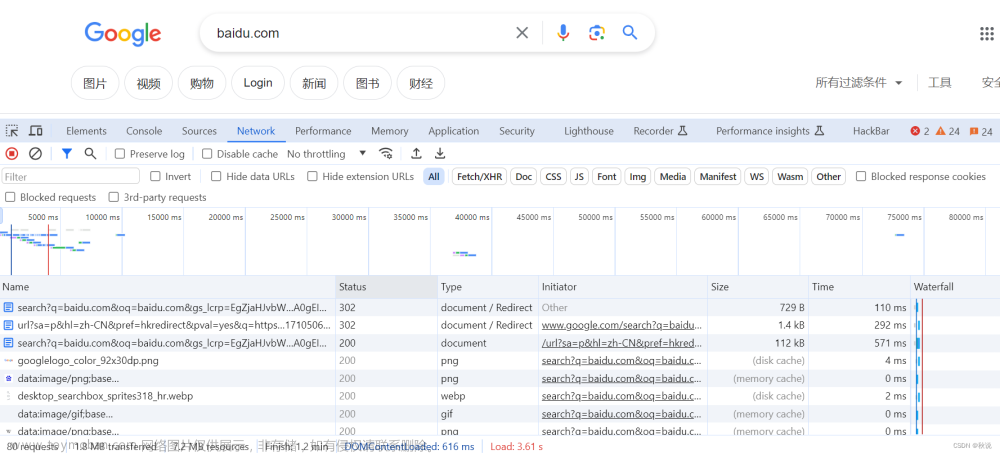
HTTP响应状态码响应状态码
下面来看下详细的状态码数值和说明:
200系列:
-
200 OK:这个是最常见的,也是爬虫工程师最喜欢的,代表你本次的请求顺利拿到了响应,没有任何问题
-
201 Created:201代表创建成功。通常是指浏览器或爬虫给服务器上传数据,服务器接受并验证数据没有问题之后,服务器返回客户端一个201,代表成功。提交数据,通常是POST方法提交
-
202 Accepted:服务器拿到了数据,但是还没处理好结果,所以先发回一个202.这个状态码一般在爬虫中看不到,但是适合在异步操作的情况下返回。
300系列
-
301 Moved Permanently:当前资源的网址永久性迁移,并且会给你一个新的网址。值得注意的是,如果是POST请求拿到301,则下一次请求自动变成GET。
-
301 Moved Permanently:当前资源的网址永久性迁移,并且会给你一个新的网址。值得注意的是,如果是POST请求拿到301,则下一次请求自动变成GET。
-
301 Moved Permanently:当前资源的网址永久性迁移,并且会给你一个新的网址。值得注意的是,如果是POST请求拿到301,则下一次请求自动变成GET。
400系列
-
400 Bad Request:错误请求,400系列最典型的,看到这个错误,要么是请求头参数不对,要么是请求主体的内容错误。
-
401 Unauthorized:401认证错误,这个还是非常好识别的,身份无法识别或者身份权限不够,检查请求头中的身份字段信息和Cookie值。
-
403 Forbidden:禁止访问,大并发爬虫中比较容易碰到,问题很直观,你访问太多了【换IP或电脑】,或者身份权限不够【换身份信息】。
-
404 Not Found:404找不到,这个错误不用太在意,用浏览器测试几次就好,要么是你的网址写错了,要么是网址对应的网络资源无法加载【这不怪程序】。
-
405 Method Not Allowed:405方法不被允许,简单且少见的错误,意思就是你请求的姿势不对,检查请求方法,如Get、Post、Put、Delete,总有一个是对的。
500系列
-
500 Internal Server Error:网络错误,就和你断网了一样,具体点就是你的网络和网址所在网络,无法连通。
-
502 Bad Gateway:网关错误,请求出去要被网关解析目的地址并转发你的请求,这个错误就是网关不工作了,无法把你的请求发出去。这里的网关,可以理解成你的路由器或者你用的代理IP服务器。
-
503 Service Unavailable:服务不可用,这个就是目标服务器的问题了,你要做的是通知网站管理员或者等。一般情况下,国家网站部分有休息时间,例如晚上关网。商业服务器的服务不可用,大多是升级或者临时卡了,可以过段时间再试。
-
504 Gateway Timeout:网关超时,这个504和502,都是网关的问题,但是又不一样。504是你找网关转发,你默认等待180秒【3分钟】,然后网关超时了没理你;502的问题是,你压根就找不 到网关。
-
505 HTTP Version Not Supported:HTTP版本不支持,这个比较少见,但是肯定有。网站内容太新或者太旧,对客户端的http版本要求不一样。你需要检查下本次请求所使用的http版本,然后改 成网站指定版本,就可以解决这个问题。
爬虫解决HTTPS认证的解决问题认证的解决问题
解决方法:
-
验证错误,那就不验证
-
更新系统的证书库
-
更新pip库:pyopenssl和cryptography
解决思路:
-
优先使用不认证,简单暴力,还有效
-
运行或者部署爬虫时,记得同步pyopenssl和cryptography
-
操作系统越新,约不容易碰到
爬虫请求不进行不验证
请求不验证操作
requests.get('中国铁路12306网站',verify=False)
-
优势:在客户端与服务端建立连接的情况下,不会出现什么问题,数据会照常传输。
-
缺点:可能被盗。
更新系统的证书库
更新系统证书库
更新pip库
更新pip库
总结
-
优先使用不认证,简单暴力,还有效
-
运行或部署爬虫时,记得同步pyopenssl和cryptography文章来源:https://www.toymoban.com/news/detail-757927.html
-
操作系统越新,越不容易碰到SSL错误文章来源地址https://www.toymoban.com/news/detail-757927.html
到了这里,关于爬虫的http和https基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!