目录
一、Spark简介
(一)定义
(二)Spark和MapReduce区别
(三)Spark历史
(四)Spark特点
二、Spark生态系统
三、Spark运行架构
(一)基本概念
(二)架构设计
(三)Spark运行基本流程
四、Spark编程模型
(一)核心数据结构RDD
(二)RDD上的操作
(三)RDD的特性
(四)RDD 的持久化
(五)RDD之间的依赖关系
(六)RDD计算工作流
五、Spark的部署方式
一、Spark简介
(一)定义
Spark是一种基于内存的、用以实现高效集群计算的平台。准确地讲,Spark是一个大数据并行计算框架,是对广泛使用的MapReduce计算模型的扩展。
(二)Spark和MapReduce区别
Spark有着自己的生态系统,但同时兼容HDFS、Hive等分布式存储系统,可以完美融入Hadoop的生态圈中,代替MapReduce去执行更高的分布式计算。两者区别如图所示,基于MapReduce的计算引擎通常会将中间结果输出到磁盘上进行存储和容错;而Spark则是将中间结果尽量保存在内存中以减少底层存储系统的I/O,以提高计算速度。

Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。
(三)Spark历史
Spark最初由美国加州大学伯克利分校(UC Berkeley)的AMP实验室于2009年开发,项目采用Scala编写。是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
2010年开源。
2013年6月成为Apache孵化项目。2013年Spark加入Apache孵化器项目后发展迅猛,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm)。
2014年2月成为Apache顶级项目。Spark在2014年打破了Hadoop保持的基准排序纪录:Spark/206个节点/23分钟/100TB数据; Hadoop/2000个节点/72分钟/100TB数据;Spark用十分之一的计算资源,获得了比Hadoop快3倍的速度。
(四)Spark特点
1、运行速度快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
2、易用:Spark支持Java、Python、Scala和R等多种语言的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
3、通用性:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
4、兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。
二、Spark生态系统
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理。
现在,Spark生态系统已经成为伯克利数据分析软件栈BDAS(Berkeley Data Analytics Stack)的重要组成部分。

Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming(Structured Streaming)、MLLib和GraphX等组件。

1、Spark Core
Spark Core包含Spark最基础和最核心的功能,如内存计算、任务调度、部模式、故障恢复、存储管理等,主要面向批数据处理。Spark Core 建立在统一的抽象RDD 之上,使其可以以基本一致的方式应对不同的大数据处理场景;需要注意的是,Spark Core 通常被简称为Spark。
2、Spark SQL
Spark SQL是用于结构化数据处理的组件,允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员不需要自己编写Spark 应用程序,开发人员可以轻松地使用SOL 命令进行查询,并进行更复杂的数据分析。
3、Spark Streaming
Spark Streaming是一种流计算框架,可以支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。 Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等。
4、Structured Streaming
Structured Streaming是一种基于Spark SQL引擎构建的、可扩展且容错的流处理引擎。通过一致的API, Structured Streaming 可以使开发人员像写批处理程序一样编写流处理程序,降低了开发人员的开发难度。
5、MLlib(机器学习)
MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只需具备一定的理论知识就能进行机器学习的工作。
6、GraphX(图计算)
GraphX是Spark中用图计算的API,可认为是Pregel在Spark 上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
下表给出了在不同应用场景下,可以选用的Spark生态系统中的组件和其他框架。
| 应用场景 | 时间跨度 | 其他框架 | Spark生态系统中的组件 |
|---|---|---|---|
| 复杂的批量数据处理 | 小时级 | MapReduce、Hive | Spark |
| 基于历史数据的交互式查询 | 分钟级、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒、秒级 | Storm、S4 | Spark Streaming Structured Streaming |
| 基于历史数据的数据挖掘 | —— | Mahout | MLlib |
| 图结构数据的处理 | —— | Pregel、Hama | GraphX |
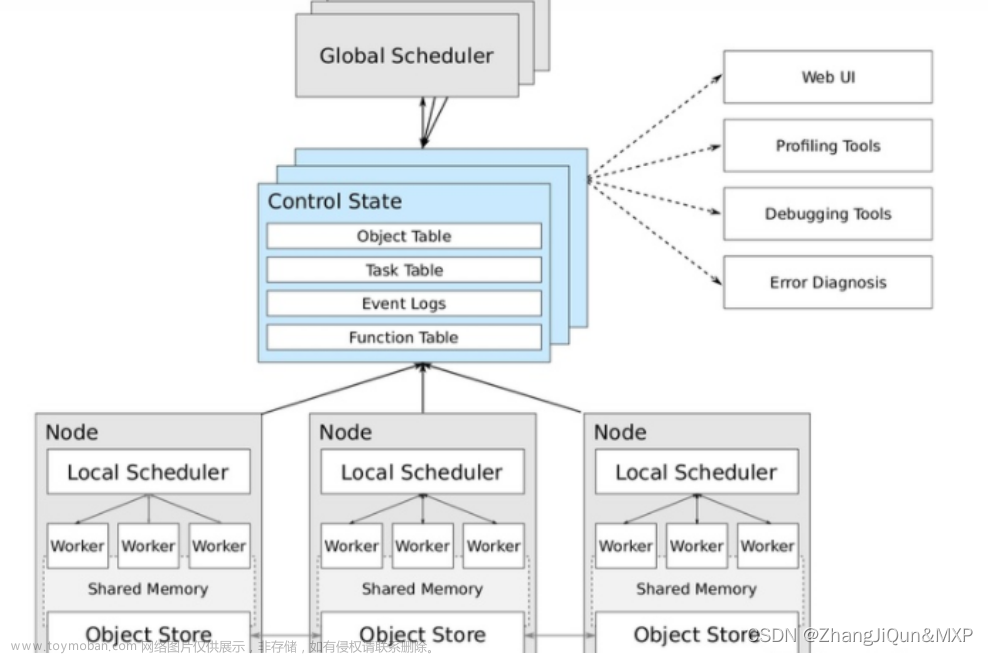
三、Spark运行架构
Spark Core包含Spark最基础和最核心的功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,当提及Spark运行架构时,就是指Spark Core的运行架构。
(一)基本概念
RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
应用(Application):用户编写的Spark应用程序。
任务( Task ):运行在Executor上的工作单元。
作业( Job ):一个作业包含多个RDD及作用于相应RDD上的各种操作。
阶段( Stage ):是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为阶段,或者也被称为任务集合,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集。
(二)架构设计
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor) 资源管理器可以自带或Mesos或YARN。

一个应用由一个Driver和若干个作业构成,一个作业由多个阶段构成,一个阶段由多个没有Shuffle关系的任务组成 当执行一个应用时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中。

(三)Spark运行基本流程
1、首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控。SparkContext对象代表了和一个集群的连接。
2、资源管理器为Executor分配资源,并启动Executor进程。
3、SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码。
4、Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源 。

四、Spark编程模型
(一)核心数据结构RDD
Spark将数据抽象成弹性分布式数据集(Resilient Distributed Dataset,RDD),RDD实际是分布在集群多个节点上数据的集合,通过操作RDD对象来并行化操作集群上的分布式数据。
RDD有两种创建方式:
(1)并行化驱动程序中已有的原生集合;
(2)引用HDFS、HBase等外部存储系统上的数据集。
(二)RDD上的操作
转换(Transformation)操作:将一个RDD转换为一个新的RDD。

行动(Action)操作:行动操作会触发Spark提交作业,对RDD进行实际的计算,并将最终求得的结果返回到驱动器程序,或者写入外部存储系统中。

(三)RDD的特性
Spark采用RDD以后能够实现高效计算的原因主要在于:
(1)高效的容错性
现有容错机制:数据复制或者记录日志
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作
(2)中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
(四)RDD 的持久化
由于Spark RDD是惰性求值的,因此,当需要多次使用同一个转换完的RDD时,Spark会在每一次调用行动操作时去重新进行RDD的转换操作,这样频繁的重算在迭代算法中的开销很大。 为了避免多次计算同一个RDD,可以用persist()或cache()方法来标记一个需要被持久化的RDD,一旦首次被一个行动(Action)触发计算,它将会被保留在计算结点的内存中并重用。

(五)RDD之间的依赖关系
1、Shuffle操作

2、窄依赖和宽依赖
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区;宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。

(六)RDD计算工作流
输入:定义初始RDD,数据在Spark程序运行时从外部数据空间读取进入系统,转换为Spark数据块,形成最初始的RDD;
计算:形成RDD后,系统根据定义好的Spark应用程序对初始的RDD进行相应的转换操作形成新的RDD;然后,再通过行动操作,触发Spark驱动器,提交作业。如果数据需要复用,可以通过cache操作对数据进行持久化操作,缓存到内存中;
输出:当Spark程序运行结束后,系统会将最终的数据存储到分布式存储系统中或Scala数据集合中。
 文章来源:https://www.toymoban.com/news/detail-758072.html
文章来源:https://www.toymoban.com/news/detail-758072.html
五、Spark的部署方式
Spark支持三种不同类型的部署方式,包括:
Standalone(类似于MapReduce1.0,slot为资源分配单位)
Spark on Mesos(和Spark有血缘关系,更好支持Mesos)
Spark on YARN文章来源地址https://www.toymoban.com/news/detail-758072.html

到了这里,关于Spark分布式内存计算框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!