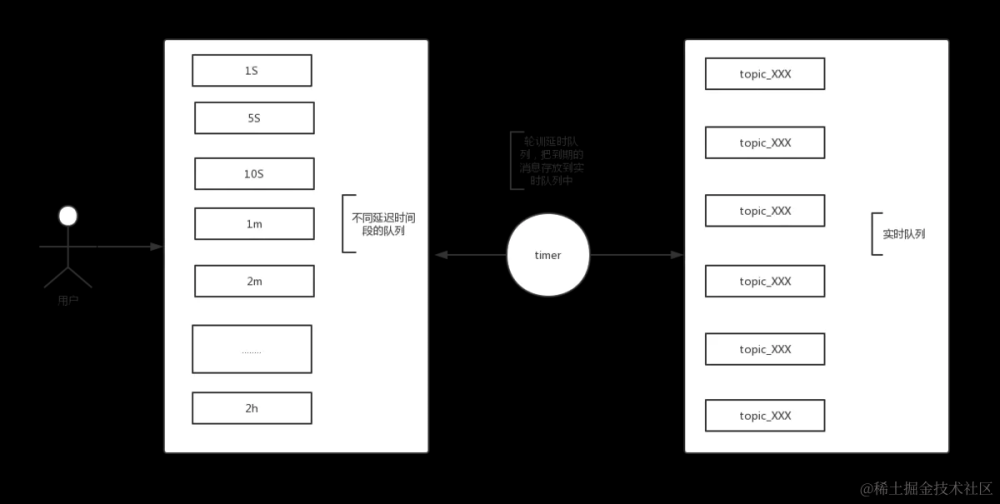
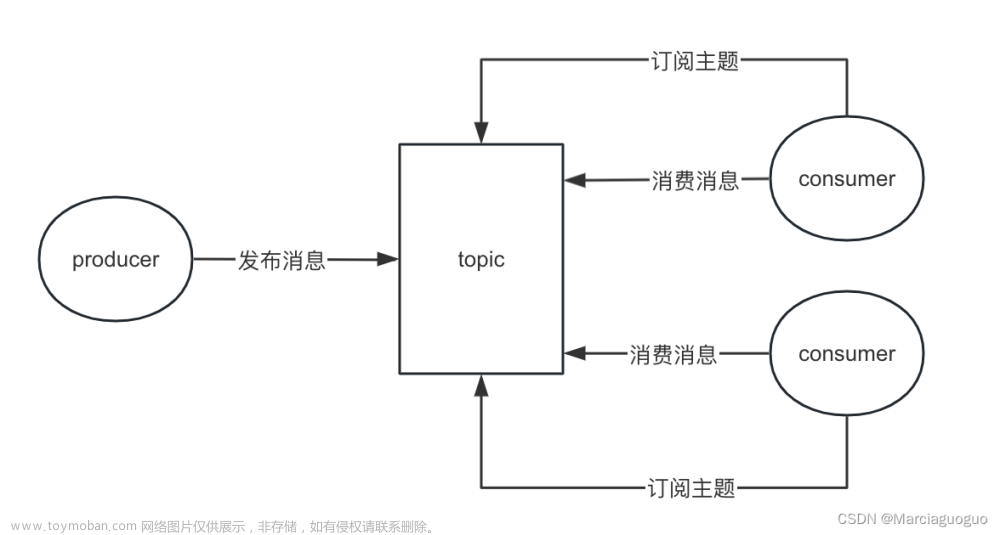
使用场景
rocketMQ用户大规模吞吐和复杂的业务中
kafka用于大数据的实时计算和采集日志
kafka

topic 中每一个分区会有 Leader 与 Follow。Kafka 的内部机制可以保证 topic 某一个分区的 Leader 与 Follow 不在同一台机器上
Leader 节点承担一个分区的读写,Follow 节点只负责数据备份
如果 Leader 分区所在的 Broker 节点宕机,会触发主从节点的切换,在剩下的 Follow 节点中选举一个新的 Leader 节点。这时数据的流入流程如下图所示

RocketMQ

RocketMQ 所有主题的消息都会写入到 commitlog 文件中,然后基于 commitlog 文件构建消息消费队列文件(Consumequeue),消息消费队列的组织结构按照 /topic/{queue} 来组织。
而 RocketMQ 在消息写入时追求极致的顺序写,所有的消息不分主题一律顺序写入 commitlog 文件, topic 和 分区数量的增加不会影响写入顺序
Kafka 的吞吐量要超过 RocketMQ,我认为这里的主要原因是单文件顺序写入很难充分发挥磁盘 IO 的性能
从集群的视角来看如下图所示

RocketMQ 默认采取的是主从同步架构,即 Master-Slave 方式,其中 Master 节点负责读写,Slave 节点负责数据同步与消费
除了在磁盘顺序写方面的差别,Kafka 和 RocketMQ 的运维成本也不同。由于粒度的原因,Kafka 的 topic 扩容分区会涉及分区在各个 Broker 的移动,它的扩容操作比较重。而 RocketMQ 的数据存储主要基于 commitlog 文件,扩容时不会产生数据移动,只会对新的数据产生影响。因此,RocketMQ 的运维成本相对 Kafka 更低
总结:
1、RocketMQ 和 Kafka 都使用了顺序写机制,但相比 Kafka,RocketMQ 在消息写入时追求极致的顺序写,会在同一时刻将消息全部写入一个文件,这显然无法压榨磁盘的性能。而 Kafka 是分区级别顺序写,在分区数量不多的情况下,从所有分区的视角来看是随机写,但这能重复发挥 CPU 的多核优势
2、Leader 节点承担一个分区的读写,Follow 节点只负责数据备份
3、RocketMQ 默认采取的是主从同步架构,即 Master-Slave 方式,其中 Master 节点负责读写,Slave 节点负责数据同步与消费
4、Kafka 和 RocketMQ 的运维成本也不同。由于粒度的原因,Kafka 的 topic 扩容分区会涉及分区在各个 Broker 的移动,它的扩容操作比较重。而 RocketMQ 的数据存储主要基于 commitlog 文件,扩容时不会产生数据移动,只会对新的数据产生影响。因此,RocketMQ 的运维成本相对 Kafka 更低
Kafka采用了多副本机制,每个Partition都有多个副本,当某个Broker节点失效时,可以通过其他副本来保证数据的可用性。而RocketMQ采用的是主从复制机制,当主节点失效时,需要进行主节点选举才能保证数据的可用性,这可能会导致一定的延迟
Kafka具有更广泛的生态系统,因为它是Apache的顶级项目,有大量的社区支持和各种集成工具。RocketMQ在中国的用户群体中较为流行,具有与阿里巴巴相关的生态系统
RocketMQ将消息持久化存储在磁盘上,确保消息的可靠性和持久性。Kafka的设计中,消息被持久化在磁盘上,但消息的消费是基于消息在内存中的高效处理
RocketMQ使用自定义的协议,支持多种编程语言。Kafka使用简单的二进制协议,并提供了各种客户端库。文章来源:https://www.toymoban.com/news/detail-758213.html
需要根据具体的使用场景和需求来选择适合的消息队列系统。如果顺序消息的支持对你非常重要,或者需要更简单的部署和管理体验,那么RocketMQ可能是一个较好的选择。如果对高吞吐量、水平扩展和数据流处理有更高的要求,或者需要更广泛的生态系统支持,那么Kafka可能更适合文章来源地址https://www.toymoban.com/news/detail-758213.html
到了这里,关于kafka和rocketMq的区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!