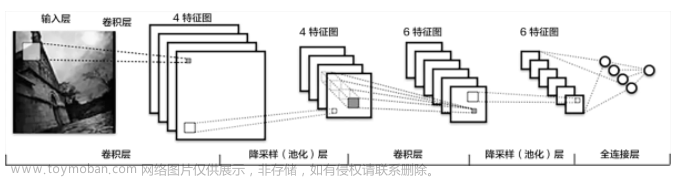
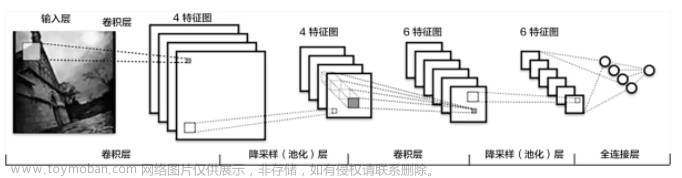
大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类
过拟合,欠拟合
针对模型的拟合,这里引入两个概念:过拟合,欠拟合。
过拟合:在机器学习任务中,我们通常将数据集分为两部分:训练集和测试集。训练集用于训练模型,而测试集则用于评估模型在未见过数据上的性能。过拟合就是指模型在训练集上表现较好,但在测试集上表现较差的现象。
当模型过度拟合训练集时,它会学习到训练数据中的噪声和异常模式,导致对新数据的泛化能力下降。过拟合的典型特征是模型对训练集中每个样本都产生了很高的拟合度,即模型过于复杂地学习了训练集的细节和噪声。
欠拟合:在训练集上的效果就很差。
对于二分类数据,我们可以用下面三个图更直观的理解过拟合与欠拟合
一、欠拟合
首先来说欠拟合,欠拟合主要是由于学习不足造成的,那么我们可以通过以下方法解决此问题
1、增加特征
增加新的特征,或者衍生特征(对特征进行变换,特征组合)
2、使用较复杂的模型,或者减少正则项
其次讨论过拟合,为什么我们的模型会过拟合呢?这里,我总结了一下,将其原因分成两大类:
二、过拟合
1、样本问题
1)样本量太少:
样本量太少可能会使得我们选取的样本不具有代表性,从而将这些样本独有的性质当作一般性质来建模,就会导致模型在测试集上效果很差;
模型复杂度过高:当模型的复杂度过高时,它有足够的灵活性来捕捉训练集中的每个数据点,但也容易记住数据中的噪声和特定样本的细节,导致在新数据上的性能下降。
数据不足:如果训练集样本数量较少,模型难以捕捉到数据的整体分布,容易受到极端值的影响,从而导致过拟合问题。
特征选择不当:选择的特征过多或过少都可能导致过拟合。特征选择的关键是要选择那些与预测目标相关的特征,过多或过少都可能引入噪声或忽略重要信息。
2)训练集、测试集分布不一致:
对于数据集的划分没有考虑业务场景,有可能造成我们的训练、测试样本的分布不同,就会出现在训练集上效果好,在测试集上效果差的现象;
3)样本噪声干扰大:
如果数据的声音较大,就会导致模型拟合这些噪声,增加了模型复杂度;
2、模型问题
1)参数太多,模型过于复杂,对于树模型来说,比如:决策树深度较大等。
3、解决方法
1)增加样本量:
样本量越大,过拟合的概率就越小(不过有的由于业务受限,样本量增加难以实现);
2)减少特征:
减少冗余特征;
3)加入正则项:
损失函数中加入正则项,惩罚模型的参数,降低模型的复杂度(树模型可以控制深度等);
4)集成学习:
详细一点:
练多个模型,将模型的平均结果作为输出,这样可以弱化每个模型的异常数据影响。
增加训练数据:通过增加更多的训练数据,可以帮助模型更好地学习数据的整体分布,减少对特定样本的依赖,从而缓解过拟合现象。
减少模型复杂度:选择适当的模型复杂度可以有效避免过拟合问题。可以通过减少模型的隐藏层、降低多项式的阶数等方式来降低模型复杂度,以提高泛化能力。
正则化:正则化是一种常用的缓解过拟合的方法。通过在损失函数中引入惩罚项,限制模型参数的大小,可以防止模型过度拟合训练数据,减少对噪声和异常样本的敏感性。
特征选择:选择与预测目标高度相关的特征,去除冗余或无关的特征,有助于减少过拟合的风险,并提高模型的泛化能力。
交叉验证:使用交叉验证可以更好地评估模型的性能,并帮助选择适当的模型和参数配置,以避免过拟合问题。

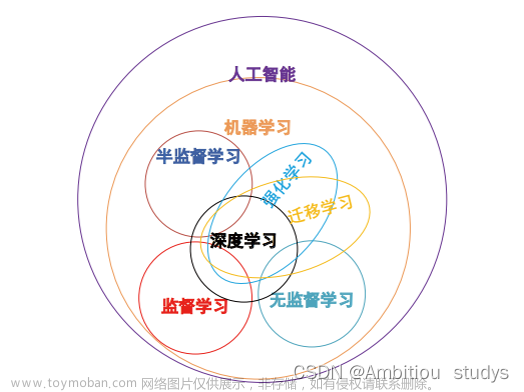
机器学习算法分类
监督学习
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
监督式学习的常见应用场景
分类问题:目标值离散
回归问题:目标值连续
无监督学习
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。
半监督学习
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
强化学习
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
强化学习是一个动态过程,上一步数据的输出是下一步数据的输入。
强化学习基本结构如图所示,和人类大脑学习的过程非常地类似,agent(人)在某种场景(state)下,做出某种行为(action),得到某种反馈(reward),这就是强化学习的四要素:状态(state)、动作(action)、策略(policy)、奖励(reward)。通过与环境的不断交互,agent可以优化自己做决策(policy)的正确性,以获取整个交互过程的最大收益。
意义:
提高预测性能: 了解过拟合和欠拟合的问题有助于选择适当的模型和调整参数,提高机器学习模型在大数据上的预测性能。
优化算法选择: 理解不同类型的机器学习算法有助于在大数据场景中选择合适的算法,以更好地满足任务需求。
加强模型解释力: 通过深入理解模型的过拟合和欠拟合问题,可以更好地解释模型在大数据中的预测结果,增强对模型的信任度。文章来源:https://www.toymoban.com/news/detail-758613.html
因此,深入了解过拟合、欠拟合以及机器学习算法分类对于在大数据背景下构建高效、准确的机器学习和深度学习模型至关重要。文章来源地址https://www.toymoban.com/news/detail-758613.html
到了这里,关于大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!