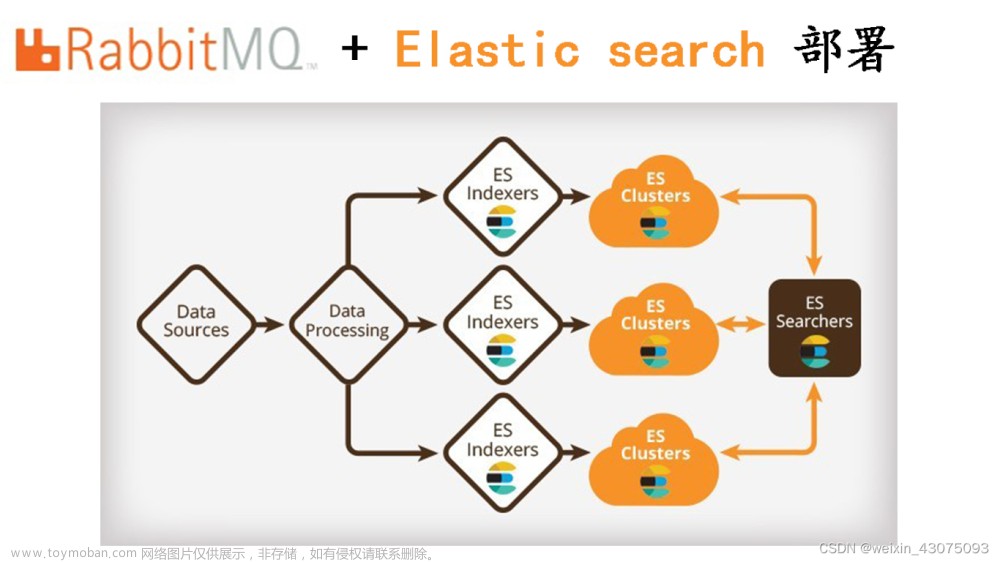
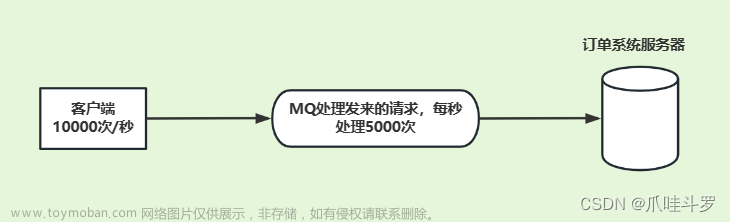
RabbitMQ默认的超时时间是30分钟,在消息消费超过30分钟后,rabbitMQ会发生错误,导致整个channel被销毁,无法继续消费
在RabbitMQ安装的终端执行
rabbitmqctl eval 'application:set_env(rabbit,consumer_timeout,180000000).'命令,将超时时间延长。
使用
rabbitmqctl eval 'application:get_env(rabbit,consumer_timeout).'可以查看设置的超时值。文章来源:https://www.toymoban.com/news/detail-758054.html
值得注意的是,这个事临时更改,永久更改需要进入rabbitmq.conf文件里修改,修改consumer_timeout参数文章来源地址https://www.toymoban.com/news/detail-758054.html
到了这里,关于设置RabbitMQ超时时间的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!