Elliptic数据集
Elliptic数据集是从真实的比特币交易网络中获得的,这是真实的比特币交易数据。数据集被构建为一个图,由表示比特币交易的节点和表示交易流的边组成。椭圆数据集是比特币交易图的子图,由203769个节点和234355条表示节点之间交易的边组成。节点分为三类,即合法、非法和未知。合法类别包括交易所、矿工、钱包提供商、金融服务提供商等。非法类别包括欺诈、恶意软件、恐怖组织、洗钱、勒索软件、庞氏骗局等。不属于前两类的节点被标记为未知。
节点和边缘
该图由 203,769 个节点和 234,355 条边组成。2%(4,545)的节点被标记为1类(非法)。21%(42,019)被标记为2类(合法)。其余交易没有合法与非法的标签。
特征
每个节点与166个特征相关联,并且由于隐私问题,数据集不能提供所有特征的准确描述。每个节点都有一个关联的时间步长,代表交易广播到比特币网络的时间度量。时间步长从 1 到 49,间隔均匀,间隔约为两周。每个时间步都包含一个连接的交易组件,这些交易在不到三个小时内出现在区块链上;没有连接不同时间步长的边。前 94 个特征表示有关交易的本地信息 - 包括上述时间步长、输入/输出数量、交易费用、输出量和汇总数字,例如输入/输出接收(花费)的平均 BTC 以及与输入/输出相关的平均传入(传出)交易数量。其余 72 个特征是聚合特征,使用从中心节点向后/向前一跳的交易信息获得 - 给出相同信息数据(输入/输出数量、交易费用等)的相邻交易的最大、最小、标准差和相关系数。
综述
Akoglu L, Tong H, Koutra D. Graph based anomaly detection and description: a survey[J]. Data mining and knowledge discovery, 2015, 29: 626-688.
Ma X, Wu J, Xue S, et al. A comprehensive survey on graph anomaly detection with deep learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2021.
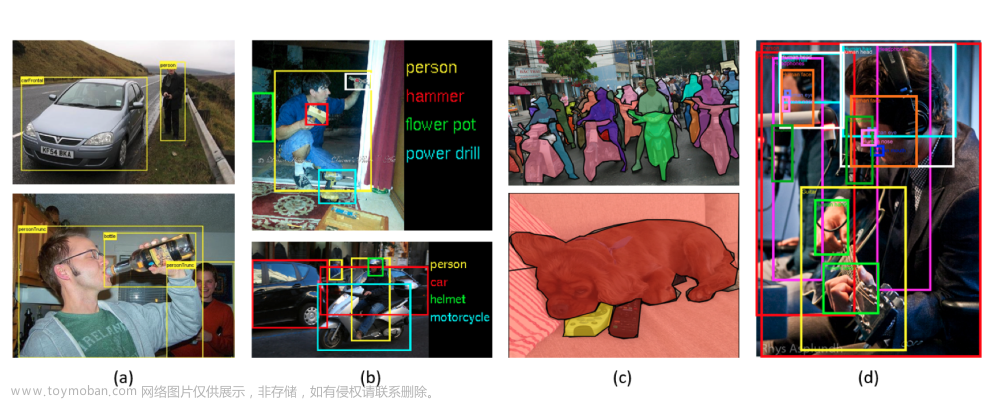
异常检测是一种数据挖掘过程,旨在识别偏离数据集中大多数的异常模式。为了检测异常,传统技术通常将真实世界的对象表示为特征向量(例如,社交媒体中的新闻表示为单词袋,网页中的图像表示为颜色直方图),然后检测向量空间中的外围数据点,如下图所示。尽管这些技术在列表数据格式下定位偏离数据点方面表现出了强大的能力,但它们本质上放弃了对象之间的复杂关系。
事实上,许多物体之间有着丰富的关系,可以为异常检测提供有价值的补充信息。为了表示结构信息,图(其中节点/顶点表示真实对象,边表示它们的关系)已广泛用于一系列应用领域,包括社交活动、电子商务、生物学、学术和通信。如下图,在给定在线社交网络的情况下,图异常检测旨在识别异常节点(即恶意用户)、异常边缘(即异常关系)和异常子图(即恶意的用户组)。数据对象不能总是被独立地视为位于多维空间中的点。相反,它们可能表现出相互依赖性,这应该在异常检测过程中考虑。事实上,物理学、生物学、社会科学和信息系统等广泛学科的数据实例本质上是相互关联的。图形提供了一种强大的机制,可以有效地捕捉相互依赖的数据对象之间的这些长期相关性。
静态图的异常检测
主要任务是在给定整个图结构的情况下发现异常网络实体(例如,节点、边、子图)
1.平面图——仅由这些节点中的节点和边组成,即图结构
1.1基于结构的模式——利用图结构来提取以图为中心的特征
- 基于特征的方法
这组方法使用图表示来提取以图为中心的结构特征,这些特征有时与从附加信息源提取的其他特征一起使用,用于在构建的特征空间中检测异常值。从本质上讲,这些方法将图异常检测问题转化为众所周知的异常检测问题。以图为中心的特征:可以使用给定的图结构来计算与节点、二元、三元、自我网、社区以及全局图结构相关的各种度量;节点级特征包括(入/出)度、中心性度量,如特征向量、贴近度和介数中心性、局部聚类系数、半径、度分类性,以及最近的角色。二元特征包括互易性、边缘介数、共同邻居的数量,以及其他几个局部网络重叠度量。节点组级特征可以被列为紧凑性度量,如密度、模块性和电导。
- 基于近似的方法——使用图结构来量化图中节点的接近度以识别关联
这组技术利用图结构来测量图中对象的接近度(或接近度)。这些方法捕获了这些对象之间的简单自相关,其中近距离对象被认为可能属于同一类(例如,恶意/良性或感染/健康)。一种广泛使用的图接近度度量是个性化PageRank(PPR),它也基于随机游走,但将重新启动扩展到特定节点。另一个量化图中两个节点接近度的图接近度度量是SimRank,它根据图对象与其他对象的关系计算图对象出现的结构上下文的相似性。
1.2.基于社区的模式
用于图异常检测的集群或基于社区的方法依赖于在图中找到密集连接的“近处”节点组以及具有跨社区连接的点节点和/或边。事实上,在这种设置下,异常的定义可以被认为是找到不直接属于某个特定社区的“桥梁”节点/边缘。
2.属性图——节点和/或边具有与其相关联的特征的图
对于某些类型的数据,可以有更丰富的图表示,其中节点和边显示(非唯一)属性。此类图的示例包括以用户兴趣为属性的社交网络、以时间、地点和金额为属性的交易网络、以访问港口的货物运输、财务信息、运输货物的类型为属性,4这类属性图的异常检测方法利用图的结构和属性的一致性来发现模式和点异常。
2.1基于结构的方法——利用频繁的子结构和子图模式来发现这些模式中的变形
基于结构的方法主要旨在识别图中结构罕见的子结构,在给定图中寻找不寻常子结构的问题,以及在给定子图集中寻找不寻常的子图的问题,其中节点和边包含(非唯一)属性。解决这些问题的主要见解是寻找很少出现的结构,这些结构与所谓的“最佳子结构”大致相反。检测异常子结构(P1)的主要思想是定义一个度量,该度量与为最佳子结构定义的基于MDL的度量成反比,并通过该新度量对子结构进行排序。类似地,寻找不寻常子图(P2)的主要思想是定义一个度量,惩罚那些包含很少常见(即最好)子结构的子图,使其更加反常。
2.2.基于社区的方法——异常值与同一社区中的其他异常值不具有相同的特征
旨在识别图中的节点,通常被称为社区异常值,其属性值与他们所属特定社区的其他成员存在显著差异,基于社区所组成的节点的链接和属性相似性来分析社区。基于图的社区异常值检测与三个密切相关的问题区分开来;即,只考虑节点属性的全局异常值检测,只考虑链路的结构异常值检测,以及仅考虑直接邻居的属性值的局部异常值检测。
2.3.基于关系学习的方法
由基于网络的集体分类算法组成,其主要思想是利用对象之间的关系将它们分配到类中,其中类的数量通常为两个:异常和正常。与旨在量化图对象之间的自相关性的基于邻近度的方法不同,这些算法通常更复杂,因此可以建模和利用图对象之间更复杂的相关性。
分类是指根据观察到的属性为数据实例分配类标签,或很快为其添加标签的问题。当有代表性的标记数据可用时,异常检测可以被公式化为分类问题。关系分类的基本假设是,对象之间的关系携带了对对象进行分类的重要信息,例如两个链接的网页。在许多情况下,对象之间存在简单的自相关,其中链接的对象可能具有相同的标签(例如,垃圾邮件页面链接到其他垃圾邮件页面,感染者链接到其他感染者)。在其他情况下,可能会表现出更复杂的相关性
动态图的异常检测

给定一系列(平面图或属性图),找到(i)与变化或事件相对应的时间戳(ii)对变化(属性)贡献最大的图的前k个节点、边或部分。
根据应用领域的不同,算法的要求也不同,但最常见的期望属性是:
–可伸缩性。根据每天生成的图形的大小和体积的指示,理想情况下,算法应该是输入图形大小的线性或次线性。在动态设置中,一个额外的、期望的特性是,算法应该在输入图的更新大小上是线性的。
–对结构和上下文变化的敏感性。异常检测方法应该能够辨别被比较的输入图之间的结构差异(例如,缺失/新边、缺失/新节点、边权重的变化以及图的其他属性的更改,例如节点或边的标签。
–变化重要性可感知。算法应该对变化的类型和程度是合理的。与不太重要的结构相比,“重要”节点、边或其他图形属性的变化应该会导致更大的异常分数。
1.基于特征的
关键思想是类似的图可能共享某些属性,例如度分布、直径、特征值。在动态图的演变中检测异常时间戳的一般方法可以总结为以下步骤:(i)从输入图的每个快照中提取一个“好的摘要”。(ii)使用距离或等效的相似性函数来比较连续的图形。(iii)当距离大于手动或自动定义的阈值时(或者相反,相似性小于阈值),将相应的快照定性为异常。每种提出的算法的新颖之处在于它构建的“图摘要”、使用的距离/相似性函数,以及它定义和选择阈值以将实例标记为异常的方式。
2.基于分解
通过对时间演化图进行矩阵或张量分解,并解释适当选择的特征向量、特征值或奇异值来检测时间异常。根据图的表示,这些方法可以分为两类:矩阵与张量。
3.基于社区或聚类
主要思想是,不是监测整个网络中的变化,而是随着时间的推移监测图社区或集群,并在其中任何一个发生结构或上下文变化时报告事件。
4.基于窗口
与时间窗口绑定的方法,以便发现输入图序列中的异常模式和行为。从本质上讲,许多先前的实例用于对“正常”行为进行建模,并将传入的图与那些进行比较,以将其定性为正常或异常。
图注意力网络-Graph attention networks (GAT)
图注意力网络,一种基于图结构数据的新型神经网络架构,利用隐藏的自我注意层来解决之前基于图卷积或其近似的方法的不足。通过堆叠层,节点能够参与到邻居的特征,可以(隐式地)为邻域中的不同节点指定不同的权值,而不需要任何代价高昂的矩阵操作(如反转),也不需要预先知道图的结构。通过这种方法,该模型克服了基于频谱的故神经网络的几个关键挑战,并使得模型适用于归纳和推理问题。
(1)从GNN,GCN到GAT
- GNN学习的是邻居节点聚合到中心的方式,传统的GNN对于邻居节点采用求和/求平均的方式,各个邻居的权重相等为1
- GCN进行了改造邻居聚合方式为邻接矩阵做对称归一化,也是类似求平均,但是它考虑到了节点的度大小,度越大权重往小了修正,是一种避免单节点链接巨量节点导致计算失真的调整方式,仅仅通过度+规则对权重做了修改,而没有考虑到因为节点的影响大小去调整权重的大小。
- GAT认为
(1)不同邻居对中心节点的影响是不一样的,且它想通过注意力自动地去学习这个权重参数,从而提升表征能力
(2)GAT使用邻居和中心节点各自的特征属性来确定权重,中心节点的所有邻居的权重相加等于1
(2)注意力机制
在注意力机制中Source代表需要处理的信息,Query代表某种条件或者先验信息,Attention Value是通过先验信息和Attention机制从Source中提取的信息,Source中的信息通过key-value对的形式表达出来,可以将key类比为信息的摘要,value类比为信息的全部内容。注意力机制的定义如下
从公式来看,注意力机制就是先计算出前提条件和每个要接受的信息的摘要部分的相关程度,以相关程度为权重再学习要接受的每个全部信息,最后每条信息加权求和得到结果
(3)GNN中的注意力机制文章来源:https://www.toymoban.com/news/detail-760055.html
类比Key-Value注意力机制,图结构中中心节点就是Query,所有邻居节点的信息就是Source,Attention Value就是中心节点经过聚合之后的特征向量,Key和Value相同,就是邻居节点的特征向量。目标就是针对中心节点(Query)学习邻居节点(Source)的权重,再加权求和汇总到中心节点上形成新的特征向量表达(Attention Value)。 文章来源地址https://www.toymoban.com/news/detail-760055.html
文章来源地址https://www.toymoban.com/news/detail-760055.html
到了这里,关于图异常检测初接触的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!