代理池的,防止IP 被封

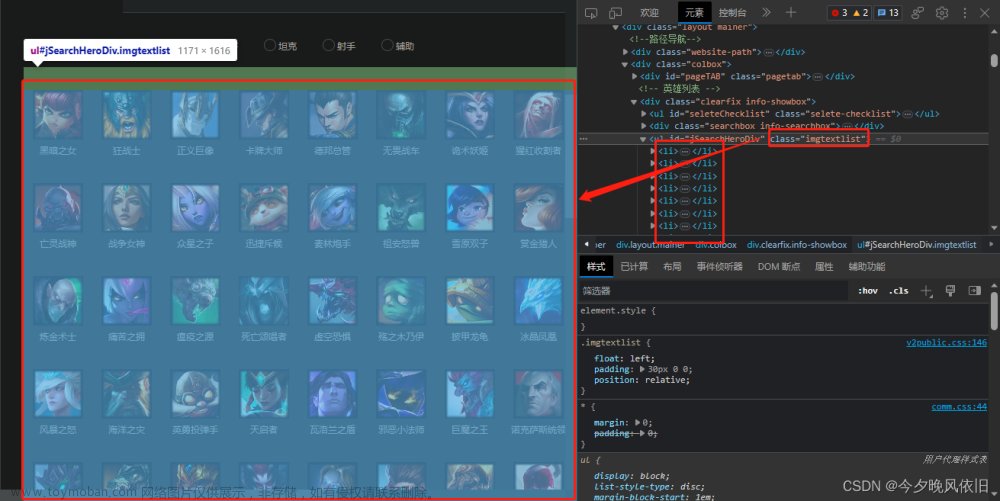
找到图片真实地址
现在看到的只是图片的预览地址 (previews)

1.检查:

2.鼠标变为箭头时查看网页源代码

关于怎样在源代码中找到图片的真实地址 ???
为什么在源代码界面 ctrl f 时候搜索的是 .png ???
首先图片地址是以 .jpg .png .jpeg 结尾
真实的图片地址是:
"contentUrl":"https://img3.wallspic.com/crops/0/5/0/6/7/176050/176050-old_paria_utah-paria-kanab-paria_river-towers_of_the_virgin-6319x4324.jpg"
用正则表达式匹配,只匹配高像素源图片
(r'contentUrl":"(https://img\d.wallspic.com/crops/.*?)"', response)

如果是下面的内容,则会连缩略图也匹配到
(r'"contentUrl":"(.*?)"',req) 最终代码:
最终代码:
import requests
import re
url = 'https://wallspic.com/cn/album/ji_shu/for_desktop'
response = requests.get(url = url).text
contentUrl = re.findall(r'contentUrl":"(https://img\d.wallspic.com/crops/.*?)"', response)
j = 0
for i in contentUrl:
j += 1
Content = requests.get(url = i).content
print(i)
with open(f'Wallspic-{j}.jpg', mode = 'wb') as f:
f.write(Content)
print(f'[+] 壁纸{j}保存完成!')
最终结果是以.jpg的形式输出的

也可以以 .png的形式输出,.png是益处多多
Desktop Wallpapers - Download HD Desktop Backgrounds
https://wall.alphacoders.com/by_sub_category.php?id=170792&name=Black+Wallpapers
下载的慢可能是网速的原因,需要翻墙;或者给 idea 配置代理,
刷新电脑本地的线路,保持畅通。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
import requests
import re
def download_wallpapers(start_page, end_page):
for page in range(start_page, end_page+1):
url = f'https://wallspic.com/cn/album/dianying/popular?page={page}'
response = requests.get(url=url).text
contentUrl = re.findall(r'contentUrl":"(https://img\d.wallspic.com/crops/.*?)"', response)
j = 0
for i in contentUrl:
j += 1
Content = requests.get(url = i).content
print(i)
with open(f'p-{page}-{j}.jpg', mode = 'wb') as f:
f.write(Content)
print(f'[+] 壁纸{page}-{j}保存完成!')
# 下载第1页到第55页的壁纸
download_wallpapers(1, 55)文章来源:https://www.toymoban.com/news/detail-758352.html
这段代码的作用是从wallspic.com网站下载电影壁纸,具体解读如下:文章来源地址https://www.toymoban.com/news/detail-758352.html
- 导入requests和re模块:
import requests
import re
- 定义一个函数download_wallpapers,该函数接受两个参数:起始页码start_page和结束页码end_page。
def download_wallpapers(start_page, end_page):
- 使用for循环遍历从start_page到end_page的所有页码。
for page in range(start_page, end_page+1):
- 构造每个页面的URL,并使用requests.get()方法获取页面的HTML文本。
url = f'https://wallspic.com/cn/album/dianying/popular?page={page}'
response = requests.get(url=url).text
- 使用正则表达式从HTML文本中提取出所有壁纸的下载链接。
contentUrl = re.findall(r'contentUrl":"(https://img\d.wallspic.com/crops/.*?)"', response)
- 使用for循环遍历所有壁纸的下载链接,并使用requests.get()方法下载每个壁纸。
for i in contentUrl:
Content = requests.get(url = i).content
- 将每个壁纸保存到本地,并打印出保存完成的信息。
with open(f'p-{page}-{j}.jpg', mode = 'wb') as f:
f.write(Content)
print(f'[+] 壁纸{page}-{j}保存完成!')
到了这里,关于python-爬取壁纸的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Python小项目] 从桌面壁纸到AI绘画](https://imgs.yssmx.com/Uploads/2024/02/713775-1.png)