LibCurl是一个开源的免费的多协议数据传输开源库,该框架具备跨平台性,开源免费,并提供了包括HTTP、FTP、SMTP、POP3等协议的功能,使用libcurl可以方便地进行网络数据传输操作,如发送HTTP请求、下载文件、发送电子邮件等。它被广泛应用于各种网络应用开发中,特别是涉及到数据传输的场景。本章将是《C++ LibCurl 库的使用方法》的扩展篇,在前一篇文章中我们简单实现了LibCurl对特定页面的访问功能,本文将继续扩展该功能,并以此实现Web隐藏目录扫描功能。
读入文件到内存
首先通过读取字典文件,将每行内容与指定的根网址进行拼接,生成新的URL列表,此处GetCombinationURL 函数的目标是根据传入的根网址和字典文件,生成一个包含拼接后的URL列表的std::vector<std::string>。
函数的实现主要包括以下步骤:
- 打开指定的字典文件,逐行读取其中的内容。
- 对于每一行内容,去除行末的换行符,并使用
sprintf将根网址与当前行内容拼接,形成完整的URL。 - 将生成的URL加入std::vector`中。
- 返回包含所有URL的std::vector。
在main函数中,调用GetCombinationURL并将生成的URL列表输出到控制台。代码使用了C++中的文件操作和字符串处理,利用std::vector存储生成的 URL,以及通过std::cout在控制台输出结果。
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// 传入网址和字典名
std::vector<std::string> GetCombinationURL(char root[64],char dict_file[128])
{
char buffer[512] = { 0 };
char this_url[1024] = { 0 };
std::vector<std::string> ref;
FILE *fp = fopen(dict_file, "r");
if (fp != NULL)
{
while (feof(fp) == 0)
{
fgets(buffer, 1024, fp); // 每次读入一行
strtok(buffer, "\n"); // 去掉行末的 \n
buffer[strcspn(buffer, "\n")] = 0; // 替换所有 \n
sprintf(this_url, "%s%s", root, buffer);
ref.push_back(this_url);
}
}
return ref;
}
int main(int argc, char *argv[])
{
std::vector<std::string> ref = GetCombinationURL("https://www.xxx.com", "./save.log");
for (int x = 0; x < ref.size(); x++)
{
std::cout << "拼接URL: " << ref[x] << std::endl;
}
std::system("pause");
return 0;
}
我们需要新建一个save.log文件,每行放入一个子目录地址,例如放入;
/index.php
/phpinfo.php
运行后输出效果如下图所示;
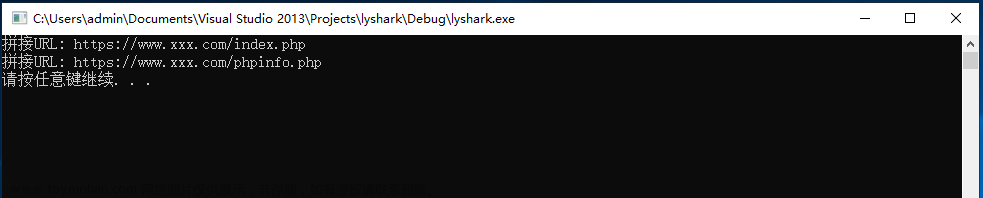
增加默认多线程
首先,我们引入了libcurl库,代码中使用libcurl提供的函数来执行HTTP请求,获取返回状态码,并通过多线程处理多个URL。
- GetPageStatus 函数:用于获取指定URL的HTTP状态码。使用
libcurl进行初始化、设置请求头、执行请求,并最终获取返回的状态码。 - ThreadProc 函数:线程执行函数,通过调用
GetPageStatus函数获取URL的状态码,并在控制台输出。如果状态码为200,则将URL记录到日志文件中。 - main 函数:主函数读取输入的URL列表文件,逐行读取并构造完整的URL。通过
CreateThread创建线程,每个线程处理一个URL。同时使用互斥锁确保线程安全。
用户可以通过在命令行传递两个参数,第一个参数为根网址,第二个参数为包含URL列表的文件路径。程序将读取文件中的每个URL,通过libcurl发送HTTP 请求,获取状态码,并输出到控制台。状态码为200的URL将被记录到save.log文件中。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 设置锁
HANDLE hmutex;
// 屏蔽无用的输出
static size_t write_data(char *d, size_t n, size_t l, void *p){ return 0; }
int GetPageStatus(char *HostUrl)
{
CURLcode return_code;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
struct curl_slist *headers = NULL;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (LyShark NT 10.0; Win64; x64; rv:76.0)");
CURL *easy_handle = curl_easy_init();
int retcode = 0;
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_HTTPHEADER, headers); // 改协议头
curl_easy_setopt(easy_handle, CURLOPT_URL, HostUrl); // 请求的网站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, write_data); // 设置回调函数,屏蔽输出
return_code = curl_easy_perform(easy_handle); // 执行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
// 线程执行函数
DWORD WINAPI ThreadProc(LPVOID lpParam)
{
char *urls = (char *)(LPVOID)lpParam;
WaitForSingleObject(hmutex, INFINITE);
int ret = GetPageStatus(urls);
if (ret == 200)
{
FILE *fp = fopen("./save.log", "a+");
fwrite(urls, strlen(urls), 1, fp);
fwrite("\n", 2, 1, fp);
fclose(fp);
}
std::cout << "状态码: " << ret << " 地址: " << urls << std::endl;
ReleaseMutex(hmutex);
return 0;
}
int main(int argc, char *argv[])
{
if (argc == 3)
{
FILE *fp = fopen(argv[2], "r");
char buffer[1024] = { 0 };
char url[1024] = { 0 };
hmutex = CreateMutex(NULL, TRUE, NULL);
ReleaseMutex(hmutex);
while (feof(fp) == 0)
{
fgets(buffer, 1024, fp);
strtok(buffer, "\n");
buffer[strcspn(buffer, "\n")] = 0;
sprintf(url, "%s%s", argv[1], buffer);
CreateThread(0, 0, (LPTHREAD_START_ROUTINE)ThreadProc, (LPVOID)url, 0, 0);
Sleep(80);
}
}
return 0;
}
使用Boost多线程
如上Web目录扫描器,虽实现了目录的扫描,但是有个很大的缺陷,第一是无法跨平台,第二是无法实现优雅的命令行解析效果,所以我们需要使用boost让其支持跨平台并增加一个输出界面。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/bind.hpp>
#include <boost/thread.hpp>
#include <boost/function.hpp>
#include <boost/thread/thread_guard.hpp>
#include <boost/program_options.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
using namespace boost;
namespace opt = boost::program_options;
boost::mutex io_mutex;
void ShowOpt()
{
fprintf(stderr,
"# # # \n"
"# # # \n"
"# # # ##### ###### ###### # ### # ## \n"
"# # # # # # # # ## # # \n"
"# # # #### # # # # # ### \n"
"# ##### # # # # ## # # # \n"
"##### # ##### # # #### # # # ## \n\n"
);
}
// 传入网址和字典名
std::vector<std::string> GetCombinationURL(char *root, char *dict_file)
{
char buffer[512] = { 0 };
char this_url[1024] = { 0 };
std::vector<std::string> ref;
FILE *fp = fopen(dict_file, "r");
if (fp != NULL)
{
while (feof(fp) == 0)
{
fgets(buffer, 1024, fp); // 每次读入一行
strtok(buffer, "\n"); // 去掉行末的 \n
buffer[strcspn(buffer, "\n")] = 0; // 替换所有 \n
sprintf(this_url, "%s%s", root, buffer);
ref.push_back(this_url);
}
}
return ref;
}
// 屏蔽无用的输出
static size_t write_data(char *d, size_t n, size_t l, void *p){ return 0; }
int GetPageStatus(std::string HostUrl)
{
CURLcode return_code;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
int retcode = 0;
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, HostUrl); // 请求的网站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, write_data); // 设置回调函数,屏蔽输出
return_code = curl_easy_perform(easy_handle); // 执行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
// 线程执行函数
void ThreadProc(std::string url)
{
boost::lock_guard<boost::mutex> global_mutex(io_mutex);
int ret = GetPageStatus(url);
if (ret == 200)
{
FILE *fp = fopen("./save.log", "a+");
fwrite(url.c_str(), strlen(url.c_str()), 1, fp);
fwrite("\n", 2, 1, fp);
fclose(fp);
}
std::cout << "状态码: " << ret << " 地址: " << url << std::endl;
}
int main(int argc, char * argv[])
{
opt::options_description des_cmd("\n Usage: 扫描工具 Ver:1.1 \n\n Options");
des_cmd.add_options()
("url,u", opt::value<std::string>(), "指定需要的URL地址")
("dict,d", opt::value<std::string>(), "指定字典")
("help,h", "帮助菜单");
opt::variables_map virtual_map;
try
{
opt::store(opt::parse_command_line(argc, argv, des_cmd), virtual_map);
}
catch (...){ return 0; }
// 定义消息
opt::notify(virtual_map);
// 无参数直接返回
if (virtual_map.empty())
{
ShowOpt();
std::cout << des_cmd << std::endl;
return 0;
}
else if (virtual_map.count("help") || virtual_map.count("h"))
{
ShowOpt();
std::cout << des_cmd << std::endl;
return 0;
}
else if (virtual_map.count("url") && virtual_map.count("dict"))
{
std::string scan_url = virtual_map["url"].as<std::string>();
std::string scan_path = virtual_map["dict"].as<std::string>();
// 由于string与char* 需要转换,所以拷贝后转换
char src[1024] = { 0 };
char path[1024] = { 0 };
strcpy(src, scan_url.c_str());
strcpy(path, scan_path.c_str());
std::vector<std::string> get_url = GetCombinationURL(src, path);
boost::thread_group group;
for (int x = 0; x < get_url.size(); x++)
{
group.create_thread(boost::bind(ThreadProc, get_url[x]));
_sleep(50);
}
group.join_all();
}
else
{
std::cout << "参数错误" << std::endl;
}
return 0;
}
传入参数运行,当访问出现200提示,则自动保存到save.log中,运行效果如下。文章来源:https://www.toymoban.com/news/detail-758527.html
- main.exe --url https://xxxxx --dict c://dict.log
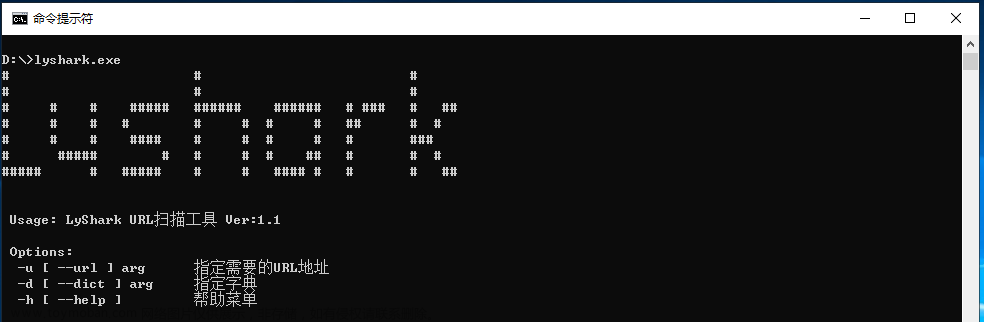 文章来源地址https://www.toymoban.com/news/detail-758527.html
文章来源地址https://www.toymoban.com/news/detail-758527.html
到了这里,关于C++ LibCurl实现Web隐藏目录扫描的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!