前言
kubelet所有知识点
- 查看kubelet当前运行
- 查看kubelet当前运行(启动文件10-kubeadm.conf)
- kubelet使用的kubeconfig
- kubelet使用的配置文件
- kubelet使用的环境变量文件
- kubelet使用的额外参数
- kubelet启动全过程 (自定义启动参数文件)
- kubelet和pause镜像的关系就是Pod内容器间通信
一、查看kubelet当前运行
1.1 查看kubelet当前运行(启动文件10-kubeadm.conf)
# 查看kubelet启动命令
systemctl status kubelet
# kubelet服务使用的cgroup信息
systemd-cgls --no-page | grep kubelet
# kubelet服务使用的cgroup占用的cpu和内存
systemd-cgtop | grep kubelet
systemctl status kubelet 可以查看到 kubelet 服务的启动命令
systemctl status kubelet -l
CGroup: /system.slice/kubelet.service # 这个进程所属的cgroup
└─922 /usr/bin/kubelet # 进程号和启动shell脚本(可执行文件)
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf # kubelet启动时连接apiserver的x509客户端证书,启动后删除
--kubeconfig=/etc/kubernetes/kubelet.conf # kubelet运行时连接apiserver的 x509 客户端证书
--config=/var/lib/kubelet/config.yaml # 配置文件
--network-plugin=cni # cni是k8s制定的标志,各个厂商自己实现 calico flannel
--pod-infra-container-image=k8s.gcr.io/pause:3.4.1 # 管理Pod网络容器的镜像,每个docker运行起来的pause和kubelet有关

systemctl status kubelet 可以查看到 kubelet 服务的启动文件
systemctl status kubelet -l
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
所有,kubelet 就是使用 /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf 文件启动的,这个文件是 kubelet 启动的源头,其他所有的都是在这个文件中引用的,这个 10-kubeadm.conf 文件包括五行:
(1) 第一行,当前 kubelet 使用的 kubeconfig /etc/kubernetes/kubelet.conf $KUBELET_KUBECONFIG_ARGS
(2) 第二行,当前 kubelet 使用的 配置文件 /var/lib/kubelet/config.yaml $KUBELET_CONFIG_ARGS
(3) 第三行,当前 kubelet 使用的 环境变量文件 /var/lib/kubelet/kubeadm-flags.env $KUBELET_KUBEADM_ARGS
(4) 第四行,当前 kubelet 使用的 额外参数 $KUBELET_EXTRA_ARGS
(5) 第五行,启动命令,后面前面四行的参数,也就是 systemctl status kubelet 看到的 /usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS

[root@m kubelet.service.d]# pwd
/usr/lib/systemd/system/kubelet.service.d
[root@mkubelet.service.d]#cat 10-kubeadm.conf
#注意:此插件仅适用于kubeadm和kubelet v1.11+
【服务】
# (1) 第一个参数 kubeconfig KUBELET_KUBECONFIG_ARGS
# (2) 第二个参数 config KUBELET_CONFIG_ARGS
Environment=“KUBELET_KUBECONFIG_ARGS=--bootstrap KUBECONFIG=/opt/kubernetes/cfg/bootstrap.KUBECONFIG--KUBECONFIG=/opt/kubernetes/cfg/KUBELET.conf”
Environment=“KUBELET_CONFIG_ARGS=--CONFIG=/opt/kubernetes/cfg/KUBELET CONFIG.yml”
# (3) 第三个参数 环境变量kubedm-flags.env KUBELET_KUBEADM_ARGS
#这是一个“kubeadminit”和“kubeadm join”在运行时生成的文件,会动态填充KUBELET_kubeadm_ARGS参数
环境文件=-/var/lib/kubelet/kubeadm-flags.env
# (4) 第四个参数 额外参数可以覆盖之前的 KUBELET_EXTRA_ARGS
#这是一个文件,作为最后的手段,用户可以使用它来覆盖kubelet参数,用户最好使用。
#而是配置文件中的.NodeRegistration.KubeltExtraArgs对象,KUBELET_EXTRA_ARGS参数应来源于该文件。
环境文件=-/etc/sysconfig/kubelet
# (5) 启动命令,使用前面四个参数,就是systemct status kubelet看到的启动命令
执行启动=
ExecStart=/usr/bin/kubelet $kubelet_KUBECONFIG_ARGS $KUBEET_CONFIG_ARGS $kubelet_KUBEADM_ARGS $CUBLET_EXTRA_ARG
1.2 kubelet使用的kubeconfig
# (1) kubelet启动的时候,连接apiserver使用bootstrap-kubelet.conf,但是启动完成后就被删除了
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
# (2) kubelet稳定运行的时候,连接apiserver使用kubelet.conf,这个可以在宿主机中被查看到
--kubeconfig=/etc/kubernetes/kubelet.conf
kubelet.conf 文件是用于 kubelet 访问 apsierver ,其实 apiserver 也需要访问 kubelet ,两者需要相互访问。
apiserver 访问 kubelet 需要双向认证(客户端认证服务端,服务端也认证客户端),其证书包括:
apiserver作为客户端 /etc/kubernetes/pki 目录下 apiserver-kubelet-client.key apiserver-kubelet-client.crt
kubelet作为服务端 /var/lib/kubelet/pki 目录下的 kubelet.key 和 kubelet.crt
kubelet 访问 apiserver 也需要双向认证(客户端认证服务端,服务端也认证客户端),其证书包括:
apiserver作为服务端 /etc/kubernetes/pki 目录下 apsierver.key apiserver.crt
kubelet作为客户端 /var/lib/kubelet/pki 目录下的 kubelet-client-current.pem 和 /etc/kubernetes/kubelet.conf
那么, kubelet 访问 apiserver 的时候 ,kubelet作为客户端 /var/lib/kubelet/pki 目录下的 kubelet-client-current.pem 和 /etc/kubernetes/kubelet.conf 两个文件有什么关系?
回答:本质是一样的。
cd /var/lib/kubelet/pki
openssl x509 -in kubelet-client-current.pem -out client.crt
openssl rsa -in kubelet-client-current.pem -out client.key
openssl x509 -in client.crt -noout -text
openssl rsa -in client.key -noout -text

cd /etc/kubernetes
cat kubelet.conf # 查看kubelet访问apiserver的x509证书
echo "xxx" | base64 --decode > client.crt
echo "xxx" | base64 --decode > client.key
openssl x509 -in client.crt -noout -text
openssl rsa -in client.key -noout -text
cd /etc/kubernetes
cat kubelet.conf # 查看kubelet访问apiserver的x509证书
x509证书本质就是集群cluster和用户user的关联关系,集群cluster的ca.crt 表示操作哪个机器,用户user 通过 证书和密钥 crt/key 完成认证集群,再通过 user/userGroup - rolebinding/clusterrolebinding - role/clusterrole 完成授权集群的资源操作
echo “xxx” | base64 --decode > client.crt


echo “xxx” | base64 --decode > client.key

openssl x509 -in client.crt -noout -text

1.3 kubelet使用的配置文件
在使用systemctl status kubelet 查看到的启动命令中,指定了 kubelet 的配置文件,即 --config=/var/lib/kubelet/config.yaml ,看一下这个文件
cat var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1 # 包名:类似java中的package
authentication: # 认证
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization: # 授权
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
# controller group 驱动,包括cgroupf和systemd两种,kubelet的cgroup驱动需要和docker的cgroup驱动保持一致
cgroupDriver: systemd
# 域名解析两个字段
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
# 健康检查地址和端口
healthzBindAddress: 127.0.0.1
healthzPort: 10248
kind: KubeletConfiguration # 资源类型 KubeletConfiguration
logging: {}
staticPodPath: /etc/kubernetes/manifests # 静态Pod yaml所在路径
# 各种超时时间(了解即可)
# 默认值:10s,设置 CPU 管理器的调和时间。例如:10s 或者 1m。 如果未设置,默认使用节点状态更新频率。
cpuManagerReconcilePeriod: 0s
# 默认值:5m0s, kubelet 在驱逐压力状况解除之前的最长等待时间。
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s # 默认值:20s,检查配置文件中新数据的时间间隔。
httpCheckFrequency: 0s # 默认值:20s,HTTP 服务以获取新数据的时间间隔。
imageMinimumGCAge: 0s
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s # 默认值:10s,指定 kubelet 向主控节点汇报节点状态的时间间隔。
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s # 默认值:1m0s,指定 kubelet 计算和缓存所有 Pod 和卷的磁盘用量总值的时间间隔。要禁用磁盘用量计算, 可设置为 0。
域名解析两个字段
–cluster-dns strings
DNS 服务器的 IP 地址,以逗号分隔。此标志值用于 Pod 中设置了 “dnsPolicy=ClusterFirst” 时为容器提供 DNS 服务。
注意::列表中出现的所有 DNS 服务器必须包含相同的记录组, 否则集群中的名称解析可能无法正常工作。至于名称解析过程中会牵涉到哪些 DNS 服务器, 这一点无法保证。 (已弃用:应在 --config 所给的配置文件中进行设置。 请参阅 kubelet-config-file 了解更多信息。)
–cluster-domain string
集群的域名。如果设置了此值,kubelet 除了将主机的搜索域配置到所有容器之外,还会为其 配置所搜这里指定的域名。 (已弃用:应在 --config 所给的配置文件中进行设置。 请参阅 kubelet-config-file 了解更多信息。)
参考文件:k8s官网中的配置文件
k8s官网中的kubelet参数列表
注意:配置文件必须是这个结构体中参数的 JSON 或 YAML 表现形式,才能确保 kubelet 可以读取该文件。
1.4 kubelet使用的环境变量文件
环境变量文件的定义和使用
-network-plugin=cni表示使用CNI(Container Network Interface)网络插件来为Kubernetes集群中的Pod分配IP地址,实现Pod之间和Pod与外部网络的通信。
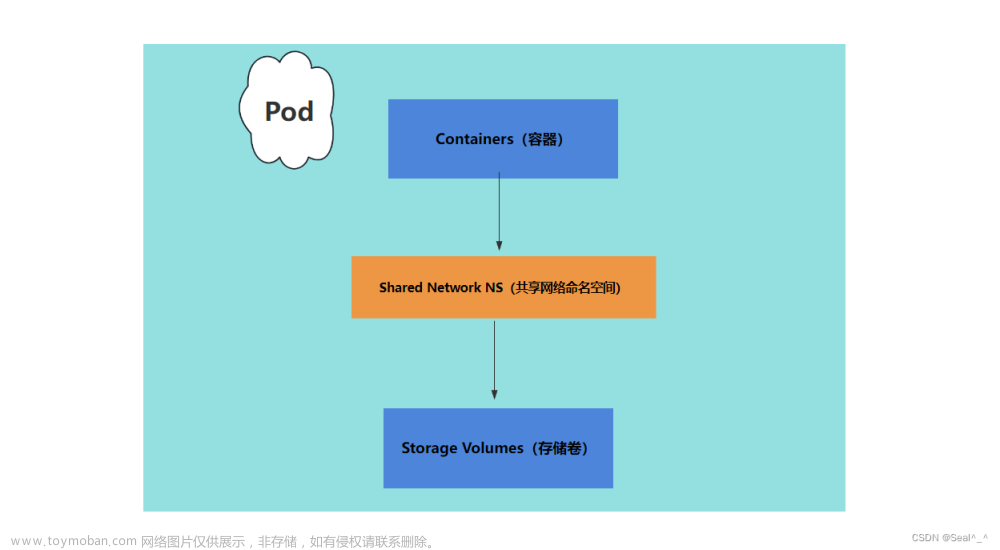
–pod-infra-container-image=k8s.gcr.io/pause:3.4.1表示指定Pod的基础设施容器镜像,这个容器镜像通常是一个无状态的容器,它负责在Pod的生命周期中一直运行,为Pod提供必要的基础服务,比如网络、存储等。Pause镜像(k8s.gcr.io/pause)是Kubernetes默认提供的Pod基础设施容器,它只是简单地暂停运行,在容器中不做任何操作,以达到占用资源最小的目的。在Kubernetes中,每个Pod都有一个Pause容器,它与其他容器共享网络命名空间和存储空间,从而实现通信和数据共享。这个镜像的版本号(3.4.1)表示镜像的版本,Kubernetes使用版本号来管理镜像的更新和回滚。
kubelet 的 环境变量文件中指定网络插件使用cni插件,基础设施容器镜像使用pause镜像,那么kubelet服务、 cni插件、 pause容器 三者之间的关系是什么?
Kubelet是Kubernetes系统的一个核心组件,它运行在每个节点上,负责管理该节点上的Pod生命周期和容器运行状态等,同时也是进行网络插件和Pod基础设施容器管理的组件之一。
CNI(Container Network Interface)则是一种网络插件标准,它定义了一组API和插件规范,用于实现网络插件和容器运行时的集成。Kubernetes中的CNI插件负责为Pod分配IP地址和引导网络流设置等,在Kubernetes的网络模型中起到了重要的作用。
而Pause容器是Kubenetes系统中的一个特殊的Pod基础设施容器,它在每个Pod中都存在,主要负责暂停容器进程,从而实现对该Pod内的容器进行共享网络和共享存储空间。Pause容器的镜像通常是一个轻量级的镜像,比如官方提供的k8s.gcr.io/pause镜像。
总的来说,kubelet、CNI和Pause容器是Kubernetes系统中协同工作的三个关键组件,Kubelet和CNI负责实现网络插件和Pod基础设施容器的管理,而Pause容器则为Pod内部运行的容器提供了必要的基础设施支持。通过这三者的协同工作,Kubernetes系统可以实现灵活可靠的容器编排和运行。
三者的本质:
kubelet 本质是Linux上的一个服务,它作为一个服务是通过运行 /usr/bin/kubelet 二进制文件运行起来,它作为一个服务运行起来可以通过 systemctl status kubelet -l 查看;
cni 全名 container network interface 容器网络接口,本质是 k8s 定义的一个标准(类似SPI,交给厂商实现),实现了这个 cni 标准的插件就是 cni 插件,使用完成k8s Pod之间网络通信(包括同一个节点和不同节点),常见的如 calico flannel ;
pause 本质是一个docker容器,通过镜像启动起来的容器。
三者的作用(和联系):
kubelet 是一个k8s的服务,是k8s用来管理每个node的(当一个虚拟机被纳管到k8s集群,就变成了一个node),比如说,后面可以看到,kubelet 还可以定时清理磁盘上的镜像,避免磁盘空间占满,所以说,kubelet服务是k8s用来管理每个node的。既然 kubelet 服务用来管理 node,但是每个 pod 都是放在 node 上的,那么 pod 之间如何通信呢?在 kubelet 环境变量文件中有一个 -network-plugin=cni 参数,用来指定运行在 node 上的pod使用 cni 标准通信,但是 cni 插件需要 kubeadm 安装好k8s集群之后,额外安装,一般使用 calico,即安装完 k8s 机器之后,额外安装 calico 插件(Calico通常也使用Pod运行)。另外,对于每个 业务Pod 之间的Container,由于不同 container 使用不同 network namespace 网络命名空间,所以网络之间是隔离的,应该如何网络通信呢?答案是只要这个业务Pod运行的Node上,kubelet会管理运行在Node上的每个Pod,给一个Pod中添加一个 pause 容器,这个pause用来完成Pod之间不同container之间的网络通信。这个 pause 容器并不写在业务Pod的yaml文件中,对于业务Pod编写人员是不感知的,透明的。
总而言之,kubelet 管理每个Node,对于运行在Node上的Pod,kubelet 通过要求使用 cni 插件,实现不同Pod之间的网络通信,再通过给每个Pod里面添加一个pause容器,实现同一个Pod内部不同Container之间的通信。实现打通整个内部网络。
1.5 kubelet使用的额外参数
这里没有被定义,也没有参数被使用,通过 systemctl status kubelet -l 查看到,当前 kubelet 服务运行起来,仅使用到了前三个参数,没有使用第四个额外参数。
二、kubelet启动过程
了解了 kubelet 启动四个参数之后,继续来看看 kubelet 启动过程。
2.1 kubelet启动过程
对于 k8s 整个架构和所有证书,这个 kubelet 服务比较特殊,它在每个node上都有一个。
对于多个节点,为每个节点单独签署证书将是一件非常繁琐的事情;TLS bootstrapping 功能就是让 kubelet 先使用一个预定的低权限用户连接到 apiserver,然后向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署。所以,kubelet 启动时使用 /etc/kubernetes/bootstrap-kubelet.conf 证书,kubelet 运行时使用 /etc/kubernetes/kubelet.conf 证书。
当前的kubelet就是这样做的,我们自己手动,将整个过程做一次,就完全理解整个 kubelet 启动过程了,理解 kubelet 访问 apiserver 的 x509客户端证书了
步骤:TLS Bootstrapping ,使用 Token 时整个启动引导过程:
(1) 认证:在集群内创建特定的 Bootstrap Token Secret ,该 Secret 将替代以前的 token.csv 内置用户声明文件
(2) 授权:在集群内创建首次 TLS Bootstrap 申请证书的 ClusterRole、后续 renew Kubelet client/server 的 ClusterRole,以及其相关对应的 ClusterRoleBinding;并绑定到对应的组或用户
(3) 证书:调整 Controller Manager 配置,以使其能自动签署相关证书和自动清理过期的 TLS Bootstrapping Token
(4) 证书:生成特定的包含 TLS Bootstrapping Token 的 bootstrap.kubeconfig 以供 kubelet 启动时使用
(5) 证书:调整 Kubelet 配置,使其首次启动加载 bootstrap.kubeconfig 并使用其中的 TLS Bootstrapping Token 完成首次证书申请
(6) 证书:证书被 Controller Manager 签署,成功下发,Kubelet 自动重载完成引导流程
(7) 证书:后续 Kubelet 自动 renew(更新) 相关证书
kubeadm部署的如下所示:
-bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf
–config=/var/lib/kubelet/config.yaml --network-plugin=cni
–pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.2
启用 TLS Bootstrapping 机制
TLS Bootstraping:Master apiserver启用TLS认证后,Node节点kubelet和kube-proxy要与kube-apiserver进行通信,必须使用CA签发的有效证书才可以,当Node节点很多时,这种客户端证书颁发需要大量工作,同样也会增加集群扩展复杂度。
为了简化流程,Kubernetes引入了TLS bootstraping机制来自动颁发客户端证书,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。
所以强烈建议在Node上使用这种方式,目前主要用于kubelet,kube-proxy还是由我们统一颁发一个证书。(当机器越来越多的时候,手动的为kubelet颁发证书,还是比较麻烦的,应用这个机制就是为自动的为kubelet颁发证书)
TLS bootstraping 工作流程:

2.2 自定义kubelet所有文件并运行
步骤1:新建kubelet需要的user,给user进行rbac授权
步骤2:创建启动参数文件 kubelet.conf
步骤3:创建配置文件 kubelet-config.yaml
步骤4:创建启动x509证书 bootstrap.kubeconfig
步骤5:使用systemd来管理kubelet
步骤6:运行完成之后,这里 kubelet.conf (kubeconfig发生了改变)
步骤1:新建kubelet需要的user,给user进行rbac授权
新建kubelet需要的user,给user进行rbac授权,等一下自定义的
# 认证
# (1) 新建静态token文件
mkdir -p /etc/kubernetes/cfg
cat > /opt/kubernetes/cfg/token.csv << EOF
c47ffb939f5ca36231d9e3121a252940,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
# (2) 查看刚刚新建好的静态token文件 token.csv
cd /etc/kubernetes/cfg
ll # 看到刚刚新建好的token.csv
# 授权
# (1) 新建binding,给刚刚新建的用户kubelet-bootstrap授权,绑定role
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
# (2) 查看新建的binding
kubectl get clusterrolebinding -o wide -A | grep kubelet-bootstrap

步骤2:创建启动参数文件 kubelet.conf
新建这个 /opt/kubernetes/cfg/kubelet.conf 文件,这个文件里面定义了一个 KUBELET_OPTS 参数
cat > /opt/kubernetes/cfg/kubelet.conf << EOF
KUBELET_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--hostname-override=k8s-master \\
--config=/opt/kubernetes/cfg/kubelet-config.yml \\ # 这个配置文件这里引用,下面会自己定义的
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\ # 这个kubeconfig这里引用,启动后会自己在该目录下生成的
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\ # 这个kubeconfig这里引用,下面会定义的
--cert-dir=/opt/kubernetes/ssl \\
--network-plugin=cni \\
--pod-infra-container-image=k8s.gcr.io/pause:3.4.1"
EOF
这个 KUBELET_OPTS 参数正好是在下面的 /usr/lib/systemd/system/kubelet.service 中用到,然后启动之后 /opt/kubernetes/cfg/kubelet.conf 文件就变动了
原生的kubelet启动需要一个启动参数文件和三个文件:
启动文件:10-kubeadm.conf
三个文件:kubeconfig config.yaml kubeadm-flags.env
这里写的是自定义启动文件,启动文件中引用三个文件,实际上是两个 kubeconfig 和一个config.yaml ,这里启动参数文件中引用了,下面会定义的,否则自定义的kubelet无法正常启动。
–bootstrap-kubeconfig:首次启动向apiserver申请证书 【这里生成的 x509客户端证书】 【kubeconfig】
–kubeconfig:空路径,会自动生成,后面用于连接apiserver 【这个文件可以为空,暂时不存在】 【kubeconfig】
–config:配置参数文件 【这里指定从默认的复制过来的配置文件 config.yaml】 【此为config配置文件】
–hostname-override:显示名称,集群中唯一 【这里写成 m】
–cert-dir:kubelet证书生成目录为 /opt/kubernetes/ssl 【这个mkdir新建一个目录,然后指定】
–network-plugin:启用CNI 【这里写死 cni】
–pod-infra-container-image:管理Pod网络容器的镜像 【这个写死为 k8s.gcr.io/pause:3.4.1 没关系】

步骤3:创建配置文件 kubelet-config.yaml
原生的kubelet启动需要一个启动参数文件和三个文件:
启动参数文件:10-kubeadm.conf
三个文件:kubeconfig config.yaml kubeadm-flags.env
自定义的kubelet启动使用了一个启动参数文件,里面引用了两个kubeconfig和一个config.yaml,这里新建定义配置文件 config.yaml (这个config.yaml是给启动参数文件使用的)
cd /opt/kubernetes/cfg
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
EOF
现在 /opt/kubernetes/cfg 目录下有三个文件了,如下:
步骤4:创建启动x509证书 bootstrap.kubeconfig
原生的kubelet需要一个启动参数文件和三个文件,分别是 config.yaml 配置文件、kubeconfig 用来连接apiserver、环境变量文件
自定义的kubelet使用了一个启动参数文件,里面引用了两个kubeconfig和一个config.yaml配置文件,这里介绍新建 bootstrap.kubeconfig 文件。
编写一个start.sh脚本,用来生成自定义kubelet启动,所需要的 bootstrap.kubeconfig 文件(为了解决,当kubelet很多的时候,为了避免手动颁发证书,引入tls机制,能够自动的为将要加入集群的node颁发证书。所有kubelet要链接apiserver都需要证书,要不然使用手签,要不然使用tls,这里使用tls,使用这个文件去连接apiserver,然后颁发证书,加入集群。)
cd /opt/kubernetes/cfg
vi start.sh
# 定义变量
KUBE_APISERVER="https://192.168.100.155:6443" # apiserver IP:PORT
TOKEN="14cca9b8783da4a04a90f08a9b0e98ba" # 与token.csv里保持一致
# 生成 kubelet bootstrap kubeconfig 中的 cluster 字段,名为 kubernetes
kubectl config set-cluster kubernetes \ # 输出:设置生成的集群cluster名为 kubernetes
--certificate-authority=/etc/kubernetes/pki/ca.crt \ # 输入:指定集群的ca证书
--embed-certs=true \ # 输入:密钥文件和证书文件中内嵌 TLS 证书, 而不是放到目录里面
--server=${KUBE_APISERVER} \ # 输入:指定集群IP
--kubeconfig=bootstrap.kubeconfig # 输出结果到bootstrap.kubeconfig文件中
# 生成 kubelet bootstrap kubeconfig 中的 user 字段,名为 kubelet-bootstrap
kubectl config set-credentials "kubelet-bootstrap" \ # 输出:设置生成的名为 default
--token=${TOKEN} \ # 输入:设置token
--kubeconfig=bootstrap.kubeconfig # 输出结果到bootstrap.kubeconfig文件中
# 生成 kubelet bootstrap kubeconfig 中的 context 上下文字段,名为 default
kubectl config set-context default \ # 输出:设置生成的上下文context名为 default
--cluster=kubernetes \ # 输入:使用名为 kubernetes 的集群cluster
--user="kubelet-bootstrap" \ # 输入:使用名为 kubelet-bootstrap 的用户user
--kubeconfig=bootstrap.kubeconfig # 输出:输出结果到bootstrap.kubeconfig文件中
# 设置使用 kubelet bootstrap kubeconfig 中的 context 上下文字段
kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
当指定 embed-certs=true 时,Kubernetes 将会在密钥文件和证书文件中内嵌 TLS 证书,而不是将它们存储在 kube-apiserver 运行环境的相应目录中。这意味着在 API Server API Server 启动时,它将从内嵌证书文件中读取和配置TLS证书与密钥。使用 embed-certs 可以确保密钥和证书不被意外的替换或删除,提高 Kubernetes API Server 的安全性。
chmod 777 start.sh
./start.sh
ll # 多了一个bootstrap.kubeconfig
cat bootstrap.kubeconfig


它就会拿着bootstrap.kubeconfig向apiserver发起请求,apiserver会去验证这个token是不是可信任的 (因为user使用 静态token生成,所以是可信的)
步骤5:使用systemd来管理kubelet
好了,现在整个自定义kubelet都已经准备好了,就等启动运行了,这里将使用systemd来管理kubelet,然后使用 systemctl restatt kubelet 来启动整个服务。
# (1) 使用systemd来管理kubelet
cd /usr/lib/systemd/system
cat kubelet.service
vi kubelet.service
增加一行 EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf ,这个文件定义了 $KUBELET_OPT 变量
修改一行 ExecStart=/usr/bin/kubelet ,后面加上 $KUBELET_OPT, ,这个文件使用了 $KUBELET_OPT 变量
# (2) 使用systemctl restart kubelet 运行自定义的kubelet服务
systemctl restart kubelet
使用systemd来管理kubelet:进入/usr/lib/systemd/system目录,这里有一个kubelet.service,使用 systemctl restart kubelet 就是操作这个目录下的kubelet.service服务,而这个kubelet.service服务,又恰好是指向 /usr/bin/kubelet 二进制文件,所以就实现了使用systemd来管理kubelet。


步骤6:运行完成之后,这里 kubelet.conf (kubeconfig发生了改变)
使用 systemctl restart kubelet 启动服务之后,发现 /etc/kubernetes/cfg 目录下多了一个 kubelet.conf 文件,这是因为自定义kubelet的启动参数文件有一句 --kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig ,这个参数指定kubelet启动后会自己在该目录下生成kubeconfig,所以就有了这个

但是上图这个文件中的红框中的 /var/lib/kubelet/pki/ 是在哪里指定的,根据数据追本溯源法,一定有一个地方指定了这个默认目录 /var/lib/kubelet/pki/ , 这个目录没有指定缺省就是这样 /var/lib/kubelet/pki .
无论是默认的kubelet,还是自定义的kubelet,都是这样 /var/lib/kubelet/pki .

三、kubelet定时清理磁盘镜像
kubelet 是k8s的系统服务,是用来管理 k8s node 的(如果一个虚拟机被k8s纳管,就变成了一个k8s node),node上的 images 镜像越来越多有占满磁盘的风险怎么办,kubelet 作为管理node上的服务,有自带的回收机制。
3.1 理论
-
Kubernetes的垃圾回收由kubelet进行管理,每分钟会查询清理一次容器,每五分钟查询清理一次镜像。在kubelet刚启动时并不会立即进行GC,即第一次进行容器回收为kubelet启动一分钟后,第一次进行镜像回收为kubelet启动五分钟后。
-
不推荐使用其它管理工具或手工进行容器和镜像的清理,因为kubelet需要通过容器来判断pod的运行状态,如果使用其它方式清除容器有可能影响kubelet的正常工作。
-
镜像的回收针对node结点上由docker管理的所有镜像,无论该镜像是否是在创建pod时pull的。而容器的回收策略只应用于通过kubelet管理的容器。
-
Kubernetes通过kubelet集成的cadvisor进行镜像的回收,有两个参数可以设置:–image-gc-high-threshold和–image-gc-low-threshold。当用于存储镜像的磁盘使用率达到百分之–image-gc-high-threshold时将触发镜像回收,删除最近最久未使用(LRU,Least Recently Used)的镜像直到磁盘使用率降为百分之–image-gc-low-threshold或无镜像可删为止。默认–image-gc-high-threshold为90,–image-gc-low-threshold为80。
-
容器的回收有三个参数可设置:–minimum-container-ttl-duration,–maximum-dead-containers-per-container和–maximum-dead-containers。从容器停止运行时起经过–minimum-container-ttl-duration时间后,该容器标记为已过期将来可以被回收(只是标记,不是回收),默认值为1m0s。一般情况下每个pod最多可以保留–maximum-dead-containers-per-container个已停止运行的容器集,默认值为2。整个node节点可以保留–maximum-dead-containers个已停止运行的容器,默认值为100。
-
如果需要关闭容器的垃圾回收策略,可以将–minimum-container-ttl-duration设为0(表示无限制),–maximum-dead-containers-per-container和–maximum-dead-containers设为负数。
-
–minimum-container-ttl-duration的值可以使用单位后缀,如h表示小时,m表示分钟,s表示秒。
-
当–maximum-dead-containers-per-container和–maximum-dead-containers冲突时,–maximum-dead-containers优先考虑。
-
对于那些由kubelet创建的但由于某些原因导致无名字()的容器,会在到达GC时间点时被删除。
-
回收容器时,按创建时间排序,优先删除那些创建时间最早的容器。
-
到达GC时间点时,具体的GC过程如下:
- 1)遍历所有pod,使其满足–maximum-dead-containers-per-container;
- 2)经过上一步后如果不满足–maximum-dead-containers,计算值X=(–maximum-dead-containers)/(pod总数),再遍历所有pod,使其满足已停止运行的容器集个数不大于X且至少为1;
- 3)经过以上两步后如果还不满足–maximum-dead-containers,则对所有已停止的容器排序,优先删除创建时间最早的容器直到满足–maximum-dead-containers为止。
-
当某个镜像重新pull或启动某个pod用到该镜像时,该镜像的最近使用时间都会被更新。
-
Kubernetes的垃圾回收在1.1.4版本开始才渐渐完善,之前的版本存在比较多bug甚至不能发挥作用。
-
关于容器的回收需要特别注意pod的概念,比如,通过同一个yaml文件create一个pod,再delete这个pod,然后再create这个pod,此时之前的那个pod对应的容器并不会作为新创建pod的已停止容器集,因为这两个pod虽然同名,但已经不是同一个pod了。只有同一个pod中在运行过程中由于意外或其它情况停止的容器才算是这个pod的已停止容器集。
3.2 实践
镜像回收(使用docker默认 --graph 参数:/var/lib/docker)
结点上运行的docker设置的参数 --graph 使用默认的/var/lib/docker,指向/var文件系统,通过df -lh查看目前 /var 磁盘使用率为30%,启动kubelet设置镜像回收相关参数如下:
--image-gc-high-threshold=40 --image-gc-low-threshold=35
此时任意创建两个使用不同镜像的pod,在node节点上可以看到新pull了三个images(pause镜像是启动pod必需的):
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
10.11.150.76:5000/openxxs/iperf 1.2 1783511c56f8 3 months ago 279 MB
10.11.150.76:5000/centos 7 5ddf34d4d69b 8 months ago 172.2 MB
pub.domeos.org/kubernetes/pause latest f9d5de079539 20 months ago 239.8 kB
此时查看/var磁盘使用率达到了41%,然后将使用10.11.150.76:5000/centos:7镜像的pod删除,等待GC的镜像回收时间点。然而五分钟过去了,什么事情也没有发生=_=!!。还记得 docker rmi 镜像时有个前提条件是什么吗?没错,要求使用该镜像的容器都已经被删除了才可以。前面删除pod只是停止了容器,并没有将容器删除。因此手工将对应的容器docker rm掉,再等待五分钟后,可以看到镜像已经被删除回收了:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
10.11.150.76:5000/openxxs/iperf 1.2 1783511c56f8 3 months ago 279 MB
pub.domeos.org/kubernetes/pause latest f9d5de079539 20 months ago 239.8 kB
结论:只有相关联的容器都被停止并删除回收后,才能将Kubernetes的镜像垃圾回收策略应用到该镜像上。
镜像回收(使用自定义docker --graph 参数:/opt/docker)
结点上运行的docker设置的参数–graph指向 /opt 磁盘,通过 df -lh 查看目前 /opt 磁盘使用率为 48% ,启动 kubelet 设置镜像回收相关参数如下:
--image-gc-high-threshold=50 --image-gc-low-threshold=40
此时任意创建两个使用不同镜像的pod,在node节点上可以看到新pull了三个images:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
10.11.150.76:5000/openxxs/iperf 1.2 1783511c56f8 3 months ago 279 MB
10.11.150.76:5000/centos 7 5ddf34d4d69b 8 months ago 172.2 MB
pub.domeos.org/kubernetes/pause latest f9d5de079539 20 months ago 239.8 kB
此时查看/opt磁盘使用率达到了51%,然后将使用10.11.150.76:5000/centos:7镜像的pod删除,手工将对应的容器docker rm掉,等待GC的镜像回收时间点。然而五分钟过去了,十分钟过去了,docker images时centos镜像依旧顽固地坚守在阵地。
结论:目前Kubernetes的镜像垃圾回收策略可以在docker --graph 参数默认为 /var/lib/docker 时正常工作,当 --graph 设置为其它磁盘路径时还存在bug。
问题反馈在 Github 的相关 issue 里:https://github.com/kubernetes/kubernetes/issues/17994,可以继续跟进。
Append: 根据Github上的反馈,这个bug将在后续版本中解决,目前版本需要让设置了–graph的镜像垃圾回收生效,在启动kubelet时还需要加上参数 --docker-root=<docker --graph参数值>。
容器回收之 --maximum-dead-containers-per-container 参数
启动kubelet设置容器回收相关参数如下:
--maximum-dead-containers-per-container=1
--minimum-container-ttl-duration=30s
--maximum-dead-containers=100
创建一个只包含一个容器且该容器一运行就退出的pod,此时在node节点上可以看到该pod中的容器不断的创建退出创建退出:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2fe969499164 10.11.150.76:5000/centos:7 "/bin/bash" 4 seconds ago Exited (0) 2 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_92e8bd05-e9e6-11e5-974c-782bcb2a316a_68cc6f03
555b5e7a8550 10.11.150.76:5000/centos:7 "/bin/bash" 24 seconds ago Exited (0) 22 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_92e8bd05-e9e6-11e5-974c-782bcb2a316a_ad4a5e39
94b30a0b32c2 10.11.150.76:5000/centos:7 "/bin/bash" 34 seconds ago Exited (0) 32 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_92e8bd05-e9e6-11e5-974c-782bcb2a316a_4027e3e1
d458e6a7d396 pub.domeos.org/kubernetes/pause:latest "/pause" 34 seconds ago Up 33 seconds k8s_POD.bdb2e1f5_test-gc-pod-exit_default_92e8bd05-e9e6-11e5-974c-782bcb2a316a_09798975
GC的容器回收时间点到达时,可以看到创建时间大于30秒的已退出容器只剩下一个(pause容器不计算),且先创建的容器被优先删除:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5aae6157aeff 10.11.150.76:5000/centos:7 "/bin/bash" 46 seconds ago Exited (0) 45 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_92e8bd05-e9e6-11e5-974c-782bcb2a316a_f126d2a8
d458e6a7d396 pub.domeos.org/kubernetes/pause:latest "/pause" 2 minutes ago Up 2 minutes k8s_POD.bdb2e1f5_test-gc-pod-exit_default_92e8bd05-e9e6-11e5-974c-782bcb2a316a_09798975
结论:Kubernetes容器垃圾回收的–maximum-dead-containers-per-container参数设置可正常工作。
–maximum-dead-containers-per-container 针对容器还是容器集
启动kubelet设置容器回收相关参数如下:
--maximum-dead-containers-per-container=1
--minimum-container-ttl-duration=30s
--maximum-dead-containers=100
创建一个包含三个容器且这些容器一运行就退出的pod,此时在node节点上可以看到该pod中的容器不断的创建退出创建退出:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dec04bd28a03 10.11.150.76:5000/centos:7 "/bin/bash" 7 seconds ago Exited (0) 6 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_830a9375
7c94d4a963a7 10.11.150.76:5000/centos:7 "/bin/bash" 7 seconds ago Exited (0) 6 seconds ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_975d44d3
4f3e7e8ddfd5 10.11.150.76:5000/centos:7 "/bin/bash" 8 seconds ago Exited (0) 7 seconds ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_d024eb06
cb48cf2ba133 10.11.150.76:5000/centos:7 "/bin/bash" 12 seconds ago Exited (0) 11 seconds ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_b5ff7373
ec2941f046f0 10.11.150.76:5000/centos:7 "/bin/bash" 13 seconds ago Exited (0) 12 seconds ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_69b1a996
f831e8ed5687 10.11.150.76:5000/centos:7 "/bin/bash" 13 seconds ago Exited (0) 12 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_fbc02e2e
ee972a4537fc pub.domeos.org/kubernetes/pause:latest "/pause" 14 seconds ago Up 13 seconds k8s_POD.bdb2e1f5_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_85b3c032
GC的容器回收时间点到达时,可以看到创建时间大于30秒的已退出容器剩下三个(pause容器不计算),且这三个容器正好是一组:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e4351e6855ae 10.11.150.76:5000/centos:7 "/bin/bash" 51 seconds ago Exited (0) 50 seconds ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_263dd820
990baa6e6a7a 10.11.150.76:5000/centos:7 "/bin/bash" 52 seconds ago Exited (0) 51 seconds ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_b16b5eaa
c6916fb06d65 10.11.150.76:5000/centos:7 "/bin/bash" 53 seconds ago Exited (0) 51 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_1d8ea284
ee972a4537fc pub.domeos.org/kubernetes/pause:latest "/pause" About a minute ago Up About a minute k8s_POD.bdb2e1f5_test-gc-pod-exit_default_d1677c09-e9e7-11e5-974c-782bcb2a316a_85b3c032
结论:–maximum-dead-containers-per-container 的计数针对一个pod内的容器集而不是容器的个数。
容器回收之 --maximum-dead-containers 参数
启动kubelet设置容器回收相关参数如下:
--maximum-dead-containers-per-container=2
--minimum-container-ttl-duration=30s
--maximum-dead-containers=3
创建一个包含三个容器的pod,再删除该pod,再创建该pod,再删除该pod,这样就产生了8个已退出容器(包括两个pause容器):
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a28625d189df 10.11.150.76:5000/centos:7 "/bin/bash" 1 seconds ago Exited (0) Less than a second ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_48c11200
97aca44f0deb 10.11.150.76:5000/centos:7 "/bin/bash" 2 seconds ago Exited (0) 1 seconds ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_df34f48d
4e57b6c839ae 10.11.150.76:5000/centos:7 "/bin/bash" 3 seconds ago Exited (0) 2 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_afd622b2
12588fce1433 pub.domeos.org/kubernetes/pause:latest "/pause" 3 seconds ago Exited (2) Less than a second ago k8s_POD.bdb2e1f5_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_c9d4cbaa
621ed207d452 10.11.150.76:5000/centos:7 "/bin/bash" 4 seconds ago Exited (0) 3 seconds ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_c5cbddbb-e9ee-11e5-974c-782bcb2a316a_a91278cd
023c10fad4fd 10.11.150.76:5000/centos:7 "/bin/bash" 5 seconds ago Exited (0) 4 seconds ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_c5cbddbb-e9ee-11e5-974c-782bcb2a316a_6cc03f37
756eb7bb4b53 10.11.150.76:5000/centos:7 "/bin/bash" 5 seconds ago Exited (0) 4 seconds ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_c5cbddbb-e9ee-11e5-974c-782bcb2a316a_83312ec2
d54bdc22773e pub.domeos.org/kubernetes/pause:latest "/pause" 6 seconds ago Exited (2) 3 seconds ago k8s_POD.bdb2e1f5_test-gc-pod-exit_default_c5cbddbb-e9ee-11e5-974c-782bcb2a316a_ccb57220
GC的容器回收时间点到达时,可以看到已退出容器只剩下了三个,pause容器也被回收了:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a28625d189df 10.11.150.76:5000/centos:7 "/bin/bash" 2 minutes ago Exited (0) 2 minutes ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_48c11200
97aca44f0deb 10.11.150.76:5000/centos:7 "/bin/bash" 2 minutes ago Exited (0) 2 minutes ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_df34f48d
4e57b6c839ae 10.11.150.76:5000/centos:7 "/bin/bash" 2 minutes ago Exited (0) 2 minutes ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_afd622b2
结论:Kubernetes容器垃圾回收的 --maximum-dead-containers参数设置可正常工作;pause容器也作为可回收容器被管理着;Tips第11条第3)点。
–maximum-dead-containers 对于非kubelet管理的容器是否计数
在第5个实验的基础上,手工创建一个container,等待GC的容器回收时间点到达,一分钟过去了,两分钟过去了,docker ps -a 显示的依然是4个容器:
$ docker run -it 10.11.150.76:5000/openxxs/iperf:1.2 /bin/sh
sh-4.2# exit
exit
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
939b932dc7db 10.11.150.76:5000/openxxs/iperf:1.2 "/bin/sh" 2 minutes ago Exited (0) 2 minutes ago backstabbing_aryabhata
a28625d189df 10.11.150.76:5000/centos:7 "/bin/bash" 12 minutes ago Exited (0) 12 minutes ago k8s_iperf3.5c8de29f_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_48c11200
97aca44f0deb 10.11.150.76:5000/centos:7 "/bin/bash" 12 minutes ago Exited (0) 12 minutes ago k8s_iperf2.5a36e29e_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_df34f48d
4e57b6c839ae 10.11.150.76:5000/centos:7 "/bin/bash" 12 minutes ago Exited (0) 12 minutes ago k8s_iperf1.57dfe29d_test-gc-pod-exit_default_c7612b59-e9ee-11e5-974c-782bcb2a316a_afd622b2
结论:Kubernetes容器垃圾回收的策略不适用于非kubelet管理的容器。
尾声
kubelet服务全解析,完!文章来源:https://www.toymoban.com/news/detail-758318.html
参考资料:Kubelet Bootstrap 机制 APIServer基于引导token认证
kubelet定时清除磁盘镜像文章来源地址https://www.toymoban.com/news/detail-758318.html
到了这里,关于Kubernetes_核心组件_kubelet_kubelet服务全解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!