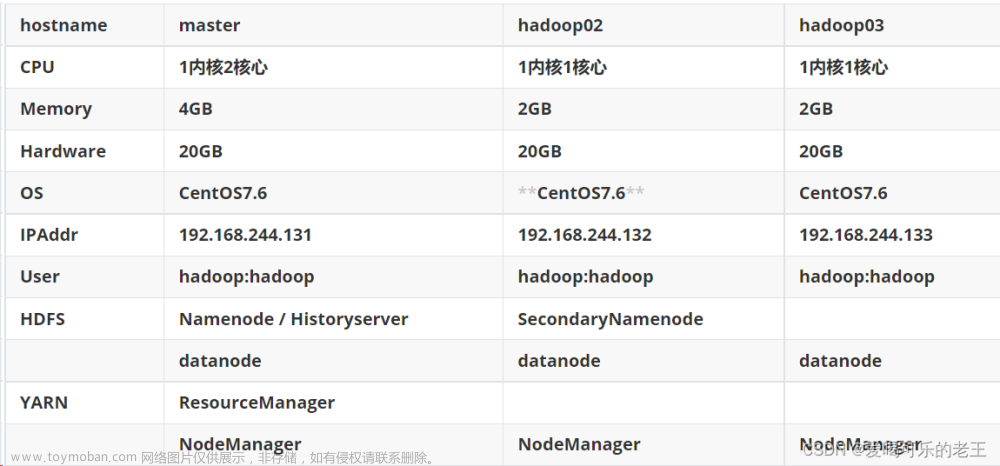
集群规划
| IP地址 | 主机名 | 集群身份 |
|---|---|---|
| 192.168.138.100 | hadoop00 | 主节点 |
| 192.168.138.101 | hadoop01 | 从节点 |
| 192.168.138.102 | hadoop02 | 从节点 |
Hadoop完全分布式环境搭建请移步传送门
先在主节点上进行安装和配置,随后分发到各个从节点上。
1. 安装zookeeper
1.1 解压zookeeper并添加环境变量
1)解压zookeeper到/usr/local文件夹下
tar -zxvf /usr/local
2)进入/usr/local文件夹将apache-zookeeper-3.8.0-bin改名为zookeeper
cd /usr/local
mv apache-zookeeper-3.8.0-bin/ zookeeper
3)添加环境变量
vim /etc/profile
# zookeeper环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
使配置立即生效
source /etc/profile
1.2 进行集群配置
1)创建文件夹
在$ZOOKEEPER_HOME/下创建data/zkData
mkdir data
mkdir data/zkData
2)进入$ZOOKEEPER_HOME/conf文件夹下
cd $ZOOKEEPER_HOME/conf
复制模版文件
cat zoo_sample.cfg >> zoo.cfg
修改zoo.cfg
…………
dataDir=/usr/local/zookeeper/data/zkData
…………
# 集群配置
server.1=hadoop00:2888:3888
server.2=hadoop01:2888:3888
server.3=hadoop02:2888:3888
3)在$ZOOKEEPER_HOME/data/zkData/目录下创建myid文件
cd $ZOOKEEPER_HOME/data/zkData
touch myid
myid文件内容为编号,与zoo.cfg中集群配置的编号对应,如果是server.1(即hadoop00)的myid内容为1,依次类推。
echo 1 >> myid
scp /usr/local/zookeeper/ hadoop01:/usr/local/ # 不要忘记改myid
scp /usr/local/zookeeper/ hadoop02:/usr/local/
scp /etc/profile hadoop01:/etc/profile # 不要忘记执行 source /etc/profile 使文件立即生效
scp /etc/profile hadoop02:/etc/profile
4)启动zookeeper
分别在三台虚拟机上启动zookeeper
zkServer.sh start # 运行
zkServer.sh stop # 停止
zkServer.sh status # 查看状态,需要启动所有结点的zookeeper才显示enabled

2. 安装Hbase
2.1 解压Hbase并添加环境变量
1)解压hbase并重命名
tar -zxvf hbase-2.5.3-bin.tar.gz -C /usr/local/
cd /usr/local
mv hbase-2.5.3-bin.tar.gz hbase
2)添加环境变量
vim /etc/profile
…………
# hbase环境变量
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
使修改立即生效:
source /etc/profile
2.2 进行集群配置
1)修改hbase-env.sh文件
进入/usr/local/hbase/conf目录下
cd /usr/local/hbase/conf
修改hbase-env.sh(文件内容前插入)
…………
# JDK路径
export JAVA_HOME=/usr/local/jdk
# 设置使用外置的zookeeper
export HBASE_MANAGES_ZK=false
2)修改hbase-site.xml
<configuration>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 指定HDFS实例地址 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop00:9000/hbase</value>
</property>
<!-- 启用分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper集群节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop00,hadoop01,hadoop02</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/data/zkData</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase/tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
3)复制hadoop的core-site.xml和hdfs-site.xml到hbase的conf目录下:
cp /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hbase/conf/
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/
4)在/usr/local/hbase/conf/文件夹下的regionservers文件添加集群的所有主机的主机名
vim regionservers
# 将文件内容中删除后添加
hadoop00
hadoop01
hadoop02
5)分发和运行
将hbse和环境变量分发到另外两台从节点:
scp -r /usr/local/hbase/ hadoop01:/usr/local/hbase
scp -r /usr/local/hbase/ hadoop02:/usr/local/hbase
scp -r /etc/profile hadoop01:/etc/profile
scp -r /etc/profile hadoop02:/etc/profile
运行hbase
注:hbase启动之前,一定要先启动zookeeper,且集群所有的节点都要启动!!!否则使用不了hbase即使守护进程都存在
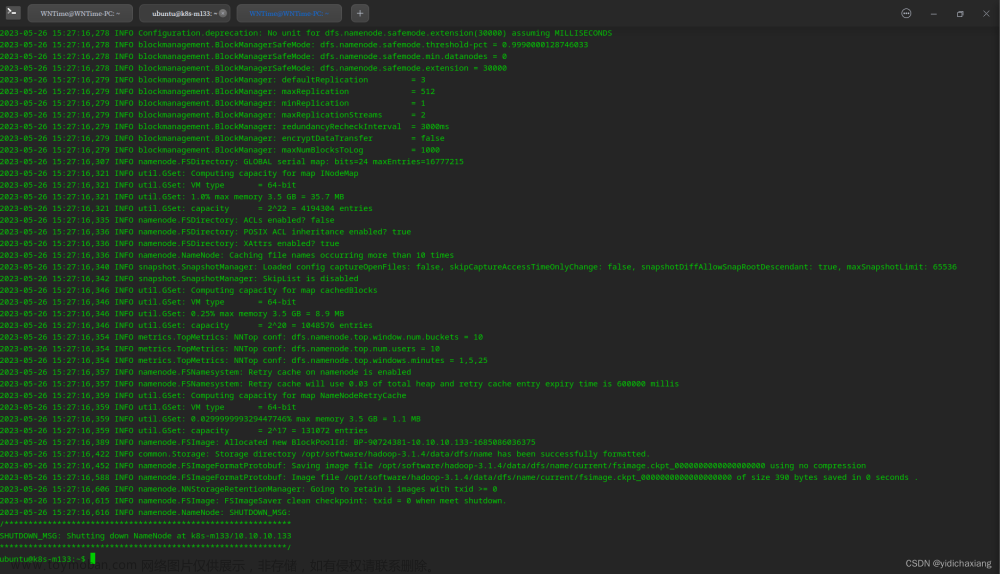
检查zookeeper的状态
在主节点上执行:
zkServer.sh status
出现下图为正常:

start-hbase.sh # 运行
stop-hbase.sh # 停止
进入hbase shell,查看其状态是否正常。
hbase shell
status # 进入shell后执行
如下图则正常:文章来源:https://www.toymoban.com/news/detail-759433.html
 文章来源地址https://www.toymoban.com/news/detail-759433.html
文章来源地址https://www.toymoban.com/news/detail-759433.html
到了这里,关于Hadoop3.x完全分布式环境搭建Zookeeper和Hbase的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!