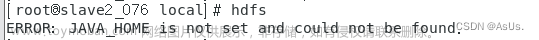出现错误:
Hadoop启动时出现错误:Cannot execute /home/hadoop/libexec/hadoop-config.sh.
原因分析
'ERROR: Cannot execute /usr/local/Hadoop/libexec/hdfs-config.sh'表示无法执行指定路径下的 hdfs-config.sh 文件。
可能是环境变量配置错误导致的,所以要检查 Hadoop 的环境变量配置是否正确。确保 Hadoop 的相关路径正确设置。具体解决方法如下:
解决方法:
输入运行:
source /etc/profile #重新加载/etc/profile文件
vim ~/.bashrc

检查.bashrc文件中的HADOOP_HOME是否有错,HADOOP_HOME需要被配置成你机器上Hadoop的安装路径,比如这里是安装在/usr/local./hadoop目录。
保存退出后,运行如下命令使配置立即生效:
source ~/.bashrc
此时再次启动Hadoop显示启动成功:
./sbin/start-dfs.sh

搞定!
❗注:
输入命令source /etc/profile时,会重新加载/etc/profile文件,这个文件包含了系统范围的环境变量和配置。这个命令通常用于在当前会话中更新环境变量。
如果想要恢复到之前的环境,可以关闭当前终端会话,并重新打开一个新的终端会话。这将重新加载默认的环境变量和配置文件。
如果想在当前终端会话中恢复到之前的环境,可以使用以下命令:文章来源:https://www.toymoban.com/news/detail-757852.html
exec bash
这将重新启动当前shell会话,并重新加载~/.bashrc文件,其中包含用户特定的环境变量和配置。文章来源地址https://www.toymoban.com/news/detail-757852.html
到了这里,关于Hadoop启动时出现错误:Cannot execute /home/hadoop/libexec/hadoop-config.sh.的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!