一. 创作背景
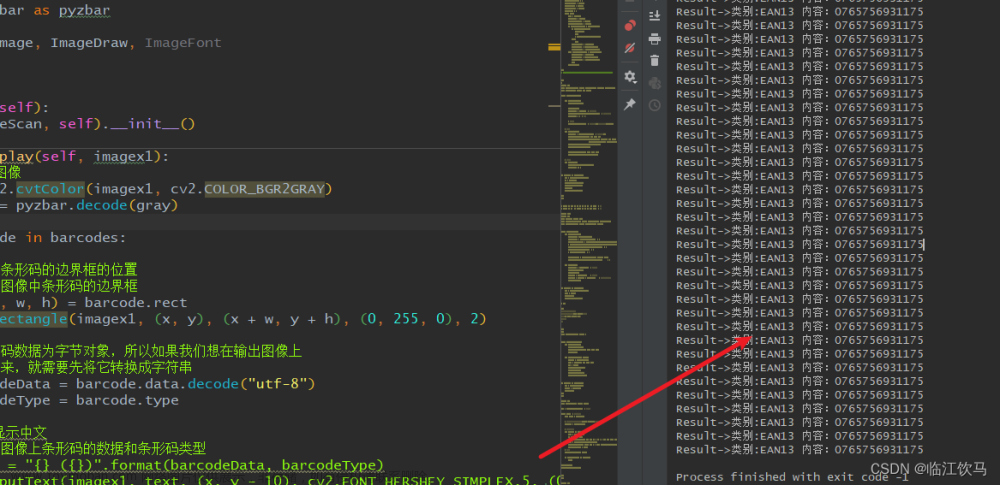
最近有一个项目需要识别 Code128 条码, 本来想用 OpenCV 里面现成的 barcode 库来实现, 可一用发现只能定位到条码位置, 并不能解码, 看了原码才知道不能解码 Code128 类型的条码, 所以就只有自己弄一个了
下图是本文用来当实例的条码
二. 需要掌握的基本知识
- 灰度拉伸(主要是为了增强图像对比度, 这一个不是必需的)
- 亚像素边缘
- 图像梯度
- 直线拟合
- Code128 条码编码规则, 这点我也会在文章中顺带讲一些
- BYTE 就是 unsigned char, 这里单独列出来是因为有的新手同学在用代码的时候, 不知道 BYTE 是什么数据类型,
可以用 typedef unsigned char BYTE; 这样的语句来定义, 在下面的代码中我就不再说明了
注: 本文用的是 VS2015 Win32 控制台项目演示, 配置成 x64, 带 MFC 库. 所以有的变量类型是标准库里没有的, 用的时候需要注意. 另外 OpenCV 版本是 4.7.0
对于亚像素和图像梯度, 可以看一下 基于多项式插值的亚像素边缘定位算法, 本文会用到里面的相关知识点, 也会将代码改动一下, 适用于当前应用
三. 灰度拉伸算法
这个算法比较简单, 功能也在上面说了, 就只是为了增强图像对比度, 让条码的条纹黑的更黑, 白的更白, PS 里面也有这样的算法, 现在用 PS 展示一下效果
原始图像
拉伸后图像
怎么样, 是不是看起来黑白对比要明显一点
拉伸代码如下
void Stretch(const Mat & img_src, Mat & img_dst, double min_val/* = 55.0*/, double max_val/* = 200.0*/)
{
assert(1 == img_src.channels());
double dDelta = max_val - min_val;
dDelta += (dDelta < 0.000001? 0.000001: 0); // 只是为了防止除数为 0
const double k = 255.0 / dDelta;
const double b = -255.0 * min_val / dDelta;
const int table_bins = 256;
Mat look_up(1, table_bins, CV_8U, Scalar(0));
BYTE *data_ptr = look_up.data;
for (int i = 0; i < table_bins; i++)
{
if (i < min_val)
{
*data_ptr = 0;
}
else if (i > max_val)
{
*data_ptr = 255;
}
else
{
*data_ptr = (BYTE)(k * i + b);
}
data_ptr++;
}
LUT(img_src, look_up, img_dst);
return;
}
测试代码
Mat mTst = imread("F:\\Tmp\\barcode\\nd-hp-0003.png");
Mat mDst;
cvtColor(mTst, mTst, COLOR_BGR2GRAY);
Stretch(mTst, mDst, 24, 200);
namedWindow("Stretch", WINDOW_NORMAL);
imshow("Stretch", mDst);

这个参数和 PS 里用的一样, 效果看起来也差不多, 只是这里用的是单通道, PS 里面用了 3 通道
四. 条码分割
条码识别的原理是识别这些条纹的宽度来识别编码的, 所以条码分割是最重要的步骤. 要把黑白条纹精确的分开, 还不能受图像亮度与其他干扰, 这一步当然不能用二值化, 二值化虽然简单, 但是对于实际使用的环境来讲, 适应性很差
在开始之前, 需要准备一些程序里会用到的简单的辅助类
1. 线程同步
多线程只是为了程序跑起来更快更有效率, 但是也带来了资源与数据需要同步访问的问题, 所以为了方便理解, 我不打算用 MFC 库里的线程同步相关的类, 写一个相对容易理解和操作的类
头文件
#pragma once
#include <thread>
#include <vector>
using namespace std;
// 线程同步类
class CThreadSync
{
public:
CThreadSync(int nThreads = 1);
~CThreadSync(void);
public:
int m_nWaitTime;
void ResetThreadCount(int nThreads); // 重新设置线程数量
void SetFinishFlag(int nTheadId = 0); // 设置线程完成标记
void WaitThreadFinish(int nSleep = 1); // 等待所有线程完成
protected:
vector<int> m_FinishCount;
};
源文件
#include "stdafx.h"
#include "ThreadSync.h"
CThreadSync::CThreadSync(int threads)
: m_nWaitTime(0)
{
ASSERT(threads > 0);
m_FinishCount.resize(threads);
for (auto &it : m_FinishCount)
{
it = 0;
}
}
CThreadSync::~CThreadSync(void)
{
}
void CThreadSync::ResetThreadCount(int threads)
{
m_nWaitTime = 0;
m_FinishCount.resize(threads);
for (auto &it : m_FinishCount)
{
it = 0;
}
}
void CThreadSync::SetFinishFlag(int thread_id)
{
m_FinishCount[thread_id] = 1;
}
void CThreadSync::WaitThreadFinish(int sleep_time)
{
if (sleep_time <= 0)
{
return;
}
int sum = 0;
LABEL_RETRY:
try
{
const int threads = (int)m_FinishCount.size();
do
{
Sleep(sleep_time);
sum = 0;
for (const auto &it: m_FinishCount)
{
sum += it;
}
m_nWaitTime += sleep_time;
} while (sum < threads);
}
catch (...)
{
m_nWaitTime += sleep_time;
goto LABEL_RETRY;
}
}
上面的代码很简单, 只是一个等待线程完成计数
2. 直线拟合类
直线拟合是用来定位条纹的边缘, 如果不用拟合的话, 容易受干扰从而定位边缘不准确. 这个可以用 OpenCV 中现成的函数 fitLine, 所以就不用再自己造一个. 但是为了方便后续的使用, 将其封装到类里面我觉得比较好一点
头文件
#pragma once
#include <vector>
#include <opencv2\\opencv.hpp>
#include <opencv2\\features2d.hpp>
using namespace cv;
using namespace std;
// 直接拟合类
class CFitLine
{
CFitLine(int pt_need = 16);
~CFitLine();
public:
double k; // 点斜式
double b;
double A; // 一般式
double B;
double C;
Point2d ptStart;
Point2d ptEnd;
BOOL Fit(const vector<Point2f> & pts);
Point2d GetCenter(void) const;
protected:
int pt_need;
};
源文件
#include "stdafx.h"
#include "FitLine.h"
CFitLine::CFitLine()
: k(0)
, b(0)
, A(0)
, B(0)
, C(0)
, pt_need(pt_need)
{
}
CFitLine::~CFitLine()
{
}
BOOL CFitLine::Fit(const vector<Point2f> & pts)
{
if (pts.size() < pt_need)
{
return FALSE;
}
Vec4d v; // (v[0], v[1]) 是单位方向向量, 所以下面的 (A, B) 是单位法向量, (v[2], v[3]), 是直线上的点
fitLine(pts, v, DIST_HUBER, 0, 0.01, 0.01);
k = v[1] / v[0];
b = v[3] - k * v[2];
A = v[1];
B = -v[0];
C = -A * v[2] - B * v[3];
// 这样做防止竖直的线斜率很大计算会有问题
if (fabs(B) < 0.707)
{
ptStart = Point2d(-(B * pts.front().y + C) / A, pts.front().y);
ptEnd = Point2d(-(B * pts.back().y + C) / A, pts.back().y);
}
else
{
ptStart = Point2d(pts.front().x, -(A * pts.front().x + C) / B);
ptEnd = Point2d(pts.back().x, -(A * pts.back().x + C) / B);
}
return TRUE;
}
Point2d CFitLine::GetCenter(void) const
{
return (ptStart + ptEnd) * 0.5;
}
直线拟合所需要的点是条纹的边缘, 条纹的边缘需要用到边缘检测, 这里边缘检测用的是 基于多项式插值的亚像素边缘定位算法 中的代码, 本文修改了函数名, 返回参数, 也用到了上面的线程同步的类. 具体代码如下
#define KERNEL_SUM 8
#define KERNEL_HALF 4
/*================================================================
功能: 亚像素边缘
传入参数:
1. imgsrc: 源图像(灰度图像)
2. edge: 目标边缘图像
3. gradient: 梯度幅值图像
4. coordinate: 坐标与方向
5. thres: 边缘阈值
6. parts: 线程数
返回值: 无
================================================================*/
void PolynomialEdge(Mat & imgsrc, Mat & edge, Mat & gradient, Mat & coordinate, int thres, int parts)
{
static Mat kernels[KERNEL_SUM];
if (kernels[0].empty())
{
int k = 0;
kernels[k++] = (Mat_<float>(3, 3) << 1, 2, 1, 0, 0, 0, -1, -2, -1); // 270°
kernels[k++] = (Mat_<float>(3, 3) << 2, 1, 0, 1, 0, -1, 0, -1, -2); // 315°
kernels[k++] = (Mat_<float>(3, 3) << 1, 0, -1, 2, 0, -2, 1, 0, -1); // 0°
kernels[k++] = (Mat_<float>(3, 3) << 0, -1, -2, 1, 0, -1, 2, 1, 0); // 45°
flip(kernels[0], kernels[k++], 0); // 90°
kernels[k++] = (Mat_<float>(3, 3) << -2, -1, 0, -1, 0, 1, 0, 1, 2); // 135°
flip(kernels[2], kernels[k++], 1); // 180°
kernels[k++] = (Mat_<float>(3, 3) << 0, 1, 2, -1, 0, 1, -2, -1, 0); // 225°
}
// 梯度图像
Mat gradients[KERNEL_SUM];
CThreadSync ts(KERNEL_HALF);
for (int i = 0; i < KERNEL_HALF; i++)
{
std::thread f([](Mat * src, Mat * grad, Mat * ker, CThreadSync * ts, int i)
{
filter2D(*src, *grad, CV_16S, *ker);
*(grad + KERNEL_HALF) = -(*grad);
ts->SetFinishFlag(i);
}, &imgsrc, &gradients[i], &kernels[i], &ts, i);
f.detach();
}
ts.WaitThreadFinish(1);
// 幅值和角度矩阵合并成一个矩阵
// 新创建的图像总是连续的, 所以可以按行来操作提高效率
Mat amp_ang(imgsrc.rows, imgsrc.cols, CV_16SC2, Scalar::all(0));
assert(parts >= 1 && parts < (amp_ang.rows >> 1));
ts.ResetThreadCount(parts);
for (int i = 0; i < parts; i++)
{
std::thread f([parts](Mat * amp_ang, Mat * grad, CThreadSync * ts, int i)
{
const int length = amp_ang->rows * amp_ang->cols;
const int step = length / parts;
const int start = i * step;
int end = start + step;
if (i >= parts - 1)
{
end = length;
}
short *amp_ang_ptr = (short *)amp_ang->data + (start << 1);
short *grad_ptr[KERNEL_SUM] = { nullptr };
for (int k = 0; k < KERNEL_SUM; k++)
{
grad_ptr[k] = (short *)grad[k].data + start;
}
for (int j = start; j < end; j++)
{
// 找出最大值来判断方向
for (int k = 0; k < KERNEL_SUM; k++)
{
if (*amp_ang_ptr < *grad_ptr[k])
{
*amp_ang_ptr = *grad_ptr[k]; // 幅值
*(amp_ang_ptr + 1) = k; // 方向
}
grad_ptr[k]++;
}
amp_ang_ptr += 2;
}
ts->SetFinishFlag(i);
}, &_ang, gradients, &ts, i);
f.detach();
}
ts.WaitThreadFinish(1);
edge = Mat::zeros(amp_ang.rows, amp_ang.cols, CV_8UC1);
coordinate = Mat::zeros(amp_ang.rows, amp_ang.cols, CV_32FC3); // x, y, angle
ts.ResetThreadCount(parts);
for (int i = 0; i < parts; i++)
{
std::thread f([thres, parts](Mat * amp_ang, Mat * edge, Mat * coordinate, CThreadSync * ts, int i)
{
static const float root2 = (float)sqrt(2.0);
static const float a2r = (float)(CV_PI / 180.0);
static const short angle_list[] = { 270, 315, 0, 45, 90, 135, 180, 225 };
// 三角函数表
float tri_list[2][KERNEL_SUM] = { 0 };
float tri_list_root2[2][KERNEL_SUM] = { 0 };
for (int j = 0; j < KERNEL_SUM; j++)
{
tri_list[0][j] = (float)(0.5f * cos(angle_list[j] * a2r));
// 0.5 前面的负号非常关键, 因为图像的 y 方向和直角坐标系的 y 方向相反
tri_list[1][j] = (float)(-0.5f * sin(angle_list[j] * a2r));
tri_list_root2[0][j] = tri_list[0][j] * root2;
tri_list_root2[1][j] = tri_list[1][j] * root2;
}
const int end_x = amp_ang->cols - 1;
const int rows = amp_ang->rows / parts;
int start_y = rows * i;
int end_y = start_y + rows;
if (i)
{
start_y -= 2;
}
if (i >= parts - 1)
{
end_y = amp_ang->rows;
}
start_y++;
end_y--;
for (int r = start_y; r < end_y; r++)
{
// 3 * 3 邻域, 所以用3个指针, 一个指针指一行
const short *pAmpang1 = amp_ang->ptr<short>(r - 1);
const short *pAmpang2 = amp_ang->ptr<short>(r);
const short *pAmpang3 = amp_ang->ptr<short>(r + 1);
BYTE *pEdge = edge->ptr<BYTE>(r);
float *pCoord = coordinate->ptr<float>(r);
for (int c = 1; c < end_x; c++)
{
const int j = c << 1;
const int k = j + c;
if (pAmpang2[j] >= thres)
{
switch (pAmpang2[j + 1])
{
case 0:
if (pAmpang2[j] > pAmpang1[j] && pAmpang2[j] >= pAmpang3[j])
{
pEdge[c] = 255;
pCoord[k] = (float)c;
pCoord[k + 1] = r + tri_list[1][pAmpang2[j + 1]] * (pAmpang1[j] - pAmpang3[j]) /
(pAmpang1[j] + pAmpang3[j] - (pAmpang2[j] << 1));
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 4:
if (pAmpang2[j] >= pAmpang1[j] && pAmpang2[j] > pAmpang3[j])
{
pEdge[c] = 255;
pCoord[k] = (float)c;
pCoord[k + 1] = r - tri_list[1][pAmpang2[j + 1]] * (pAmpang1[j] - pAmpang3[j]) /
(pAmpang1[j] + pAmpang3[j] - (pAmpang2[j] << 1));
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 1:
if (pAmpang2[j] > pAmpang1[j - 2] && pAmpang2[j] >= pAmpang3[j + 2])
{
pEdge[c] = 255;
const float tmp = (float)(pAmpang1[j - 2] - pAmpang3[j + 2]) /
(pAmpang1[j - 2] + pAmpang3[j + 2] - (pAmpang2[j] << 1));
pCoord[k] = c + tmp * tri_list_root2[0][pAmpang2[j + 1]];
pCoord[k + 1] = r + tmp * tri_list_root2[1][pAmpang2[j + 1]];
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 5:
if (pAmpang2[j] >= pAmpang1[j - 2] && pAmpang2[j] > pAmpang3[j + 2])
{
pEdge[c] = 255;
const float tmp = (float)(pAmpang1[j - 2] - pAmpang3[j + 2]) /
(pAmpang1[j - 2] + pAmpang3[j + 2] - (pAmpang2[j] << 1));
pCoord[k] = c - tmp * tri_list_root2[0][pAmpang2[j + 1]];
pCoord[k + 1] = r - tmp * tri_list_root2[1][pAmpang2[j + 1]];
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 2:
if (pAmpang2[j] > pAmpang2[j - 2] && pAmpang2[j] >= pAmpang2[j + 2])
{
pEdge[c] = 255;
pCoord[k] = c + tri_list[0][pAmpang2[j + 1]] * (pAmpang2[j - 2] - pAmpang2[j + 2]) /
(pAmpang2[j - 2] + pAmpang2[j + 2] - (pAmpang2[j] << 1));
pCoord[k + 1] = (float)r;
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 6:
if (pAmpang2[j] >= pAmpang2[j - 2] && pAmpang2[j] > pAmpang2[j + 2])
{
pEdge[c] = 255;
pCoord[k] = c - tri_list[0][pAmpang2[j + 1]] * (pAmpang2[j - 2] - pAmpang2[j + 2]) /
(pAmpang2[j - 2] + pAmpang2[j + 2] - (pAmpang2[j] << 1));
pCoord[k + 1] = (float)r;
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 3:
if (pAmpang2[j] >= pAmpang1[j + 2] && pAmpang2[j] > pAmpang3[j - 2])
{
pEdge[c] = 255;
const float tmp = (float)(pAmpang3[j - 2] - pAmpang1[j + 2]) /
(pAmpang1[j + 2] + pAmpang3[j - 2] - (pAmpang2[j] << 1));
pCoord[k] = c + tmp * tri_list_root2[0][pAmpang2[j + 1]];
pCoord[k + 1] = r + tmp * tri_list_root2[1][pAmpang2[j + 1]];
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
case 7:
if (pAmpang2[j] > pAmpang1[j + 2] && pAmpang2[j] >= pAmpang3[j - 2])
{
pEdge[c] = 255;
const float tmp = (float)(pAmpang3[j - 2] - pAmpang1[j + 2]) /
(pAmpang1[j + 2] + pAmpang3[j - 2] - (pAmpang2[j] << 1));
pCoord[k] = c - tmp * tri_list_root2[0][pAmpang2[j + 1]];
pCoord[k + 1] = r - tmp * tri_list_root2[1][pAmpang2[j + 1]];
pCoord[k + 2] = angle_list[pAmpang2[j + 1]];
}
break;
default:
break;
}
}
}
}
ts->SetFinishFlag(i);
}, &_ang, &edge, &coordinate, &ts, i);
f.detach();
}
ts.WaitThreadFinish(1);
vector<Mat> vPlane;
split(amp_ang, vPlane);
vPlane[0].copyTo(gradient);
}
3. 条纹边缘定位
准备工作已完成, 接下来便是条纹边缘定位. 写一个函数专门来做这件事情. 这里再贴一次图方便观看
一个条纹有两个边缘, 如果从左到右看, 黑 条纹边缘是先经过白到黑. 再经过黑到白. 这个从白到黑顺序就是梯度的方向. 所以从左到右, 分别以不同的梯度方向拟合一次直线, 各直线间自然就对应了黑白条纹
3.1 确定边缘可能的位置
为了确定左右边缘的位置, 可以先大概估计边缘所在区域, 这个区域用一个叫 Mask (翻译成蒙板也行) 的图像表示, 代码片段如下
// 下面两个卷积核和 Sobel 类似
const Mat k1 = (Mat_<float>(3, 3) << 2, 0, -2, 2, 0, -2, 2, 0, -2); // 左->右, 白到黑
const Mat k2 = -k1; // 左->右, 黑到白, 也就是从右->左, 白到黑
Mat left_mask;
Mat right_mask;
const int mask_threads = 2;
CThreadSync ts(mask_threads);
for (int i = 0; i < mask_threads; i++)
{
std::thread f([img_gray, k1, k2](Mat * img_mask, CThreadSync * ts, int i)
{
filter2D(img_gray, *img_mask, img_gray.depth(), 0 == i? k1: k2);
threshold(*img_mask, *img_mask, 128, 255, THRESH_BINARY | THRESH_OTSU);
ts->SetFinishFlag(i);
}, 0 == i? &left_mask: &right_mask, &ts, i);
f.detach();
}
ts.WaitThreadFinish(1);
上面代码中, filter2D 有点类似于 Sobel 的功能
可以看到, 黑条纹左边缘在 left_mask 内, 黑条纹右边缘在 right_mask 内, 这样就大致确认了各条纹边缘的范围. 至于最左面的那些干扰, 后面会解决
3.2 边缘检测
这个就不多讲了, 可以参考 基于多项式插值的亚像素边缘定位算法, 以下是代码片段
Mat img_edge;
Mat img_gradient;
Mat img_coordinate;
PolynomialEdge(img_gray, img_edge, img_gradient, img_coordinate, m_nEdgeThres, 2);

和上面预期的一样, 边缘在相应的 Mask 区域内部
3.3 投影
上面的 Mask 还有一个功能, 就是可以确定每条边缘在图上的间隔点. 如果把 Mask 列上的非 0 元素数量数出来, 边缘的地方数量会远大于间隔的地方累计数量. 把代码贴出来, 读代码也许更形象一点
const Mat img_mask = (0 == i? left_mask: right_mask);
// 边缘 Mask 投影
vector<int> mask_projection(img_mask.cols, 0);
for (int r = 0; r < img_mask.rows; r++)
{
for (int c = 0; c < img_mask.cols; c++)
{
if (img_mask.at<BYTE>(r, c))
{
mask_projection[c]++;
}
}
}
// 如果累积数量小于 条码高度的 30%, 则将其设置为 0
for (auto &it : mask_projection)
{
if (it < img_mask.rows * 0.3)
{
it = 0;
}
}
这样一顿操作之后, mask_projection 中的元素值如下
有 Mask 的列数值为条码高度, 其他间隔地方的值为 0
3.4 取得边缘点坐标并拟合直线
上面既然已提到 Mask, 那这里就是用 Mask 的时候了, 将边缘图像 img_edge 与 left_mask 相与, 余下的就自然是左边缘图像. 定位一条直线的时候, 用到了投影来跳过当前的位置, 从而到下一条线的前面
vector<CFitLine> left_edges; // 向量中的元素为左边缘直线
vector<CFitLine> right_edges; // 向量中的元素为右边缘直线
ts.ResetThreadCount(mask_threads);
for (int i = 0; i < mask_threads; i++)
{
std::thread f([img_edge, img_coordinate, left_mask, right_mask](vector<CFitLine> * edge_ptr, CThreadSync * ts, int i)
{
const Mat img_mask = (0 == i? left_mask: right_mask);
vector<int> mask_projection(img_mask.cols, 0);
for (int r = 0; r < img_mask.rows; r++)
{
for (int c = 0; c < img_mask.cols; c++)
{
if (img_mask.at<BYTE>(r, c))
{
mask_projection[c]++;
}
}
}
for (auto &it : mask_projection)
{
// 如果累积数量小于 条码高度的 30%, 则将其设置为 0
if (it < img_mask.rows * 0.3)
{
it = 0;
}
}
edge_ptr->reserve(320);
const int angle = (0 == i? 0: 180); // 梯度方向
const Mat edge_and_mask = img_edge & img_mask; // 边缘图像与 Mask 相与, 剩下 Mask 内部边缘图像
int col_start = 4;
while (TRUE)
{
vector<Point2f> edge_pts;
edge_pts.reserve(img_edge.rows);
// 取出所有满足条件的边缘点, 放到 edge_pts 中
for (int r = 0; r < edge_and_mask.rows; r++)
{
for (int c = col_start; c < edge_and_mask.cols; c++)
{
if (edge_and_mask.at<BYTE>(r, c))
{
// 这里取出来的便是亚像素坐标, v[2] 为梯度的方向, (v[0], v[1]) 为边缘坐标
const auto v = img_coordinate.at<Vec3f>(r, c);
if (angle == v[2])
{
edge_pts.push_back(Point2f(v[0], v[1]));
// 跳出循环, 不然找到下一条线的点了
break;
}
}
}
}
CFitLine fit_line(img_edge.rows / 3);
if (!fit_line.Fit(edge_pts))
{
break;
}
// 斜率太小, 则不是竖直的直线
if (fabs(fit_line.k) > 10)
{
edge_ptr->push_back(fit_line);
// 以下便是将起始坐标跳到下一个间隔, 从而定位一下条边缘直线
col_start = cvRound(fit_line.GetCenter().x + 2);
}
else
{
col_start += 4;
}
// 计算下一个起点
for (int c = col_start; c < left_mask.cols - 1; c++)
{
if (0 == mask_projection[c] < 0 != mask_projection[c + 1])
{
col_start = c;
break;
}
}
}
ts->SetFinishFlag(i);
}, 0 == i? &left_edges: &right_edges, &ts, i);
f.detach();
}
ts.WaitThreadFinish(1);
#ifdef _DEBUG
for (const auto &it : left_edges)
{
line(img_src, it.ptStart, it.ptEnd, CV_RGB(255, 55, 55), 1, LINE_AA);
}
for (const auto &it : right_edges)
{
line(img_src, it.ptStart, it.ptEnd, CV_RGB(55, 255, 55), 1, LINE_AA);
}
#endif // _DEBUG
完成后效果
现在有一个问题是最左边的线并不是我们想要的, 不过不影响, 下面的代码和后面在计算宽度的时候会去除
int left_edge_count = (int)left_edges.size();
int right_edge_count = (int)right_edges.size();
// 如果条码左面 右边缘在第一个左边缘的左侧, 则弃之
for (int i = right_edge_count - 1; i > 0; i--)
{
if (left_edges.front().GetCenter().x > right_edges.front().GetCenter().x)
{
right_edge_count--;
right_edges.erase(right_edges.begin());
}
else
{
break;
}
}
// 如果条码左面 出现了连续的左边缘, 则弃之
for (int i = 0; i < left_edge_count - 1; i++)
{
if (left_edges[i + 1].GetCenter().x < right_edges.front().GetCenter().x)
{
left_edge_count--;
left_edges.erase(left_edges.begin());
i--;
}
else
{
break;
}
}
// 如果条码右面 左边缘在最后一个右边缘的右侧, 则弃之
for (int i = left_edge_count - 1; i > 0; i--)
{
if (left_edges.back().GetCenter().x > right_edges.back().GetCenter().x)
{
left_edge_count--;
left_edges.pop_back();
}
else
{
break;
}
}
// 如果条码右面 出现了连续的右边缘, 则弃之
for (int i = right_edge_count - 1; i > 0; i--)
{
if (right_edges[i - 1].GetCenter().x > left_edges.back().GetCenter().x)
{
right_edge_count--;
right_edges.erase(right_edges.begin() + i);
}
else
{
break;
}
}
完成后, 将左右边缘直线依次放到一个 vector 中, 后面解码的时候使用
vector<CFitLine> bar_edges;
if (left_edges.size() && right_edges.size())
{
bar_edges.insert(bar_edges.end(), left_edges.begin(), left_edges.end());
bar_edges.insert(bar_edges.end(), right_edges.begin(), right_edges.end());
// 排序是因为有可能 Quiet zone 之外的线不是交替的
sort(bar_edges.begin(), bar_edges.end(), [](const CFitLine & l1, const CFitLine & l2)
{
return l1.GetCenter().x < l2.GetCenter().x;
});
}
这样, 从左到右, 就是每个黑条纹两边的边缘直线. 至此, 边缘定位完毕
五. 计算黑白条纹宽度并转换成编码
在上面已经得到了条纹边缘直线, 接下来就用这些直线计算出每个条纹的宽度, 包括白条纹. 虽然前面只说是黑条纹, 但是白条纹也是在两条线之间的
1. 计算黑白条纹宽度
用相邻两线坐标相减, 即可得到各条纹宽度, 条纹数量 = 边缘直线数量 - 1
const int edge_lines = (int)bar_edges.size();
int bars = edge_lines - 1;
// 相邻两条线之间的条纹宽度
vector<double> bar_width;
bar_width.reserve(bars);
int former = 0;
for (int i = 0; i < edge_lines - 1; i++)
{
// 相邻两条线之间的平均宽度
const double w = (bar_edges[i + 1].ptStart.x - bar_edges[i - former].ptStart.x +
bar_edges[i + 1].ptEnd.x - bar_edges[i - former].ptEnd.x) * 0.5;
former = 0;
if (w > 2)
{
bar_width.push_back(w);
}
else
{
bars--;
former = 1;
}
}
auto ordered_width = bar_width;
sort(ordered_width.begin(), ordered_width.end());
// 排序后的倒数第三个宽度, 因为最后两个宽度有可能是 Quiet zone 宽度
const int back_3 = bars - 3;
// 去除 Quiet Zone 之外的干扰
for (int i = bars >> 1; i >= 0; i--)
{
if (bar_width[i] > ordered_width[back_3] * 2)
{
for (int j = i; j >= 0; j--)
{
bars--;
bar_width.erase(bar_width.begin() + j);
}
break;
}
}
for (int i = bars - 1; i > (bars >> 1); i--)
{
if (bar_width[i] > ordered_width[back_3] * 2)
{
for (int j = bars - 1; j >= i; j--)
{
bars--;
bar_width.erase(bar_width.begin() + j);
}
break;
}
}
现在 bar_width 中就是所有条纹的宽度
2. 计算单位条纹宽度
Code128 条码一个字符由 三黑三白交替 共六个条纹来编码, 不同的宽度从小到大分别代表了 1, 2, 3, 4. 由 1, 2, 3, 4 四个数不同的组合就编码了不同的字符, 比如 111323 在 BARCODE_128_A 或者 BARCODE_128_B 中就表示字符 ‘A’. 由于图像的分辨率的差异, 相同的条码在不同的条件下拍出来各条纹像素宽度是不一样的. 这就要找到各种宽度条纹在同一张图像中的宽度比例关系来决定 1, 2, 3, 4, 比如最窄的宽度是 8 个像素, 这个条纹就代表 1, 另一个宽度为 16, 这个就代表 2, 依此类推
一个完整的条码由 起始码 + 数据码 + 检验码 + 结束码 组成, 除去结束码由 7 个条纹组成外, 其他都是 6 个条纹. Code128 编码有一个很巧妙的地方, 所有 6 个编码之和为 11, 结束码前 6 位为 11, 最后一位为 2, 所以结束码之和是 13. 比如 ‘A’ 的编码为 111323, 全部相加等于 11
所谓 单位条纹宽度, 就是在一张图像中代表 1 的像素宽度. 知道了一个编码和为 11, 就可以用总的像素宽度计算单位宽度
double code_width = 0; // 除停止码外的编码总宽度
double stop_width = 0; // 停止码总宽度
for (int i = 0; i < bars - 7; i++)
{
if (bar_width[i] > 0)
{
code_width += bar_width[i];
}
}
for (int i = bars - 7; i < bars; i++)
{
if (bar_width[i] > 0)
{
stop_width += bar_width[i];
}
}
// 编码的字符数量(包括启始码, 校验码), 一个字符由 6 个条纹组成, 所以要除以 6
const double code_chars = max(1.0, (bars - 7) / 6.0);
// 单位宽度
const double unit_width = (code_width / code_chars / 11.0 + stop_width / 13.0) * 0.5;
3. 将条纹宽度转换成基本编码数字
有了单位宽度, 其他的宽度就容易转换成相对应的基本编码数字(1, 2, 3, 4)了
// 基本编码数字
vector<int> bin_code;
bin_code.reserve(bars);
for (auto &it : bar_width)
{
const double scale = it / unit_width;
int num = max(1, cvRound(scale));
if (num > 4)
{
if (scale < 5)
{
num = 4;
}
else
{
break;
}
}
bin_code.push_back(max(1, cvRound(scale)));
}
经过上面的转换 bin 里面就是基本编码元素, 1, 2, 3, 4 这样的数字了

4. 将基本编码数字转换成字符编码
每 6 个数字一组, 将其转换成整型数字, 存到 char_keys 中, 其中结束码要单独加一位
// 字符编码
vector<int> char_keys;
char_keys.reserve(bars / 6 + 1);
bars = (int)bin_code.size();
for (int i = 0; i < bars - 1; i += 6)
{
const int code_key =
bin_code[i + 0] * 100000 + bin_code[i + 1] * 10000 +
bin_code[i + 2] * 1000 + bin_code[i + 3] * 100 +
bin_code[i + 4] * 10 + bin_code[i + 5];
char_keys.push_back(code_key);
}
// Stop Code
if (bars > 7)
{
const int stop_key = char_keys.back() * 10 + bin_code[bars - 1];
char_keys.back() = stop_key;
}
转换后, char_keys 中的元素就是字符编码
六. 解码
有了每个字符的编码, 只需要一个对照表, 就可以解码出相应的字符了
1. 三种类型的编码
话说 Code128 有三种类型, 分别是 A, B C
- A 型: 编码了 标准数字和大写字母,控制符,特殊字符
- B 型: 编码了 标准数字和大写字母,小写字母
- C 型: 编码了 [00]-[99]的数字对集合, 共100个
所以, 一般都是根据实际需要选择相应的编码, 也可以三种类型混合编码.
- 有控制字符, 特殊字符就需要使用 A 或 混合使用 A
- 有小写字母, 就需要使用 B 或 混合使用 B
- 使用 C 一般是全数字或者有成对的偶数位数字. 如果数字是奇数位, 则只使用 C 不能完成编码, 因为多出来的一个数字不能由 C 编码, 这时要使用 A 或 B 与 C 混合编码
- C 型一个编码能表示两个数字字符, 数据密码更大
2. 编码对照表
如果用数组的方式的话, 这个问题比较大, 需要一个一个的去查找, 或者下标不连续, 所以可以用标准库中的 map, 编码为 key, 字符为 value, 这样配对之后, 查找就很方便快速了
std::map<int, TCHAR> CODE128_A;
std::map<int, TCHAR> CODE128_B;
std::map<int, CString> CODE128_C;
std::map<int, int> CODE128_D;
多出来一个 CODE128_D, 这个不是必须的, 只是为了方便校验用, 里面只是将 CODE128_C 中的数字对字符串转换成对应的整数, 后面的代码会看到用到 CODE128_D 的地方
以下是初始化 map 的一些代码片段
CODE128_A[212222] = ' ';
CODE128_A[222122] = '!';
CODE128_A[222221] = '"';
CODE128_A[121223] = '#';
CODE128_A[121322] = '$';
CODE128_A[131222] = '%';
CODE128_A[122213] = '&';
CODE128_A[122312] = '\'';
CODE128_B[111422] = '`';
CODE128_B[121124] = 'a';
CODE128_B[121421] = 'b';
CODE128_B[141122] = 'c';
CODE128_B[141221] = 'd';
CODE128_B[112214] = 'e';
CODE128_B[112412] = 'f';
CODE128_B[122114] = 'g';
CODE128_C[212222] = _T("00");
CODE128_C[222122] = _T("01");
CODE128_C[222221] = _T("02");
CODE128_C[121223] = _T("03");
CODE128_C[121322] = _T("04");
CODE128_C[131222] = _T("05");
CODE128_C[122213] = _T("06");
CODE128_C[122312] = _T("07");
CODE128_C[132212] = _T("08");
for (const auto &it : CODE128_C)
{
CODE128_D[it.first] = _ttoi(it.second);
}
假设我们已经得到了一个编码 111323, 只需要将 111323 作为 key, CODE128_A[111323] 得到的就是字符 ‘A’. 将上面的 char_keys 中的各编码按相同的方式来一遍, 就得到了所有的字符, 组合起来就是解码的内容了. 这样讲也不完全对, 因为还有起始码, 校验码之类的还没有处理. 下面继续
3. 解码
前面讲过一个完整的条码由 起始码 + 数据码 + 检验码 + 结束码 构成, 那 char_keys 中的第一个编码就是起始码, 需要用起始码来判断用哪种类型来解码. 就相当于告诉你用哪个密码本, 密码本拿错了, 你得到情报就是错的. 那如何知道用哪个密码本? 起始码就是干这个事的
起始码有三个, 分别是:
- 211412: CODE128_A
- 211214: CODE128_B
- 211232: CODE128_C
知道了起始码后, 就用对应的密码本解码, 还是以 111323 为例
- CODE128_A[111323] = ‘A’
- CODE128_B[111323] = ‘A’
- CODE128_C[111323] = “33”
那接下来就可以一个编码一个编码的顺序解码, 再将解码后的字符组合起来, 把上面的 char_keys 内存中的数据再贴一次
可以看到, 第一个起始码是 211214, 要用 CODE128_B 解码, 顺序解码下去是 ND-HP- , 再往下就有问题了, 元素[7] 中的编码是 113141, 在CODE12B_B 中不能表示字符, 而它表示的是另外一个意思, 这是个特殊的编码. 它的作用是告诉你接下来要换密码本. 那换哪个密码本?, 这里是换成 CODE12B_C. 你可能猜到了, 这个是混合编码. 所以有三个提示换密码本的特殊编码, 分别是
- A -> B: 114131
- A -> C: 113141
- B -> A: 311141
- B -> C: 113141
- C -> A: 311141
- C -> B: 114131
总结出来就是:
- 切换到 A: 311141
- 切换到 B: 114131
- 切换到 C: 113141
所以是三个. 接着对 char_keys 中的元素用 CODE12B_C 解码
- 元素[8] 212222: “00”
- 元素[9] 121223: “03”
到这里, 需要解码的字符全部完成了, 组合起来就是 ND-HP-0003
最后两个编码没有解码是因为倒数第二个是校验码, 最后一个是结束码. 这两个并不是条码要表示的数据. 那有什么用呢? 结束码很好解释, 表示编码到这里就没有了. 那校验码又是什么鬼
4. 校验
有可能你在计算单位宽度的时候出了问题而不知道, 你怎么保证你所解码的数据是对的呢? 或者生成条码的时候编码是正确的呢? 校验码就是做这个用的, 为数据的正确性加一个保险. 就好比你的银行卡号要和密码匹配才能取款类似, 解码或者需要生成条码的数据是卡号, 校验码就是密码. 校验码是一个公式计算出来的, 公式如下
校验和 = (编码方式校验码 + 各编码 在密码本中的序号 × 各编码 在 条码 中的序号)
余数 = 校验和 % 103 (这里是取余数的意思)
校验编码 = 余数所对应的 数对 在 CODE128_C 中对应的编码(key)
编码方式校验码有三个
- CODE128_A: 103
- CODE128_B: 104
- CODE128_C: 105
在 CODE128_C 中有分别对应的编码 key, 只是这时候用 CODE128_D 中的对应的数字会更方便一点
CODE128_C[211412] = _T("103"); // StartA
CODE128_C[211214] = _T("104"); // StartB
CODE128_C[211232] = _T("105"); // StartC
// CODE128_D 只是为了方便校验而创建的一个对应于 CODE128_C 的密码本, 因为 CODE128_C 中是字符串, 不方便计算
CODE128_D[211412] = 103; // StartA
CODE128_D[211214] = 104; // StartB
CODE128_D[211232] = 105; // StartC
现在以 ND-HP-0003 举例说明如何操作, 再再贴一次内存图
校验和 = CODE128_D[211214]; // 此时校验和等于 104
校验和 += (CODE128_D[113321] * 1); // 此时校验和等于 150, CODE128_D[113321] == 46
校验和 += (CODE128_D[112313] * 2); // 此时校验和等于 222, CODE128_D[112313] == 36
校验和 += (CODE128_D[122132] * 3); // 此时校验和等于 261, CODE128_D[122132] == 13
...
校验和 += (CODE128_D[113141] * 7); // 此时校验和等于 1432, CODE128_D[113141] == 99
...
校验和 += (CODE128_D[121223] * 9); // 此时校验和等于 1459, CODE128_D[121223] == 3
校验和计算完之后要除以 103 取余
余数 = 校验和 % 103; // 此时校验和等于 17
有两种方式检验
- CODE128_D[char_keys[10]] == 17, 余数也是 17, 校验正确
- 用 17 反过去看密码本中哪个编码对应 17. 经查, CODE128_D[123221] = 17, 所以正确的校验编码应该是 123221, 再看内存数据 char_keys[10] 正好是 123221, 校验正确
六. 可能遇到的问题
1. 如果条码在图像中是反过来的怎么办
如果想要解码反过来的条码, 还是可以像正常条码一样操作, 只是到了 [基本编码数字转换成字符编码] 后, 要判断一下起始码是不是结束码反过来就行了. 结束码正常是 2331112, 当反过来后, 起始码会变成 211133, 而这个编码在密码本中是没有的, 所以就知道条码反过来了. 这时, 只需要将 bin_code 向量逆序排列, 再重新转换成字符编码就可以了
2. 如果条码在图像中是倾斜的怎么办
OpenCV 在 Detect 函数后, 会返回条码的四个角点坐标, 四个坐标的顺序是 左下角, 左上角, 右上角, 右下角, 所以只需要计算一下就知道旋转了多少度, 旋转到水平后, 再把条码位置的图像取出来就可以了. 比如下面这张图
定位完成后是这样的
这时, 可以把用四个角点坐标生成 一个 RotatedRect, 和一个 BoundingRect, RotatedRect 用于计算条码的宽度与高度, BoundingRect 用于裁切图像. 将裁切后的图像旋转, 旋转的角度便是 左上与右上角两点生成的角度(注意这里不能用 RotatedRect 的角度, 当角度比较大的时候, RotatedRect 计算的是短边的角度), 旋转后再将图像裁切一次, 裁切的高度与宽度是 RotatedRect 的宽度与高度
// 取得条码倾斜角度
const double angle = Get2PtsAngle(corner_pts[nIdx + 1], corner_pts[nIdx + 2], FALSE);
const RotatedRect rotate_rect = minAreaRect(di->corners);
Rect2i bound_rect = boundingRect(di->corners);
const double r = sqrt(bound_rect.width * bound_rect.width + bound_rect.height * bound_rect.height);
bound_rect.x -= cvRound((r - bound_rect.width) * 0.5);
bound_rect.width += cvRound(r - bound_rect.width);
Mat img_rgn; // 条码区域图像, 有可能条码不是水平状态, 所以需要旋转之后再取子图像
GetSubImage(img_src, img_rgn, bound_rect);
cvtColor(img_rgn, img_rgn, COLOR_BGR2GRAY);
// 将条码旋转到水平状态
ImgRotation(img_rgn, img_rgn, Point2i(img_rgn.cols >> 1, img_rgn.rows >> 1), angle, INTER_LINEAR);
// 条码宽度与高度
const int w = cvRound(max(rotate_rect.size.width, rotate_rect.size.height));
const int h = cvRound(min(rotate_rect.size.width, rotate_rect.size.height));
const Rect2i barcode_rect(((img_rgn.cols - w) >> 1) + 2, ((img_rgn.rows - h) >> 1) + 2, w - 4, h - 4);
Mat img_barcode; // 旋转到的条码图像
GetSubImage(img_rgn, img_barcode, barcode_rect);
校正后如下图
3. 如果条码在图中是透视倾斜的怎么办
如果相机是倾斜的话, 拍出来的图就有透视的效果, 如下图
这样的图要先做透视校正, 校正后再检测就可以了. 可能用到的函数有 getPerspectiveTransform 和 warpPerspective
4. 如果图像分辩率不够怎么办
如果条码离相机太远的时候, 条码间隔就会变得很小, 这时边缘定位的时候 Mask 会有问题, 可以将图像放大, 间隔自然就变大了
七. 效果测试
贴一些测试的效果图, 箭头为条码的方向
…
…
…
…
…
八. 条码生成
如果上面的解码看懂了, 那生成条码自然不在话下了. 只是要注意一些规则, 原则是以最少的编码数量为优
1. 生成对应字符串的编码
如果不用混合编码, 就依照密码本组合编码. 假设要生成 ABCDE. 这个全是大写字符, 用 CODE128_A 就好(也可以用 CODE128_B) . ‘A’ 对应的编码是 111323, B 对应用编码是 131123, 依次类推. 然后把编码放到一个 vector 容器中, 还要在前面插入起始码, 后面添加校验码, 结束码. 校验码和解码是一样的原理, 完成后内存中的值如下图
如果是想要混合编码, 比如 aBc-1234567, 当然这个可以用 CODE128_B 全部编码完成(因为 CODE128_B 包含了大写字母, 小字字母与数字), 只是用混合编码的时候, 需要的编码数量要少一些, 现在用混合编码. 因为有成对的数字, 所以需要用到 CODE128_C, 因为开始是字母, 且是小写字母, 所以起始码是 211214, 然后 ‘a’ 对应的编码是 121124, …, 到了数字 ‘1’ 的时候, ‘1’ 后面还有数字字符, 所以在字符 ‘-’ 后面要切换密码本, 这样就需要在 ‘-’ 对应编码后入切换到 CODE128_C 的编码 113141. 切换后两个数字对应一个编码, “12” 对应的编码是 112232, “34” 对应的编码是 131123, …, 后面单吊一个 ‘7’, 肯定不能用 CODE128_C, 又要换密码本, 所以要在 “56” 对应的编码后加入切换到 CODE128_B 的编码 114131. 再把 ‘7’ 的编码 312131 加到后面, 后面在加上校验码和结束码, 这样所有的编码如下
上图中 元素[5] 与 元素[9] 就是两个需要切换密码本的代码
2. 在图中画出相应宽度的条纹
生成一张空白图, 填充为白色, 按编码宽度画条纹就可以了
// 两个 10 分别是 条码前后的空白区域
Mat img_dst(64 + 44, (keys * 11 + 2 + 10 + 10) * unit_width, CV_8UC3);
img_dst.setTo(Scalar::all(255));
for (int i = 0; i < keys; i++)
{
// 编个编码中的条纹宽度
vector<int> code_width;
int tmp = encode_keys[i];
const int bins = (i == keys - 1)? 7: 6;
for (int j = 0; j < bins; j++)
{
code_width.push_back(tmp % 10);
tmp /= 10;
}
for (int j = 0; j < bins; j++)
{
// 这里取逆序是因为上面的 code_width 计算宽度的时候是反过来的
const int k = bins - j - 1;
rectangle(img_dst, Rect2i(pos, 4, code_width[k] * unit_width, 64),
j & 0x01? Scalar::all(255): Scalar::all(0), FILLED);
pos += (code_width[k] * unit_width);
}
}
最后再在条码的下面写上相应的字符
USES_CONVERSION;
putText(img_dst, W2A(str), Point2i(11 * unit_width, 100),
FONT_HERSHEY_COMPLEX, 1,
CV_RGB(0, 0, 0), 2, LINE_AA);
 文章来源:https://www.toymoban.com/news/detail-757904.html
文章来源:https://www.toymoban.com/news/detail-757904.html
九. 代码下载
如果看了还不会需要看完成的代码的话, 可以下载文章来源地址https://www.toymoban.com/news/detail-757904.html
- OpenCV 4.7.0
- 基于 OpenCV 的 Code128 条码识别与生成
到了这里,关于基于 OpenCV 的 Code128 条码识别与生成的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!