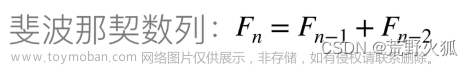问题汇总:
1.如何选择使用递归法解题还是迭代法解题
(我猜是做的多了背的题多了就自然懂了)
2.迭代法有没有可以去重的空间和套路
迭代法一般没有通用去重方式,因为已经相当于递归去重后了
这两个问题其实是一个问题,一般直接写出的没有去重的递归法,复杂度很高,此时需要使用备忘录去重,而备忘录去重时间复杂度和使用dp数组进行迭代求解时间复杂度相同,但是由于递归需要反复调用函数,实际开销更加多
综上,一般使用dp数组法最优
一、动态规划基本框架
1.1 动态规划用于解决的问题?(如何判断能否使用dp)
动态规划 = 最优子结构 + 重叠子问题 + 转移方程
最优子结构保证能从局部解推出全局解,也就是保证能够写出转移方程
重叠子问题说明暴力解法太耗时,我们可以使用动态规划进行优化
(期待后期的更改,相信未来的我的智慧!)
「最优子结构」是某些问题的一种特定性质,并不是动态规划问题专有的。也就是说,很多问题其实都具有最优子结构,只是其中大部分不具有重叠子问题,所以我们不把它们归为动态规划系列问题而已。
我先举个很容易理解的例子:假设你们学校有 10 个班,你已经计算出了每个班的最高考试成绩。那么现在我要求你计算全校最高的成绩,你会不会算?当然会,而且你不用重新遍历全校学生的分数进行比较,而是只要在这 10 个最高成绩中取最大的就是全校的最高成绩。
我给你提出的这个问题就符合最优子结构:可以从子问题的最优结果推出更大规模问题的最优结果。让你算每个班的最优成绩就是子问题,你知道所有子问题的答案后,就可以借此推出全校学生的最优成绩这个规模更大的问题的答案。
你看,这么简单的问题都有最优子结构性质,只是因为显然没有重叠子问题,所以我们简单地求最值肯定用不出动态规划。
再举个例子:假设你们学校有 10 个班,你已知每个班的最大分数差(最高分和最低分的差值)。那么现在我让你计算全校学生中的最大分数差,你会不会算?可以想办法算,但是肯定不能通过已知的这 10 个班的最大分数差推到出来。因为这 10 个班的最大分数差不一定就包含全校学生的最大分数差,比如全校的最大分数差可能是 3 班的最高分和 6 班的最低分之差。
这次我给你提出的问题就不符合最优子结构,因为你没办通过每个班的最优值推出全校的最优值,没办法通过子问题的最优值推出规模更大的问题的最优值。前文 动态规划详解 说过,想满足最优子结,子问题之间必须互相独立。全校的最大分数差可能出现在两个班之间,显然子问题不独立,所以这个问题本身不符合最优子结构。
那么遇到这种最优子结构失效情况,怎么办?策略是:改造问题。对于最大分数差这个问题,我们不是没办法利用已知的每个班的分数差吗,那我只能这样写一段暴力代码:
int result = 0;
for (Student a : school) {
for (Student b : school) {
if (a is b) continue;
result = max(result, |a.score - b.score|);
}
}
return result;
改造问题,也就是把问题等价转化:最大分数差,不就等价于最高分数和最低分数的差么,那不就是要求最高和最低分数么,不就是我们讨论的第一个问题么,不就具有最优子结构了么?那现在改变思路,借助最优子结构解决最值问题,再回过头解决最大分数差问题,是不是就高效多了?
1.2 迭代(自底向上)-五部曲(自底向上的迭代求解)
1.2.1 明确dp数组下标和下标对应的值的含义
这一步其实是要和转移方程结合理解的,很多时候我们是为了能够写出转移方程,才进行某种dp数组的定义
所以这一步非常重要,我们需要知道问题中有哪些状态才能为dp数组合理分配这些状态
所谓状态,也就是原问题和子问题中会变化的变量。我们要将这些变化的量分配给dp数组的下标和值
注意:比较难的题,状态不能一眼看出来,需要我们自己进行构造,这样的题只有靠积累
简单例子

1:斐波那契的dp[]定义:i 表示n = i,dp[i]表示n = i对应的结果是什么,这样的逻辑非常清晰

2:凑零钱:(注意虽然硬币个数不会变化,因为硬币数量无限,所以有两个变化量,凑零钱的硬币数和目标金额),所以我们定义i为目标金额,dp[i]值为零钱个数(一般都会吧dp[i]当作输出结果)
这里会有一点歧义 ,我们要知道我们最后要得到的是什么,应该是amount对应的最小数量,那么dp[i]应该设置为金额i对应的最小数量,不要思考成我们将dp[i]定义为i对应的所有数量,然后通过比较所有dp[i]来求得最小值,这样似乎更容易理解,但是却不实际,那样dp[i]会被定义为二维数组,复杂度也上升了
我们应该知道,最小这个限制,是在转移方程里面实现的,所以我们默认得到的dp[i]就是最小值!
困难例子
最长递增子序列:我们发现问题中貌似没有直接给出变化的状态,从而无从下手
这是子序列问题中的一类问题,处理方法有相对固定几类,我们这里就直接套用经典定义
dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列的长度。
对于其他不明确状态的问题如何定义,这个也要靠积累,需要我们多做题才知道
1.2.2 确定递推公式(转移方程)
动态规划的核心设计思想是数学归纳法。
相信大家对数学归纳法都不陌生,高中就学过,而且思路很简单。比如我们想证明一个数学结论,那么我们先假设这个结论在 k < n 时成立,然后根据这个假设,想办法推导证明出 k = n 的时候此结论也成立。如果能够证明出来,那么就说明这个结论对于 k 等于任何数都成立。
类似的,我们设计动态规划算法,不是需要一个 dp 数组吗?我们可以假设 dp[0...i-1] 都已经被算出来了,然后问自己:怎么通过这些结果算出 dp[i]?
直接拿最长递增子序列这个问题举例你就明白了。不过,首先要定义清楚 dp 数组的含义,即 dp[i] 的值到底代表着什么?
我们的定义是这样的:dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列的长度(子序列中要包含nums[i],可能我们会想这样不能找到实际的最大子序列,但是其实我们遍历了所有nums[i],并不会漏掉)。

假设我们已经知道了 dp[0..4] 的所有结果,我们如何通过这些已知结果推出 dp[5]
这就是求解转移方程的重点一步,此处
根据刚才我们对 dp 数组的定义,现在想求 dp[5] 的值,也就是想求以 nums[5] 为结尾的最长递增子序列。
其实就是自己总结规律,然后使用数学归纳法验证
光靠脑袋想dp的递推公式确实很困难 我的做法是画一个dp数组出来 找一个例子填进去,然后通过观察找出规律倒推递推公式(仅供参考,有待验证)
当我们发现递推公式不好找时,需要思考是否改变dp定义
nums[5] = 3,既然是递增子序列,我们只要找到前面那些结尾比 3 小的子序列,然后把 3 接到这些子序列末尾,就可以形成一个新的递增子序列,而且这个新的子序列长度加一。
同时我们是在找最长的子序列,所以我们需要找出前面序列中的最长序列接上去
我们的转移方程为:
dp[i] = dp[j] + 1;//j是比i小的数接下来就是要将取最大值还有求比i小的j结合起来
代码如下:
for(int j = 0;j < i;j++){
if (nums[i] > nums[j]) {
// 把 nums[i] 接在后面,即可形成长度为 dp[j] + 1,
// 且以 nums[i] 为结尾的递增子序列
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}这整个代码才是完整的转移方程
一个重点:
我们一定要假设已经知道了dp[i-1],并且我们设置的dp数组可以存放的值就是我们希望的值
1.2.3 dp数组初始化和base case
初始化要结合我们对dp数组的定义进行设置,并且结合保证在执行max和min操作时不会影响更新值,对dp数组的定义不同的话,初始化也会有差别
(有其他理解后面补充)
base case 就是递归中的最底层,是所有子问题中的最基础的问题,靠这个问题推出其他所有解
初始化非常重要,它和转移方程共同决定了我们定义的dp[i]里面的值是否正确,一般是确定了dp定义和转移方程,再开始初始化
1.2.4 确定遍历顺序
现在接触到的都是顺序进行遍历的,并没有在遍历时挖坑,但是后面有从前往后,从后往前还有斜着遍历
这些情况的分析等到做到具体的题目再来补充
将转移方程放入遍历中:
for(int i = 0;i < nums.size();i++)
for(int j = 0;j < i;j++){
if(nums[i] > nums[j]){
dp[i] = max(dp[i],dp[j]+1);
}
}1.2.5 dp数组打印
通过递推公式手写出dp数组,用于检测dp哪里写错了
1.3 递归(自顶向上)
1.3.1 暴力解法
按道理来说,应该是先写出递归法,然后通过备忘录进行优化,再然后使用dp数组的解法来解答,这里由于dp数组法有一套成熟的流程,我这里想写递归法时,会将迭代法先写出来,然后使用套用到递归中。
1.3.2 备忘录去重
明确了问题,其实就已经把问题解决了一半。即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。
注意:递归法使用备忘录去重后,尽管时间复杂度和迭代相同,但是,我们递归会不断的在栈上调用函数,造成大量的内存和时间消耗,这会导致实际运行时,递归法的时间空间消耗大于迭代法
详情参考:
第七章 C语言函数_递归函数的致命缺陷:巨大的时间开销和内存开销(附带优化方案)_c++ 递归资源消耗-CSDN博客
1.3.3 dp table去重
就是迭代法,这样的做法时间复杂度和备忘录去重一致
二、经典dp问题-用于理解dp的做法和细节
2.1 零钱兑换
题目链接:322. 零钱兑换 - 力扣(LeetCode)

(1)dp定义:
首先确定状态,问题中改变的状态只有总金额和使用的硬币个数(硬币总数无限,所以剩下的硬币数量不变化)
我们将dp[i]和i与变化量进行匹配,从而有如下设置:
i为总金额。dp[i]为达到总金额i需要的硬币数量
(2)转移方程
我们这样想,肯定是要建立dp[i]和dp[j]的联系,但实际这个i j应该如何取,也就是总金额如何变化更合理,所以自然想到了,每次对总金额 i 减少一个硬币的值,来求得 j ,那么关系如何建立呢
这就要用到上面的数学归纳法了,假设我们已经知道减少一个硬币后的dp[i - coin]的值,那么dp[i]的最小值就是dp[i - coin]+1
(3)初始化
由于我们的i要索引到amount,索引dp的size要为amount+1,同时对于dp[i]来说,最差的情况即使由i个一元硬币组成,那么最大个数为i,为了使得初始状态不影响结果,需要将dp[i] 赋值 i+1,为了省事直接赋值最大的amount+1,代码如下:
vector<int> dp(amount+1,amount+1);对于base case,我们知道dp[0] = 0,但是注意dp[1] != 1,因为有一个硬币但不一定是一个一元的硬币,所有可能dp[1] = -1,因此不能将dp[1]放入base case中,代码如下:
dp[0] = 0;
// dp[1] = 1;(4)确定遍历方向:
此题为顺序遍历,但是也要仔细理解一下
非常类似bfs的理解过程,我们先对dp[i]中所有金额从0-amount进行遍历,保证能够处理到所有的i(类似于走通每一层),然后对于每一个i我们都将所有的coin去除一次(所有的选择都选一次),选出最小的情况然后赋值给dp[i]
代码如下:
for(int i = 0;i < amount+1;i++)
for(int coin : coins){
if(i - coin < 0)continue;
dp[i] = min(dp[i],dp[i - coin] + 1);
}5 :打印dp数组进行debug,此题过程比较简单就不演示了
完整代码如下:
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount+1,amount+1);
if(amount == 0)return 0;
dp[0] = 0;
// dp[1] = 1;
for(int i = 0;i < amount+1;i++)
for(int coin : coins){
if(i - coin < 0)continue;
dp[i] = min(dp[i],dp[i - coin] + 1);
}
return dp[amount] == amount+1 ? -1 : dp[amount];
}
};2.2 斐波那契数列
题目链接:509. 斐波那契数 - 力扣(LeetCode)

此题已经给出转移方程,并且dp数组的定义也较为清楚,base case给出,初始化时没有特殊要求,我们直接初始化为0就行了,并且也是顺序遍历,所有很容易写出如下代码:
class Solution {
public:
int fib(int n) {
if(n==0) return 0;
vector<int> dp(n+1,0);
dp[0] = 0;
dp[1] = 1;
for(int i = 2;i <= n;i++)
dp[i] = dp[i-1] +dp[i-2];
return dp[n];
}
};由于只涉及到两个数的处理,所以我们可以只保留这两个数,有如下优化代码:
class Solution {
public:
int fib(int n) {
if(n==0)return 0;
if(n==1)return 1;
int p=0,q=1,res=0;
for(int i = 2;i <= n;i++){
res = p + q;
p = q;
q = res;
}
return res;
}
};三、子序列问题
子序列子串问题总结:
1.dp定义
一般有两种dp定义
1)dp[i]表示以nums[i]结尾(包含i)的结果
2)dp[i]表示以[0,i]的子串(不要求包含i)的结果
单序列问题,一般使用(1),因为只有一条单序列,(1)更容易将前后关系链接起来
双序列问题:
一般要求连续(子串,子数组)就使用(1),不连续(子序列)就使用(2)
(注意:为例初始化方便,一般的dp[i][j]对应nums[i-1]和nums2[j-1])
2.转移方程
转移方程的确立本质上就是分情况讨论
对于单序列,我们一般会判断nums[i]和nums[i-1]的关系,或者判断dp[i-1]等等,分情况讨论如何从dp[i-1]转移到dp[i]
(单序列的判断更加灵活)
对于双序列问题,一般会对比nums1[i]和nums2[j],通常相同时,我们考虑dp[i-1][j-1]转移到dp[i][j],而不同时考虑dp[i-1][j-1],dp[i][j-1],dp[i-1][j]如何转移到dp[i][j],例如下图:

如何转移?
一般都是通过+的形式进行转移
3.初始化
这一步需要在转移方程之后写,因为我们要确定转移方程可行,才能开始初始化,首先我们要画出如下的dp数组(此处针对双序列,单序列一般只初始化dp[0])

根据dp数组定义在橙色位置填上初始值,然后可以使用转移方程检查一下合理
图中红字很重要
4.遍历顺序
从初始化开始往后遍历即可,类似下图:

5.检查dp数组
觉得有问题,就把dp数组打印出来, 看和画的一样不
3.1单序列问题
3.1.1 最长递增子序列
题目链接:300. 最长递增子序列 - 力扣(LeetCode)

1:首先确定如何定义dp数组
我们使用子序列一般定义方式,定义dp[i]为以nums[i]结尾的子序列的解(也即是这一部分的严格递增子序列最大长度) ,注意:这里特别还有一点,求得的最大子序列必须包含nums[i],为了和之后的转移方程进行匹配
2:确定转移方程
转移方程的确定一定要根据数学归纳法来求解,因为我们要求dp[nums.size()],所以我们假设知道dp[0,.....,nums.size()-1],直接理解不是很清晰,作图如下:
为了推导到更一般的情况,我们假设前面已知的为dp[i],当前需要求得的时dp[j],因为每一个子序列的解必须包含nums[i],所以如果当前的nums[j]比前面某一个nums[i]大的话,就可以直接接在后面,那么dp[j]的解至少也是dp[i]+1。
最后想要求得dp[j]实际上比dp[i]大多少,我们只需要比较所有比nums[j]小的nums[i],选取最大的dp[i]进行+1即可
因此转移方程为:
for(int i = 0;i < j; i++)
if(nums[j] > nums[i])
dp[j] = max(dp[j],dp[i]+1)3:确定初始状态
由于dp[i]表示nums[i]结尾且包含nums[i]的解,所有解的长度至少为1,也就是nums[i]本身,因此我们需要对dp[i]初始化为1;
4:遍历顺序
由于我们求解dp[j]时会用到dp[0,..,j-1]所有我们顺序遍历即可
5:打印dp

完整代码如下:
dp数组法
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n,1);
dp[0] = 1;
for(int i = 0;i < nums.size();i++)
for(int j = 0;j < i;j++){
if(nums[i] > nums[j]){
dp[i] = max(dp[i],dp[j]+1);
}
}
int res=0;
for(int i : dp){
res = max(res,i);
}
return res;
}
};时间复杂度O(n^2)
此题有一种更加巧妙的解法,可以进一步降低时间复杂度:
二分法:
int lengthOfLIS(vector<int>& nums) {
int piles = 0; // 牌堆数初始化为 0
vector<int> top(nums.size()); // 牌堆数组 top
for (int i = 0; i < nums.size(); i++) {
int poker = nums[i]; // 要处理的扑克牌
/***** 搜索左侧边界的二分查找 *****/
int left = 0, right = piles; // 搜索区间为 [left, right)
while (left < right) {
int mid = (left + right) / 2; // 防溢出
if (top[mid] > poker) {
right = mid;
} else if (top[mid] < poker) {
left = mid + 1;
} else {
right = mid;
}
}
/*********************************/
// 没找到合适的牌堆,新建一堆
if (left == piles) piles++;
// 把这张牌放到牌堆顶
top[left] = poker;
}
// 牌堆数就是 LIS 长度
return piles;
}时间复杂度O(n*log2n)
3.1.2 俄罗斯套娃信封

此题为最长递增递增子序列的二维形式,本质还是找形状递增的最长子信封,主要问题在于,我们如何将形状引入进行比较
此处处理十分的巧妙:
先对宽度 w 进行升序排序,如果遇到 w 相同的情况,则按照高度 h 降序排序;之后把所有的 h 作为一个数组,在这个数组上计算 LIS 的长度就是答案。

为什么是这样呢,因为我们先使得宽度排好序,然后对高度求最长递增子序列,就能得到递增的信封,但是考虑到相同宽度不能相互装,也即是同一宽度我们只能使用一个信封,所以我们选择将同一宽度下的高度进行降序,这样在降序中,只有可能取其中之一(因为我们找的是升序排列)
lambda
这里引入lambda表达式进行排序:
c++ lambda 看这篇就够了!(有点详细)_c++ 运行时 构建 lamda-CSDN博客
sort(envelopes.begin(), envelopes.end(),
[](const vector<int> a, const vector<int>& b) {
// return a[0] == b[0] ? b[1] - a[1] : a[0] - b[0];
if (a[0] != b[0]) {
return a[0] < b[0]; // 按宽度升序排序
} else {
return a[1] > b[1]; // 如果宽度相同,按高度升序排序
}
});然后我们对排好序的信封的高进行最长递增子序列求解,直接调用函数即可
dp数组法:
int maxseq(vector<int>& seq) {
int size = seq.size(),res= 0;
vector<int> dp(size,1);
dp[0] = 1;
for(int i = 0;i< size;i++){
for(int j = 0;j< i;j++){
if(seq[i] > seq[j]){
dp[i] = max(dp[i],dp[j]+1);
}
}
res = max(dp[i],res);
}
return res;
}二分法:
int lengthOfLIS(vector<int>& nums) {
int piles = 0; // 牌堆数初始化为 0
vector<int> top(nums.size()); // 牌堆数组 top
for (int i = 0; i < nums.size(); i++) {
int poker = nums[i]; // 要处理的扑克牌
/***** 搜索左侧边界的二分查找 *****/
int left = 0, right = piles; // 搜索区间为 [left, right)
while (left < right) {
int mid = (left + right) / 2; // 防溢出
if (top[mid] > poker) {
right = mid;
} else if (top[mid] < poker) {
left = mid + 1;
} else {
right = mid;
}
}
/*********************************/
// 没找到合适的牌堆,新建一堆
if (left == piles) piles++;
// 把这张牌放到牌堆顶
top[left] = poker;
}
// 牌堆数就是 LIS 长度
return piles;
}值得一提的是,本题由于一些恶心的例子,只有使用二分法求解递增子序列才不会超时
完整代码如下:
class Solution {
public:
//超时
int maxseq(vector<int>& seq) {
int size = seq.size(),res= 0;
vector<int> dp(size,1);
dp[0] = 1;
for(int i = 0;i< size;i++){
for(int j = 0;j< i;j++){
if(seq[i] > seq[j]){
dp[i] = max(dp[i],dp[j]+1);
}
}
res = max(dp[i],res);
}
return res;
}
//不超时
int lengthOfLIS(vector<int>& nums) {
int piles = 0; // 牌堆数初始化为 0
vector<int> top(nums.size()); // 牌堆数组 top
for (int i = 0; i < nums.size(); i++) {
int poker = nums[i]; // 要处理的扑克牌
/***** 搜索左侧边界的二分查找 *****/
int left = 0, right = piles; // 搜索区间为 [left, right)
while (left < right) {
int mid = (left + right) / 2; // 防溢出
if (top[mid] > poker) {
right = mid;
} else if (top[mid] < poker) {
left = mid + 1;
} else {
right = mid;
}
}
/*********************************/
// 没找到合适的牌堆,新建一堆
if (left == piles) piles++;
// 把这张牌放到牌堆顶
top[left] = poker;
}
// 牌堆数就是 LIS 长度
return piles;
}
int maxEnvelopes(vector<vector<int>>& envelopes) {
int n = envelopes.size();
// 按宽度升序排列,如果宽度一样,则按高度降序排列
sort(envelopes.begin(), envelopes.end(),
[](const vector<int> a, const vector<int>& b) {
// return a[0] == b[0] ? b[1] - a[1] : a[0] - b[0];
if (a[0] != b[0]) {
return a[0] < b[0]; // 按宽度升序排序
} else {
return a[1] > b[1]; // 如果宽度相同,按高度升序排序
}
});
// 对高度数组寻找 LIS
vector<int> height(n);
for (int i = 0; i < n; i++){
height[i] = envelopes[i][1];
// cout<<envelopes[i][0]<<envelopes[i][1]<<endl;
}
return lengthOfLIS(height);
}
};3.1.3 最长连续递增子序列
题目链接:674. 最长连续递增序列 - 力扣(LeetCode)

因为要求连续,所以我们对在上一题基础上,只对相邻两个值进行判断, 转移方程如下:
if(nums[i] > nums[i-1])
dp[i] = dp[i-1]+1;
res = max(res,dp[i]);完整代码如下:
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
if(nums.size()==0)return 0;
int res =1;
vector<int> dp(nums.size(),1);
for(int i = 1;i < nums.size() ;i++){
if(nums[i] > nums[i-1])
dp[i] = dp[i-1]+1;
res = max(res,dp[i]);//上一题的优化部分,边求解边求最大值,省时间
}
return res;
}
};3.1.4 最大子序列和--转移方程涉及对以nums[i]结尾的理解

dp定义:
dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
转移方程:
依据题意,我们会很自然的想到,要通过nums[i]是否让子序列继续保持增长来作为判断条件,但事实上这样无法判断,因为当nums[i]+dp[i-1] < dp[i-1]时,也可能保留原序列继续扩展,如图:
因此我们重新思考判断条件,首先我们要明确,得到的子序列要以nums[i]结尾,所以必须以nums[i]为基准进行参考,也就是先思考一定要留下nums[i],再思考是否留下前面的子序列,应该是考虑dp[i-1]是否大于0,dp[i-1]大于0的话,nums[i]为结尾的子序列可以增加,那么可以将nums[i]接到前面子序列的后面,如果dp[i-1]小于0,那么 ums[i]为结尾的子序列加上dp[i-1]就会减少,所以我们直接保留nums[i]即可,因此代码如下图:
if(dp[i-1] < 0)
dp[i] = nums[i];
else
dp[i] = dp[i-1] + nums[i];简化一下:
dp[i] = max(dp[i-1]+nums[i],nums[i]);初始化
因为dp[i]由dp[i-1]决定,那么dp[0]就是最开始的初始状态.
根据dp[i]的定义,很明显dp[0]应为nums[0]即dp[0] = nums[0]
确定遍历顺序
递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
完整代码如下:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int n = nums.size(),res = INT_MIN;
vector<int> dp(nums);
res = dp[0];// 因为循环是从1开始,遍历不到0,所以此处直接将nums【0】赋给res,模拟一个第一轮
for(int i = 1;i < n;i++){
// if(dp[i-1] < 0)
// dp[i] = nums[i];
// else
// dp[i] = dp[i-1] + nums[i];
dp[i] = max(dp[i-1]+nums[i],nums[i]);
res= max(dp[i],res);
}
return res;
}
};
注意此处,res不是从0开始进行遍历的,那么会漏掉对dp[0]的比较,所以我们需要将dp[0]初始化为res的初值(为了不再后面再进行一层循环来求解res的最大值)
由于这里dp[i]只和dp[i-1]有关,所以我们可以使用状态压缩,使用两个变量保持dp[i]和dp[i-1]而不使用dp数组,这样空间复杂度会进一步降低
//状态压缩
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int n = nums.size(),res = INT_MIN;
int dp_0=nums[0],dp_1;
res = nums[0];
for(int i = 1;i < n;i++){
dp_1 = max(dp_0+nums[i],nums[i]);
dp_0 = dp_1;
res= max(dp_1,res);
}
return res;
}
};此题还可以使用双指针进行解答,代码如下,具体解释减数组双指针一节:
// 双指针法
class Solution {
public:
int maxSubArray(vector<int>& nums) {
// if(nums.size()==1)return nums[0];
int l=0,r=0;
int sum=0,maxsum=INT_MIN;
cout<<maxsum;
while(r<nums.size()){
sum+=nums[r];
maxsum = max(maxsum,sum);
while(sum<0){
sum-=nums[l];
// maxsum = max(maxsum,sum);
l++;
}
r++;
}
return maxsum;
}
};3.2 双序列问题
3.2.1 编辑距离--很重要的母体

迭代法:
定义:
和一般的子序列问题一样,我们对dp数组的定义为:
dp[i][j] 为以word1[i-1]和word2[j-1]结尾的两个字符串的编辑距离
为了方便初始化,后面会细说
转移方程:
这里的转移方程是最复杂的,我们要分别求解不同操作对dp[i][j]的影响。
注意:我们要从后往前操作,因为在前面插入会导致前面字符的索引更改!!!
比较word1[i]和word2[j]
插入和删除:
dp[i][j] = dp[i-1][j]+1//在word1进行插入或者删除
dp[i][j] = dp[i][j-1]+1//在word2进行插入或者删除替换:
dp[i][j] = dp[i-1][j-1]+1//在word1或者word2进行替换相等:
dp[i][j] = dp[i-1][j-1];因此,转移方程为:
if(s1[i-1] == s2[j-1])dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = min(
dp[i][j-1]+1,
dp[i-1][j]+1,
dp[i-1][j-1]+1
);
}初始化 :
我们要知道,什么时候能一眼看出答案——当其中一个字符串为空时,这里就涉及到dp数组的定义了,因为如果dp[i][j]为word1[i]和word2[j]结尾的子串的编辑距离,那么对于长度为0的字符串(空串)就无法定义,因此,我们设置dp[i][j] 为word1[i-1]和word2[j-1]结尾的子串的编辑距离
同时,注意dp 数组的每个维度比相应的字符串长度多一个单位,以便包含空字符串的情况。这就是为什么数组大小是 m+1 x n+1。因此初始化如下:
vector<vector<int>> dp(m+1,vector<int>(n+1,0));
// for(int i = 0;i < m;i++)
// dp[i][0] = i;
// for(int j = 0;j < n;j++)
// dp[0][j] = j;
for(int i = 0;i < m+1;i++)
dp[i][0] = i;
for(int j = 0;j < n+1;j++)
dp[0][j] = j;遍历顺序:
注意,这里我们虽然是从后往前处理,也就是说我们要先知道前面的才能处理后面的,因此遍历的时候需要从前往后遍历
另一方面可以这样思考:
如图
可以看出dp[i][j]是依赖左方,上方和左上方元素的,所以在dp矩阵中一定是从左到右从上到下去遍历。
将转移方程放入遍历中:
for(int i = 1;i <=m ;i++)
for(int j = 1; j <= n;j++)
{
if(s1[i-1] == s2[j-1])dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = min(
dp[i][j-1]+1,
dp[i-1][j]+1,
dp[i-1][j-1]+1
);
}
}最后,添加特殊处理的部分,代码如下:
class Solution {
public:
int min(int a, int b, int c) {
return std::min(std::min(a, b), c);
}
int minDistance(string s1, string s2) {
int m = s1.size(),n = s2.size();
if(m==0)return n;
if(n==0)return m;
//int* dp = new int[m][n];二维数组不好使用new的方式进行实现
//int[][] dp = new int[m + 1][n + 1];这样是对的
vector<vector<int>> dp(m+1,vector<int>(n+1,0));
for(int i = 0;i < m;i++)
dp[i][0] = i;
for(int j = 0;j < n;j++)
dp[0][j] = j;
for(int i = 1;i <=m ;i++)
for(int j = 1; j <= n;j++)
{
if(s1[i-1] == s2[j-1])dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = min(
dp[i][j-1]+1,
dp[i-1][j]+1,
dp[i-1][j-1]+1
);
}
}
return dp[m][n];
}
};递归法:
先明确递归的思路:
我们如何从迭代转换到递归
首先,状态转移,初始化和dp的定义是不变的,那么我们首先思考如何将dp[i][j]中的i,j体现在dp递归函数中,显而易见,答案是,传入两个参数,i,j;
int dp(string s1,int i,string s2, int j)接着是初始化,这里本来可以设置 dp[i][j] 为以word1[i]和word2[j]结尾的两个字符串的编辑距离,但为了和迭代法统一,就延续上述设置
if(i==0)return j;
if(j==0)return i;转移方程,与迭代法十分类似:
if(s1[i-1] == s2[j-1])return dp(s1,i-1,s2,j-1);
else return min(
dp(s1,i-1,s2,j)+1,
dp(s1,i,s2,j-1)+1,
dp(s1,i-1,s2,j-1)+1
);注意 ,递归法有遍历顺序,但是是自动执行的,递归中会自动执行,所以迭代法中的for循环部分可以省去:
完整代码如下:
class Solution {
public:
int minDistance(string s1, string s2) {
int m = s1.length(), n = s2.length();
return dp(s1, m, s2, n);
}
int dp(string s1,int i,string s2, int j){
if(i==0)return j;
if(j==0)return i;
if(s1[i-1] == s2[j-1])return dp(s1,i-1,s2,j-1);
else return min(
dp(s1,i-1,s2,j)+1,
dp(s1,i,s2,j-1)+1,
dp(s1,i-1,s2,j-1)+1
);
}
int min(int a, int b, int c) {
return std::min(std::min(a, b), c);
}
};
递归去重:
备忘录:
我们增加一个备忘录,将结果保存到备忘录的对应位置
memo = vector<vector<int>>(m+1, vector<int>(n+1, -1));检测这个位置是否已经有值,有的话就不用再算了
// 查备忘录,避免重叠子问题
if (memo[i][j] != -1) {
return memo[i][j];
}
// 状态转移,结果存入备忘录
if (s1[i-1] == s2[j-1]) {
memo[i][j] = dp(s1, i - 1, s2, j - 1);
} else {
memo[i][j] = min(
dp(s1, i, s2, j - 1) + 1,
dp(s1, i - 1, s2, j) + 1,
dp(s1, i - 1, s2, j - 1) + 1
);
}
return memo[i][j];可能会疑惑,为什么能保证出现过一次的memo[i][j]就一定是最优解,后面不会更新比这个值更好的解吗?

我们可以看到,每次求解dp[i][j],都是使用三种状态,那么第二次对dp[i][j]进行处理的话,也会进行同样的处理,结果是没变的
因此,完整代码如下:
class Solution {
public:
vector<vector<int>> memo;
int minDistance(string s1, string s2) {
int m = s1.length(), n = s2.length();
memo = vector<vector<int>>(m+1,vector<int>(n+1,-1));
return dp(s1, m, s2, n);
}
int dp(string s1,int i,string s2, int j){
if(i==0)return j;
if(j==0)return i;
if(memo[i][j] != -1) return memo[i][j];
if(s1[i-1] == s2[j-1])memo[i][j] = dp(s1,i-1,s2,j-1);
else memo[i][j] = min(
dp(s1,i-1,s2,j)+1,
dp(s1,i,s2,j-1)+1,
dp(s1,i-1,s2,j-1)+1
);
return memo[i][j];
}
int min(int a, int b, int c) {
return std::min(std::min(a, b), c);
}
};迭代法:

递归+备忘录:

可以看出,迭代法递归法复杂度相同时,由于递归不断调用函数产生资源消耗,其运行效率远不如迭代法
3.2.2 最长重复子数组

dp数组(dp table)以及下标的含义
dp[i][j] :以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]。 (特别注意: “以下标i - 1为结尾的A” 标明一定是 以A[i-1]为结尾的字符串 )
(此处定义同编辑距离,为了初始化方便)
转移方程:
做过编辑距离后发现,此题比较简单,因为我们dp[i][j]必须包含nums1[i-1]和nums2[j-1],所以只需要比较nums1[i-1]和nums[j-1]即可,当他们不等时,dp[i][j]=0
因此,转移方程如下:
if(nums1[i-1] == nums2[j-1]){
dp[i][j] = dp[i-1][j-1] + 1;
res = max(res,dp[i][j]);
}dp数组初始化
DP数组如下,我们发现我们需要对第一排和第一列进行初始化,才能顺利推导到后面的值

根据dp数组的意义,我们将其初始化为0即可
同时,由于某些dp值,我们会赋值为0,所以我们直接将所以初值都设置为0,当遇到应该为0的dp值,我们不更新即可,代码如下:
vector<vector<int>> dp(nums1.size()+1,vector<int>(nums2.size()+1,0));遍历顺序:
外层for循环遍历A,内层for循环遍历B。
外层for循环遍历B,内层for循环遍历A。都行
完整代码如下:
class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
vector<vector<int>> dp(nums1.size()+1,vector<int>(nums2.size()+1,0));
int res = 0;
for(int i = 1;i <= nums1.size();i++)//边界问题
for(int j = 1;j <= nums2.size();j++){
if(nums1[i-1] == nums2[j-1]){
dp[i][j] = dp[i-1][j-1] + 1;
res = max(res,dp[i][j]);
}
}
return res;
}
};3.2.3 最长重复子序列

本题和最长重复子数组区别在于这里不要求是连续的了,所以dp数组的定义不用必须以nums[i]结尾了
确定dp数组(dp table)以及下标的含义:
dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
转移方程 :
主要就是两大情况: text1[i - 1] 与 text2[j - 1]相同,text1[i - 1] 与 text2[j - 1]不相同
如果text1[i - 1] 与 text2[j - 1]相同,那么找到了一个公共元素,所以dp[i][j] = dp[i - 1][j - 1] + 1;
如果text1[i - 1] 与 text2[j - 1]不相同,虽然不能直接递增一位,但是两边字符串都增加了一位,这带来了新的可能性,我们不能从 text1[0,i - 2] 与 text2[0,j - 2]得到结果,,那就看看text1[0, i - 2]与text2[0, j - 1]的最长公共子序列 和 text1[0, i - 1]与text2[0, j - 2]的最长公共子序列,取最大的。
其实也就相当于,如果我们不能从dp[i-][j-1]推出dp[i][j],那就从dp[i-1][j]和dp[j-1][i]中想办法,因为dp[i-1][j]和dp[j-1][i]时对称的,我们就选择其中的更大值,如下图:

代码如下:
if(text1[i-1] == text2[j-1]){
dp[i][j] = max(dp[i][j],dp[i-1][j-1]+1);
}
else{
dp[i][j] = max(dp[i-1][j],dp[i][j-1]);
}初始化:
同样需要第一排和第一列的初值,且初始化都为0
确定遍历顺序:
从前向后,从上到下,进行两层循环
完整代码:
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
if(text1.size() == 0 || text2.size() ==0)return 0;
vector<vector<int>> dp(text1.size()+1,vector<int>(text2.size()+1,0));
for(int i=1;i<=text1.size();i++)
for(int j =1;j<=text2.size();j++){
if(text1[i-1] == text2[j-1]){
dp[i][j] = max(dp[i][j],dp[i-1][j-1]+1);
}
else{
dp[i][j] = max(dp[i-1][j],dp[i][j-1]);
}
}
return dp[text1.size()][text2.size()];
}
};这样的dp定义方式有一个优势,结果不用遍历dp数组
3.2.4 不相交的线

本题就是寻找最长的公共子序列

代码如下:
class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
vector<vector<int>> dp(nums1.size()+1,vector<int>(nums2.size()+1,0));
for(int i = 1;i <= nums1.size();i++)
for(int j = 1 ;j <= nums2.size();j++){
if(nums1[i-1] == nums2[j-1]){
dp[i][j] = max(dp[i-1][j-1]+1,dp[i][j]);
}else{
dp[i][j] = max(dp[i][j-1],dp[i-1][j]);
}
}
return dp[nums1.size()][nums2.size()];
}
};3.2.5 判断子序列

此题和其他题的区别在于,返回值位bool,因此会很容易将dp数组的值定义为bool型,但这样初始化很复杂,时间复杂度有点高,初始化如下:

class Solution {
public:
bool isSubsequence(string s, string t) {
int n = s.size(),m = t.size();
vector<vector<bool>> dp(n+1,vector<bool>(m+1));
for(int i = 0;i <= n;i++){
dp[i][0] = false;
}
for(int j = 0;j <= m;j++){
dp[0][j] = true;
}
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(s[i-1] == t[j-1])
dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = dp[i][j-1];
}
}
}
return dp[n][m];
}
};因此我们选择dp[i][j]的含义为,有多少个匹配的字符,当匹配字符==s.size()时,就是true

完整代码如下:
class Solution {
public:
bool isSubsequence(string s, string t) {
int n = s.size(),m = t.size();
vector<vector<int>> dp(n+1,vector<int>(m+1,0));
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
if(s[i-1] == t[j-1])
dp[i][j] = dp[i-1][j-1]+1;
else{
dp[i][j] = dp[i][j-1];
}
}
}
return dp[n][m] == s.size() ? true : false;
}
};3.2.6 不同的子序列-双序列中只改变单序列的典例

(1)dp定义:
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
(2)转移方程:
此题与其他题不一样,因为是求有多少种删除方法,所以dp数组的更新不能是简单的+1
这里是求总的方法数,那当 s[i-1]==t[j-1]时:
我们不能只考虑将 s[i-1] 和 t[j-1] 同时留下,也即是dp[i][j] =dp[i-1][j-1] (最后一位相互抵消了)
还要考虑,如果前面也有一位 s[k] == s[i-1] (且相对位置满足t的要求),那么我们可以同时留下 s[k] 和 t[j-1] ,将 s[i-1] 删掉,因此dp[i][j] = dp[i-1][j](如果前面不存在s[k],那么此处为0,结果不变)
因为这两种情况时分开讨论的,不相交,因此当s[i-1]==t[j-1]时:
dp[i][j] = dp[i-1][j-1] + dp[i-1][j];而当s[i-1]!=t[j-1]时:
我们考虑将s[i-1]删除,因为不相等用不到
但是不能删除t[j-1],因为我们在求d[i][j],j对应的就是t[0,j-1],要是将t[j-1]去除,那就不能称为dp[i][j]了(
因为t是子串不能更改),所以不存在dp[i][j-1]和dp[i-1][j-1]两种情况
因此转移方程如下:
if(s[i-1] == t[j-1])
dp[i][j] = dp[i-1][j-1] + dp[i-1][j];
else{
dp[i][j] = dp[i-1][j];
}(3)初始化:
以样例为参考:
代码如下:
vector<vector<unsigned long long>> dp(n+1,vector<unsigned long long>(m+1,0));
for(int i = 0;i <= n;i++)
dp[i][0] = 1;(4)遍历顺序
两层for循环即可

完整代码如下:
class Solution {
public:
int numDistinct(string s, string t) {
int n = s.size(),m = t.size();
vector<vector<unsigned long long>> dp(n+1,vector<unsigned long long>(m+1,0));
for(int i = 0;i <= n;i++)
dp[i][0] = 1;
for(int i = 1;i <= n;i++)
for(int j = 1;j <= m;j++){
if(s[i-1] == t[j-1])
dp[i][j] = dp[i-1][j-1] + dp[i-1][j];
else{
dp[i][j] = dp[i-1][j];
}
// dp[i][j] = dp[i][j] % (1000000007);
}
return dp[n][m];
}
};3.2.7 两个字符串的删除操作

编辑距离的简化版
(1) dp定义:
不要连续就,定义dp[i][j]表示word1[0,i-1],word2[0,j-1]的最小步数
(2)转移方程
和编辑距离类似
word1[i-1] == word2[j-1]时,不删除,dp[i][j] = dp[i-1][j-1];
word1[i-1] != word2[j-1]时,在三种删除中选择最小的
if(word1[i-1] == word2[j-1])
dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = min(
dp[i-1][j-1]+2,
dp[i-1][j]+1,
dp[i][j-1]+1
);(3)初始化
根据样例进行如下初始化:

代码:
vector<vector<int>> dp(n+1,vector<int>(m+1));
for(int i = 0;i <= n;i++)dp[i][0] = i;
for(int i = 0;i <= m;i++)dp[0][i] = i;(4)遍历顺序

完整代码:
class Solution {
public:
int min(int a,int b,int c){
return std::min(std::min(a,b),c);
}
int minDistance(string word1, string word2){
int n = word1.size(),m = word2.size();
vector<vector<int>> dp(n+1,vector<int>(m+1));
for(int i = 0;i <= n;i++)dp[i][0] = i;
for(int i = 0;i <= m;i++)dp[0][i] = i;
for(int i = 1;i <= n;i++)
for(int j = 1 ;j <= m; j++){
if(word1[i-1] == word2[j-1])
dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = min(
dp[i-1][j-1]+2,
dp[i-1][j]+1,
dp[i][j-1]+1
);
}
}
return dp[n][m];
}
};3.2.8 两个字符串的最小ascii删除和
 和上一题及其类似,只是初始化和更新转移方程的形式有点区别,不多赘述
和上一题及其类似,只是初始化和更新转移方程的形式有点区别,不多赘述
代码如下:
class Solution {
public:
int min(int a,int b,int c){
return std::min(std::min(a,b),c);
}
int minimumDeleteSum(string s1, string s2){
int n = s1.size(),m = s2.size();
vector<vector<int>> dp(n+1,vector<int>(m+1));
for(int i = 0;i <= n;i++)
for(int j = 0;j < i;j++)
dp[i][0] += int(s1[j]);
for(int i = 0;i <= m;i++)
for(int j = 0;j < i;j++)
dp[0][i] += int(s2[j]);
for(int i = 1;i <= n; i++)
for(int j = 1 ;j <= m; j++){
if(s1[i-1] == s2[j-1])
dp[i][j] = dp[i-1][j-1];
else{
dp[i][j] = min(
dp[i-1][j-1]+int(s1[i-1])+int(s2[j-1]),
dp[i-1][j]+int(s1[i-1]),
dp[i][j-1]+int(s2[j-1])
);
}
}
return dp[n][m];
}
};3.3 回文子串和子序列
(1)回文子串要求连续,可以用双指针进行解答;
(2)但是回文子序列不连续,双指针失效,可以复制一份然后,将其倒转,使用双序列的方法进行解答.
3.3.1 回文子串

使用双指针解法,相比dp解法时间复杂度更低
代码如下,细节参考数组一章,双指针部分:
class Solution {
public:
int jud(string s,int l,int r){
int count = 0;
while(l >=0 && r <s.size()&&s[l]==s[r]){
l--;
r++;
count++;
}
return count;
}
int countSubstrings(string s){
int count = 0;
for(int i = 0;i < s.size();i++){
count += jud(s,i,i);
count += jud(s,i,i+1);
}
return count;
}
};3.3.2 最大回文子序列
 文章来源:https://www.toymoban.com/news/detail-759184.html
文章来源:https://www.toymoban.com/news/detail-759184.html
将s复制一份再倒转,然后对两个序列求最大公共子序列,代码如下:文章来源地址https://www.toymoban.com/news/detail-759184.html
//复制一份,倒转,求最大公共子序列
class Solution {
public:
int longestPalindromeSubseq(string s) {
string t = s;
reverse(s.begin(),s.end());
int n = s.size();
vector<vector<int>> dp(n+1,vector<int>(n+1,0));
for(int i = 1;i <= n;i++)
for(int j = 1;j <= n;j++){
if(s[i-1]==t[j-1])dp[i][j] = dp[i-1][j-1] + 1;
else{
dp[i][j] = max(max(dp[i-1][j],dp[i][j-1]),dp[i-1][j-1]);
}
}
return dp[n][n];
}
};到了这里,关于数据结构与算法-动态规划的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!