一、保证RabbitMQ服务高可用
1.RabbitMQ如何保证消息安全
之前通过单机环境搭建起来的RabbitMQ服务有一个致命的问题,那就是服务不稳定的问题。如果只是单
机RabbitMQ的服务崩溃了,那还好,大不了重启下服务就是了。但是如果是服务器的磁盘出问题了,那问
题就大了。因为消息都是存储在Queue里的,Queue坏了,意味着消息就丢失了。这在生产环境上肯定是无
法接受的。而RabbitMQ的设计重点就是要保护消息的安全性。
所以RabbitMQ在设计之处其实就采用了集群模式来保护消息的安全。基础的思想就是给每个Queue提供
几个备份。当某一个服务的Queue坏了,至少还可以从其他Queue中获取服务。
其实对于RabbitMQ,一个节点的服务也是作为一个集群来处理的,在web控制台的admin-> cluster 中可
以看到集群的名字,并且可以在页面上修改。
那么RabbitMQ是怎么考虑数据安全这回事的呢?实际上,RabbitMQ考虑了两种集群模式:
默认的普通集群模式:
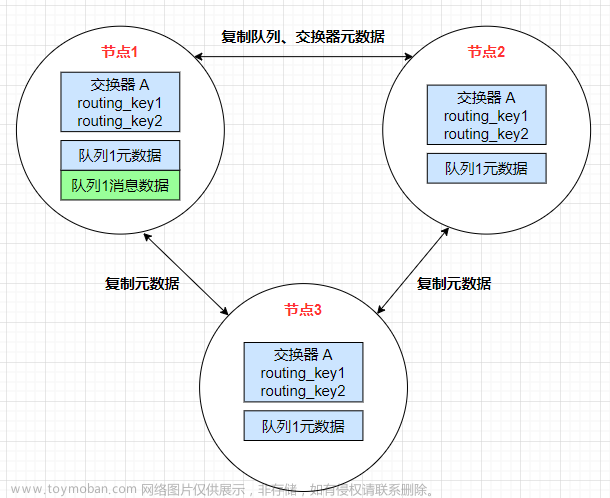
这种模式使用Erlang语言天生具备的集群方式搭建。这种集群模式下,集群的各个节点之间只会有相同
的元数据,即队列结构,而消息不会进行冗余,只存在一个节点中。消费时,如果消费的不是存有数据
的节点, RabbitMQ会临时在节点之间进行数据传输,将消息从存有数据的节点传输到消费的节点。
很显然,这种集群模式的消息可靠性不是很高。因为如果其中有个节点服务宕机了,那这个节点上的数
据就无法消费了,需要等到这个节点服务恢复后才能消费,而这时,消费者端已经消费过的消息就有可
能给不了服务端正确应答,服务起来后,就会再次消费这些消息,造成这部分消息重复消费。 另外,
如果消息没有做持久化,重启就消息就会丢失。
并且,这种集群模式也不支持高可用,即当某一个节点服务挂了后,需要手动重启服务,才能保证这一
部分消息能正常消费。
所以这种集群模式只适合一些对消息安全性不是很高的场景。而在使用这种模式时,消费者应该尽量的
连接上每一个节点,减少消息在集群中的传输。
镜像模式:
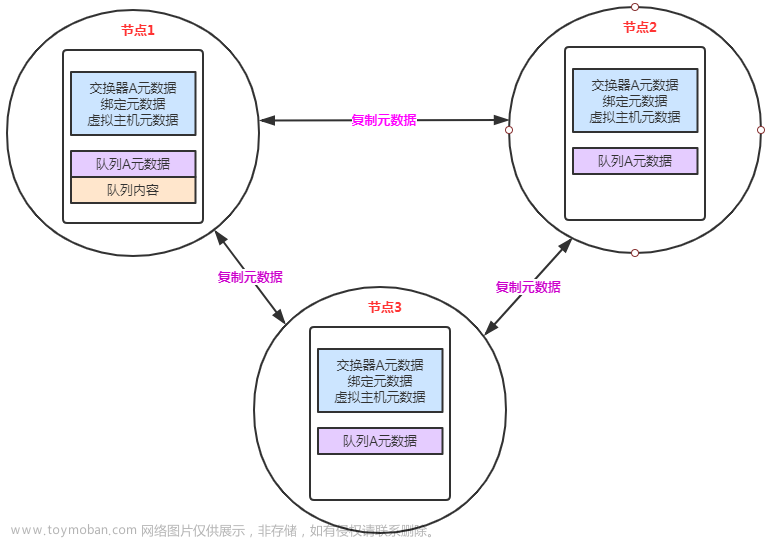
这种模式是在普通集群模式基础上的一种增强方案,这也就是RabbitMQ的官方HA高可用方案。需要在
搭建了普通集群之后再补充搭建。其本质区别在于,这种模式会在镜像节点中间主动进行消息同步,而
不是在客户端拉取消息时临时同步。
并且在集群内部有一个算法会选举产生master和slave,当一个master挂了后,也会自动选出一个来。
从而给整个集群提供高可用能力。
这种模式的消息可靠性更高,因为每个节点上都存着全量的消息。而他的弊端也是明显的,集群内部的
网络带宽会被这种同步通讯大量的消耗,进而降低整个集群的性能。这种模式下,队列数量最好不要过
多。
2、搭建普通集群
接下来,我们准备三台服务器,在/etc/hosts文件中分配配置机器别名为worker1,worker2,worker3。
然后三台服务器上分别搭建起RabbitMQ的服务,然后开始搭建集群。
1:需要同步集群节点中的cookie。
默认会在 /var/lib/rabbitmq/目录下生成一个.erlang.cookie。 里面有一个字符串。我们要做的就是保证集群
中三个节点的这个cookie字符串一致。
我们实验中将worker1和worker3加入到worker2的RabbitMQ集群中,所以将worker2的.erlang.cookie
文件分发到worker1和worker3。
同步文件时注意一下文件的权限,如果文件不可读,集群启动会有问题。简单粗暴的,可以使用
chmod 777 .erlang.cookie指令给这个文件配置最大权限。
2:将worker1的服务加入到worker2的集群中。
首先需要保证worker1上的rabbitmq服务是正常启动的。
3、搭建镜像集群
这样就完成了普通集群的搭建。 再此基础上,可以继续搭建镜像集群。
通常在生产环境中,为了减少RabbitMQ集群之间的数据传输,在配置镜像策略时,会针对固定的虚拟主机
virtual host来配置。
RabbitMQ中的vritual host可以类比为MySQL中的库,针对每个虚拟主机,可以配置不同的权限、策
略等。并且不同虚拟主机之间的数据是相互隔离的。
我们首先创建一个/mirror的虚拟主机,然后再添加给对应的镜像策略。
通常镜像模式的集群已经足够满足大部分的生产场景了。虽然他对系统资源消耗比较高,但是在生产环境
中,系统的资源都是会做预留的,所以正常的使用是没有问题的。但是在做业务集成时,还是需要注意队列
数量不宜过多,并且尽量不要让RabbitMQ产生大量的消息堆积。
RabbitMQ如何保证消息不丢失
1、RabbitMQ消息零丢失方案:
1》生产者保证消息正确发送到RibbitMQ
对于单个数据,可以使用生产者确认机制。通过多次确认的方式,保证生产者的消息能够正确的发送到
RabbitMQ中。
RabbitMQ的生产者确认机制分为同步确认和异步确认。同步确认主要是通过在生产者端使用
Channel.waitForConfirmsOrDie()指定一个等待确认的完成时间。异步确认机制则是通过
channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2)在生产者端注入两个回调确认
函数。第一个函数是在生产者消息发送成功时调用,第二个函数则是生产者消息发送失败时调用。两个函数
需要通过sequenceNumber自行完成消息的前后对应。sequenceNumber的生成方式需要通过channel的序
列获取。int sequenceNumber = channel.getNextPublishSeqNo();
当前版本的RabbitMQ,可以在Producer中添加一个ReturnListener,监听那些成功发到Exchange,但是
却没有路由到Queue的消息。如果不想将这些消息返回给Producer,就可以在Exchange中,也可以声明一
个alternate-exchange参数,将这些无法正常路由的消息转发到指定的备份Exchange上。
如果发送批量消息,在RabbitMQ中,另外还有一种手动事务的方式,可以保证消息正确发送。
手动事务机制主要有几个关键的方法: channel.txSelect() 开启事务; channel.txCommit() 提交事务;
channel.txRollback() 回滚事务; 用这几个方法来进行事务管理。但是这种方式需要手动控制事务逻辑,并
且手动事务会对channel产生阻塞,造成吞吐量下降
2》 RabbitMQ消息存盘不丢消息
这个在RabbitMQ中比较好处理,对于Classic经典队列,直接将队列声明成为持久化队列即可。而新增的
Quorum队列和Stream队列,都是明显的持久化队列,能更好的保证服务端消息不会丢失。
3》 RabbitMQ 主从消息同步时不丢消息
这涉及到RabbitMQ的集群架构。首先他的普通集群模式,消息是分散存储的,不会主动进行消息同步
了,是有可能丢失消息的。而镜像模式集群,数据会主动在集群各个节点当中同步,这时丢失消息的概率不
会太高。
另外,启用Federation联邦机制,给包含重要消息的队列建立一个远端备份,也是一个不错的选择。文章来源:https://www.toymoban.com/news/detail-759711.html
4》 RabbitMQ消费者不丢失消息
RabbitMQ在消费消息时可以指定是自动应答,还是手动应答。如果是自动应答模式,消费者会在完成业
务处理后自动进行应答,而如果消费者的业务逻辑抛出异常,RabbitMQ会将消息进行重试,这样是不会丢
失消息的,但是有可能会造成消息一直重复消费。
将RabbitMQ的应答模式设定为手动应答可以提高消息消费的可靠性。文章来源地址https://www.toymoban.com/news/detail-759711.html
到了这里,关于【RabbitMQ高可用集群架构】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!