目录
1.背景
1.1 名词解释、
1.2 业务场景
1.3 kafka消息的优点和缺点
1.4 kafka客户端重试框架
2.使用
2.1 引入pom依赖
2.2 定义重试消息,死信队列
2.3 业务执行异常处理
3.代码分析
3.1 服务启动扫描配置
3.2 消费消息并重新投递
3.3 控制消息重试频率及死信队列
3.4 控制消息的重试时间
1.背景
1.1 名词解释、
| 名词 |
概念 |
| 事务 |
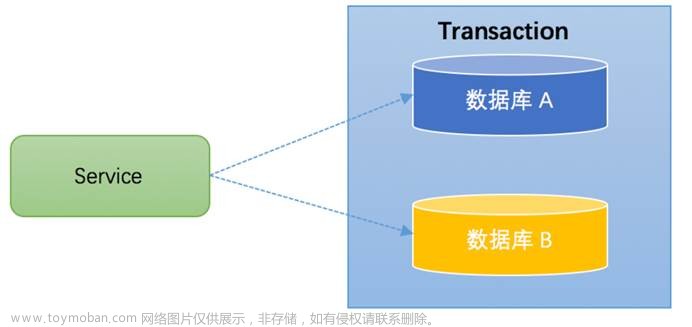
在后端应用中,是访问和更新数据库的程序执行单元,会把所有的命令作为一个整体,即这一组执行命令要么都执行成功,要么都不执行。 |
| 分布式事务 |
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。 |
| 幂等 |
指对一个业务操作,多次执行,带来的效果一样。 |
| 死信队列 |
无法被消费的消息或者重试消费执行都失败被放在一个指定的队列 |
1.2 业务场景
近期项目需要解决分布式事务的问题,当时讨论了多次,决定采用事务的最终一致性,但是我们由于限制mq只有mqtt和kafka。所以使用kafka消息重试去解决问题,
以下是当时的方案 图

1.3 kafka消息的优点和缺点
kafka擅长解决大批量的消息推送,高吞吐量,比较高的数据可靠性(一定策略下可以保证消息不丢失问题)。
但是很遗憾,kafka中间件并不如市面上擅长处理业务的消息中间件如rocketmq,nsq一样可以控制消息的频率,重试次数等功能。
那么我们只需要解决消息重试机制(重试次数,重试间隔,重试策略,异常通知)等问题
1.4 kafka客户端重试框架
当我准备参考了以前公司2018年中间件团队的代码准备写一个重试机制的kafka客户端框架的时候,发现并不那么简单。当时的代码只是捕获到异常后丢到了原来的topic里面,只有简单的重试次数功能,
缺点:
1.丢到原来的topic,可能导致重试topic阻塞到原来的业务执行。
2.无法精确控制到重试时间,超过重试次数后的死信队列没有
3.控制次数放到了内存里面,系统重启将失去重试机会(对于重要的业务失去重试机会有可能代表这整条业务单据无法使用,甚至造成重大资金损失)
偶然的机遇发现springkafka客户端在2021年的时候居然实现了这个功能,于是看了看官方的@retryTopick框架代码,发现spring为了写这个也是下了大的功夫,这个模块代码量也是惊人,代码复杂度自己断点都看晕了。
2.使用
2.1 引入pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>2.2 定义重试消息,死信队列
/**
* @author zhongxingtang
* @desc kafka消息接受工具
*/
@Slf4j
@Component
public class KafkaMQListener {
@KafkaListener(topics = {"BMOS_TOP_TEST"}, groupId = "${spring.application.name}")
@RetryableTopic(
attempts = "4",
backoff = @Backoff(delay = 5000, multiplier = 2),
fixedDelayTopicStrategy = FixedDelayStrategy.SINGLE_TOPIC
)
/**
* attempts:重试次数,默认为3。
*
* @Backoff delay:消费延迟时间,单位为毫秒。
*
* @Backoff multiplier:延迟时间系数,此例中 attempts = 4, delay = 5000, multiplier = 2 ,则间隔时间依次为5s、10s、20s、40s,最大延迟时间受 maxDelay 限制。
*
* fixedDelayTopicStrategy:可选策略包括:SINGLE_TOPIC 、MULTIPLE_TOPICS
*/
public void listener(ConsumerRecord<String, String> record) {
// 获取消息体
String message = record.value();
log.info("收到测试消息,message = {}, record={}", message, JSONObject.toJSONString(record));
// todo 写重试业务消息
}
@DltHandler
public void dltHandler(ConsumerRecord<String, String> record) {
log.info("进入死信队列 record={}", JSONObject.toJSONString(record));
// todo 写重试多次失败后的业务,例如短信,报警,存数据库等。
}2.3 业务执行异常处理
public ResponseInfo<Boolean> startFormulaWorkFlow(@Validated @RequestBody WorkflowStartDTO dto) {
try {
// 执行可重试业务异常
workflowService.startFormulaWorkflow(dto);
} catch (Exception e) {
log.warn("计划执行-发起流程失败重试,dto = {}, e = {}", JsonUtils.toJsonString(dto), e);
//捕捉异常,丢到kafka消息里面,进行重试
kafkaMQProducer.send(WORKFLOW_FORMULA_WORKFLOW, JsonUtils.toJsonString(dto));
}
return ResponseInfo.SUCCESS();
}总结:简单,无脑,粗暴,好用。
3.代码分析
客户端消息如何重试?是自己封装的消息队列重试还是丢到了kafka服务端重试呢
如何控制消息的重试时间和频率,进入死信队列
(kafka不会犯这么低级的错误,简单的只维护一个本地延时队列来跑,否则服务断开,消息全丢失了)
3.1 服务启动扫描配置
3.1.1 后置处理器扫描注解
KafkaListenerAnnotationBeanPostProcessor#postProcessAfterInitialization
后置处理器扫描到带有@KafkaListener、, @RetryableTopic注解


3.1.2 解析重试参数,并放入上下文中
org.springframework.kafka.retrytopic.RetryTopicConfigurer

3.2 消费消息并重新投递
链路太长,只贴重要的图
org.springframework.kafka.listener.KafkaMessageListenerContainer.ListenerConsumer#run
org.springframework.kafka.listener.KafkaMessageListenerContainer.ListenerConsumer#pollAndInvoke
KafkaMessageListenerContainer.ListenerConsumer#invokeIfHaveRecords
KafkaMessageListenerContainer.ListenerConsumer#doInvokeWithRecords
KafkaMessageListenerContainer.ListenerConsumer#doInvokeRecordListener
3.2.1执行消息消费,捕获异常

org.springframework.kafka.listener.KafkaMessageListenerContainer.ListenerConsumer#invokeErrorHandler
org.springframework.kafka.listener.DefaultErrorHandler#handleRemaining
org.springframework.kafka.listener.FailedRecordProcessor#getRecoveryStrategy
org.springframework.kafka.listener.FailedRecordTracker#recovered
org.springframework.kafka.listener.FailedRecordTracker#attemptRecovery
org.springframework.kafka.listener.DeadLetterPublishingRecoverer#accept
3.2.2 捕获异常,重新投递消息。

3.2.3 组装第二次投递消息参数,send消息

3.3 控制消息重试频率及死信队列
3.3.1控制重试次数配置
消息重试次数配置到了@RetryableTopic,attempts = "5"里面

3.3.2 重试次数初始化信息
按照正常思维,一般人都是考虑一次一次重试,记录次数直到到达最大次数进入死信队列
可以这个地方断点了无数次,也没找到在哪判断,最终在启动容器的时候发现提前创建了一个链表结构,
topic100->topic200->topic500 .....>top-dtl(死信队列)
(spring为了提升执行速度快真是拼了命了,有个大胆的想法,写个1000万重试次数,内存都要爆炸了吧)
典型的极致空间换时间
初始化context,记录每一个节点信息,通过直到next的节点为空代表重试次数结束(或者不再抛异常中断)

3.3.3 获取下一次重试节点
org.springframework.kafka.retrytopic.DefaultDestinationTopicResolver#resolveDestinationTopic
org.springframework.kafka.retrytopic.DefaultDestinationTopicResolver#resolveRetryDestination
retrytopic.DefaultDestinationTopicResolver.DestinationTopicHolder#getNextDestination

链表结构

节点具体信息

3.3.4 组装下一次重试的topic信息
每次在trycatch 捕获异常后,根据当前链表获取下一个节点的信息。放入下一个重试消息的topic_head里面做标记,

3.3.4 dlt 死信队列
消息消费-dlt 的topic,执行死信队列的自定义业务

3.4 控制消息的重试时间
kafka服务起是顺序存储到磁盘里面,不会带提供阻塞功能,很明显对号称史上吞吐量最大的消息服务器,服务器怎么可能提供这个功能来牺牲自己的性能呢?
kafka通过不断的拉取最新分区的消息,当判断当前执行时间<想要执行的时间判断,不满足的情况下,记录信息,并抛出异常中断。
3.4.1 设置下一个topic的预期执行时间
org.springframework.kafka.retrytopic.DeadLetterPublishingRecovererFactory#create
org.springframework.kafka.retrytopic.DeadLetterPublishingRecovererFactory#addHeaders
kafka.retrytopic.DeadLetterPublishingRecovererFactory#getNextExecutionTimestamp

3.4.2 将预期执行时间设置到head里面
org.springframework.kafka.listener.DeadLetterPublishingRecoverer#sendOrThrow

3.4.3 循环消费消息,判断是否到达预期时间
org.springframework.kafka.listener.KafkaMessageListenerContainer.ListenerConsumer#run

从head里面获取预期执行时间,判断是否到达预期执行时间
org.springframework.kafka.listener.adapter.KafkaBackoffAwareMessageListenerAdapter#onMessage

3.4.4 未到达预期消费时间,打断消费。
当判断当前执行时间<想要执行的时间判断,不满足的情况下,记录信息,并抛出异常中断。
org.springframework.kafka.listener.PartitionPausingBackoffManager#backOffIfNecessary

3.4.5 持续消费消息并判断,直到满足预期消费时间
循环下一次,直到当前执行时间>=想要执行的时间,放行执行业务逻辑
listener.adapter.KafkaBackoffAwareMessageListenerAdapter#invokeDelegateOnMessage
org.springframework.kafka.listener.adapter.RecordMessagingMessageListenerAdapter#onMessage
org.springframework.kafka.listener.adapter.MessagingMessageListenerAdapter#invokeHandler
org.springframework.kafka.listener.adapter.HandlerAdapter#invoke
com.isyscore.bmos.formula.mq.KafkaMQListener#listener文章来源:https://www.toymoban.com/news/detail-758999.html
 文章来源地址https://www.toymoban.com/news/detail-758999.html
文章来源地址https://www.toymoban.com/news/detail-758999.html
到了这里,关于springKafka 重试解决分布式事务的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!