1, float64(30))
e.F.SetCellStyle(sheet, "A1", endColName+"1", e.HeadStyle)
if err = e.F.SetSheetRow(sheet, "A1", &titleRowData); err != nil {
return
}
}
return
}
// 构造数据行
func normalBuildDataRow(e *Excel, sheet, endColName, fields string, row int, isGhbj, isIgnore bool, dataValue reflect.Value) (err error) {
//实时写入数据
for i := 0; i < dataValue.Len(); i++ {
startCol := fmt.Sprintf("A%d", row)
endCol := fmt.Sprintf("%s%d", endColName, row)
item := dataValue.Index(i)
typ := item.Type()
num := item.NumField()
var exportRow []ExcelTag
maxLen := 0 // 记录这一行中,数据最多的单元格的值的长度
//遍历结构体的所有字段
for j := 0; j < num; j++ {
dataField := typ.Field(j) //获取到struct标签,需要通过reflect.Type来获取tag标签的值
tagVal := dataField.Tag.Get(ExcelTagKey)
if tagVal == "" { // 如果非导出则跳过
continue
}
if fields != "" { // 选择要导出或要忽略的字段
if isIgnore && strings.Contains(fields, dataField.Name+",") { // 忽略指定字段
continue
}
if !isIgnore && !strings.Contains(fields, dataField.Name+",") { // 导出指定字段
continue
}
}
var dataCol ExcelTag
err = dataCol.GetTag(tagVal)
fieldData := item.FieldByName(dataField.Name) // 取字段值
if fieldData.Type().String() == "string" { // string类型的才计算长度
rwsTemp := fieldData.Len() // 当前单元格内容的长度
if rwsTemp > maxLen { //这里取每一行中的每一列字符长度最大的那一列的字符
maxLen = rwsTemp
}
}
// 替换
if dataCol.Replace != "" {
split := strings.Split(dataCol.Replace, ",")
for j := range split {
s := strings.Split(split[j], "_") // 根据下划线进行分割,格式:需要替换的内容_替换后的内容
value := fieldData.String()
if strings.Contains(fieldData.Type().String(), "int") {
value = strconv.Itoa(int(fieldData.Int()))
} else if fieldData.Type().String() == "bool" {
value = strconv.FormatBool(fieldData.Bool())
} else if strings.Contains(fieldData.Type().String(), "float") {
value = strconv.FormatFloat(fieldData.Float(), 'f', -1, 64)
}
if s[0] == value {
dataCol.Value = s[1]
}
}
} else {
dataCol.Value = fieldData
}
if err != nil {
return
}
exportRow = append(exportRow, dataCol)
}
// 排序
sort.Slice(exportRow, func(i, j int) bool {
return exportRow[i].Index < exportRow[j].Index
})
var rowData []interface{} // 数据列
for _, colTitle := range exportRow {
rowData = append(rowData, colTitle.Value)
}
if isGhbj && row%2 == 0 {
_ = e.F.SetCellStyle(sheet, startCol, endCol, e.ContentStyle2)
} else {
_ = e.F.SetCellStyle(sheet, startCol, endCol, e.ContentStyle1)
}
if maxLen > 25 { // 自适应行高
d := maxLen / 25
f := 25 * d
_ = e.F.SetRowHeight(sheet, row, float64(f))
} else {
_ = e.F.SetRowHeight(sheet, row, float64(25)) // 默认行高25
}
if err = e.F.SetSheetRow(sheet, startCol, &rowData); err != nil {
return
}
row++
}
return
}
// 下载
func DownLoadExcel(fileName string, res http.ResponseWriter, file *excelize.File) {
// 设置响应头
res.Header().Set("Content-Type", "text/html; charset=UTF-8")
res.Header().Set("Content-Type", "application/octet-stream")
res.Header().Set("Content-Disposition", "attachment; filename="+fileName+".xlsx")
res.Header().Set("Access-Control-Expose-Headers", "Content-Disposition")
err := file.Write(res) // 写入Excel文件内容到响应体
if err != nil {
http.Error(res, err.Error(), http.StatusInternalServerError)
return
}
}
测试
ok,终于写完了导入导出,接下来就是测试啦

在 excel_main.go 文件中
package main
import (
"fmt"
"github.com/xuri/excelize/v2"
"go-web/util/excel"
)
func main() {
//export()
imports()
}
type Test struct {
Id string `excel:"name:用户账号;"`
Name string `excel:"name:用户姓名;index:1;"`
Email string `excel:"name:用户邮箱;width:25;"`
Com string `excel:"name:所属公司;"`
Dept string `excel:"name:所在部门;"`
RoleKey string `excel:"name:角色代码;"`
RoleName string `excel:"name:角色名称;replace:1_超级管理员,2_普通用户;"`
Remark string `excel:"name:备注;width:40;"`
}
// 导出
func export() {
var testList = []Test{
{"fuhua", "符华", "fuhua@123.com", "太虚剑派", "开发部", "CJGLY", "1", "备注备注"},
{"baiye", "白夜", "baiye@123.com", "天命科技有限公司", "执行部", "PTYG", "2", ""},
{"chiling", "炽翎", "chiling@123.com", "太虚剑派", "行政部", "PTYG", "2", "备注备注备注备注"},
{"yunmo", "云墨", "yunmo@123.com", "太虚剑派", "财务部", "CJGLY", "1", ""},
{"yuelun", "月轮", "yuelun@123.com", "天命科技有限公司", "执行部", "CJGLY", "1", ""},
{"xunyu", "迅羽",
"xunyu@123.com哈哈哈哈哈哈哈哈这里是最大行高测试哈哈哈哈哈哈哈哈这11111111111里是最大行高测试哈哈哈哈哈哈哈哈这里是最大行高测试",
"天命科技有限公司", "开发部", "PTYG", "2",
"备注备注备注备注com哈哈哈哈哈哈哈哈这里是最大行高测试哈哈哈哈哈哈哈哈这里是最大行高测试哈哈哈哈哈哈哈哈这里是最大行高测里是最大行高测试哈哈哈哈哈哈哈哈这里是最大行高测试"},
}
changeHead := map[string]string{"Id": "账号", "Name": "真实姓名"}
//f, err := excel.NormalExport(testList, "Sheet1", "用户信息", "Id,Email,", true, true, changeHead)
f, err := excel.NormalDynamicExport(testList, "Sheet1", "用户信息", "", true, false, changeHead)
if err != nil {
fmt.Println(err)
return
}
f.Path = "C:\\Users\\Administrator\\Desktop\\测试.xlsx"
if err := f.Save(); err != nil {
fmt.Println(err)
return
}
}
// 导入
func imports() {
f, err := excelize.OpenFile("C:\\Users\\Administrator\\Desktop\\测试.xlsx")
if err != nil {
fmt.Println("文件打开失败")
}
importList := []Test{}
err = excel.ImportExcel(f, &importList, 1, 2)
if err != nil {
fmt.Println(err)
}
for _, t := range importList {
fmt.Println(t)
}
}
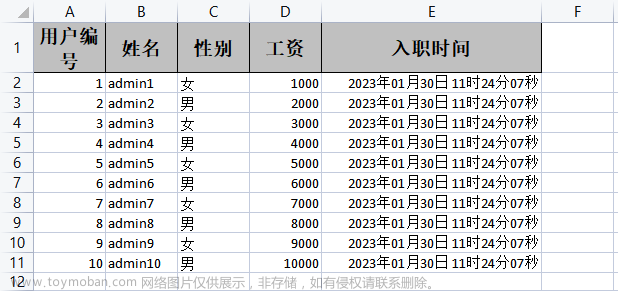
实现效果
然后我们再来看看实现效果,说实话,我觉得这表格还挺好看的哩,不愧是我

导出

导入

最后
这样,我们就实现了一个通用的导入导出工具封装。
上面这些就是全部代码啦,后续等我把剩下几个复杂导出弄完(挖坑…),我会把这些代码全部抽出来,做成一个独立的组件模块,然后上传到Git上,这样以后不管做哪个项目,用的时候直接在go.mod引入就可以啦~完美😁
第二篇已更新:【Go】excelize库实现excel导入导出封装(二),基于map、多个sheet、多级表头、树形结构表头导出,横向、纵向合并单元格导出
好啦,以上就是本篇文章的全部内容了,如果你觉得对你有帮助或者觉得博主写得不错,千万不要吝啬你的大拇指哟(^U^)ノ~YO文章来源:https://www.toymoban.com/news/detail-757580.html
 文章来源地址https://www.toymoban.com/news/detail-757580.html
文章来源地址https://www.toymoban.com/news/detail-757580.html
到了这里,关于【Go】excelize库实现excel导入导出封装(一),自定义导出样式、隔行背景色、自适应行高、动态导出指定列、动态更改表头的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!