1 Distil-Whisper诞生
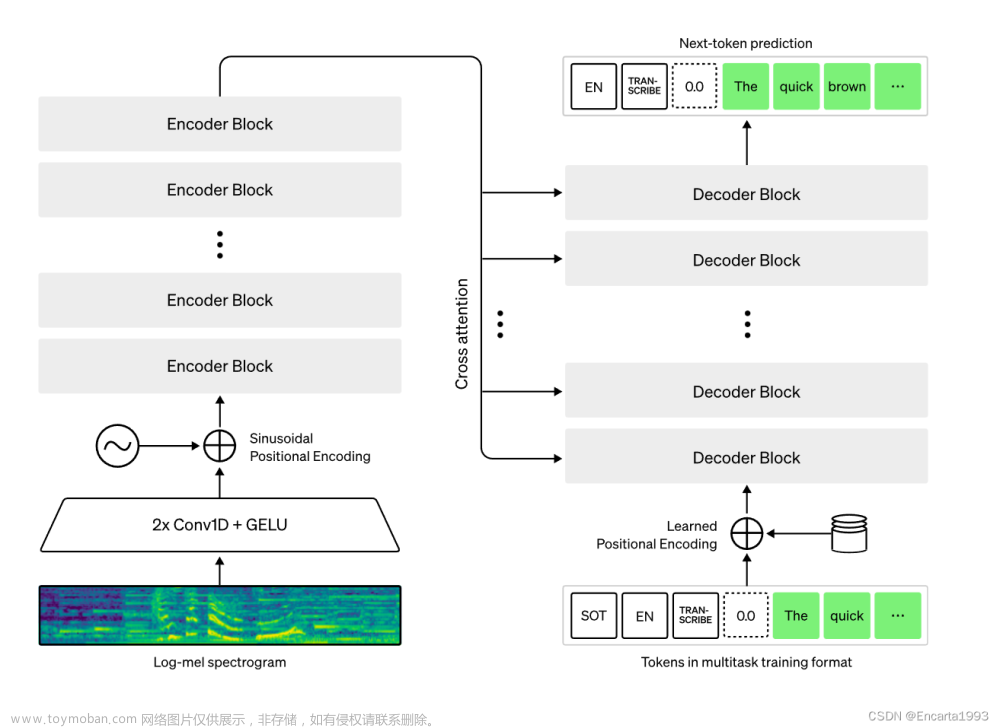
Whisper 是 OpenAI 研发并开源的一个自动语音识别(ASR,Automatic Speech Recognition)模型,他们通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高模型对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。目前,Whisper 已经有了很多变体,也成为很多 AI 应用构建时的必要组件。
最近,来自 HuggingFace 的团队提出了一种新变体 —— Distil-Whisper。这个变体是 Whisper 模型的蒸馏版,特点是模型小、速度快,而且准确度还很高,非常适合在要求低延迟或资源有限的环境中运行。不过,与能够处理多种语言的原始 Whisper 模型不同,Distil-Whisper 只能处理英文。
论文地址:https://arxiv.org/pdf/2311.00430.pdf
github地址:https://github.com/huggingface/distil-whisper
模型地址:https://aifasthub.com/models/openai
2 技术突破
Distil-Whisper不仅继承了原始Whisper模型的优秀血统,更在性能和速度上进行了显著的提升。专为英语设计的Distil-Whisper,在减小模型体积的同时,实现了处理速度的大幅跳跃,这在现有的AI语音识别技术中堪称一次创新的突破。

文章来源地址https://www.toymoban.com/news/detail-759100.html
具体来说,Distil-Whisper 有两个版本,参数量分别为 756M(distil-large-v2)和 394M(distil-medium.en)。
与 OpenAI 的 Whisper-large-v2 相比,756M 版本的 distil-large-v2 参数量减少了一半还多,但实现了 6 倍的加速,而且在准确程度上非常接近 Whisper-large-v2,在短音频的 Word Error Rate(WER)这个指标上相差在 1% 以内,甚至在长音频上优于 Whisper-large-v2。这是因为通过仔细的数据选择和过滤,Whisper 的稳健性得以保持,幻觉得以减少。
3 与OpenAI Whisper比较
Distil-Whisper以更小的模型体积和更快的响应速度,展现了其在AI语音识别领域的独特价值。与OpenAI的Whisper相比,Distil-Whisper更适合运行在资源有限的设备上,如移动设备和嵌入式系统,同时其在长音频处理和噪声抑制上的表现,也显示了其独到的优势。
| Model | Params / M | Rel. Latency | Short-Form WER | Long-Form WER |
|---|---|---|---|---|
| whisper-large-v2 | 1550 | 1.0 | 9.1 | 11.7 |
| distil-large-v2 | 756 | 5.8 | 10.1 | 11.6 |
| distil-medium.en | 394 | 6.8 | 11.1 | 12.4 |
Distil-Whisper通过精心的数据选择和过滤,以及伪标签技术的应用,Distil-Whisper在保持原有模型鲁棒性的同时,实现了速度和性能的双重提升。这一技术的深度和细节,无疑将为AI语音识别领域带来新的启示。

Distil-Whisper的轻量化和高效性能使其在多种实际应用场景中大放异彩。无论是在快速的实时语音翻译,还是在嘈杂环境下的清晰语音捕捉,Distil-Whisper都能提供出色的解决方案,展现AI技术的实用性和创新性。
4 AI语音识别的新时代
随着Distil-Whisper这样的技术不断成熟和发展,我们正迈入一个全新的AI语音识别时代。这个时代不仅仅是关于技术的进步,更是关于如何将这些进步转化为实际应用,从而影响和改善我们的工作和生活。Distil-Whisper的出现,不仅为技术专家和开发者提供了新的工具,也为广大用户打开了通向便捷、高效未来世界的大门。文章来源:https://www.toymoban.com/news/detail-759100.html
到了这里,关于OpenAI的Whisper蒸馏:蒸馏后的Distil-Whisper速度提升6倍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!