一、Storm集群构建
编写storm 与 zookeeper的yml文件

storm yml文件的编写
具体如下:
version: '2'
services:
zookeeper1:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk1.cloud
environment:
- SERVER_ID=1
- ADDITIONAL_ZOOKEEPER_1=server.1=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper2:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk2.cloud
environment:
- SERVER_ID=2
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper3:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk3.cloud
environment:
- SERVER_ID=3
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=0.0.0.0:2888:3888
ui:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: ui -c nimbus.host=nimbus
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
restart: always
container_name: ui
ports:
- 8080:8080
depends_on:
- nimbus
nimbus:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: nimbus -c nimbus.host=nimbus
restart: always
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
container_name: nimbus
ports:
- 6627:6627
supervisor:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: supervisor -c nimbus.host=nimbus -c supervisor.slots.ports=[6700,6701,6702,6703]
restart: always
environment:
- affinity:role!=supervisor
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
depends_on:
- nimbus
networks:
default:
external:
name: zk-net
拉取Storm搭建需要的镜像,这里我选择镜像版本为 zookeeper:3.4.8 storm:1.0.0
键入命令:
docker pull zookeeper:3.4.8 docker pull storm:1.0.0

storm镜像 获取
使用docker-compose 构建集群
在power shell中执行以下命令:
docker-compose -f storm.yml up -d

docker-compose 构建集群
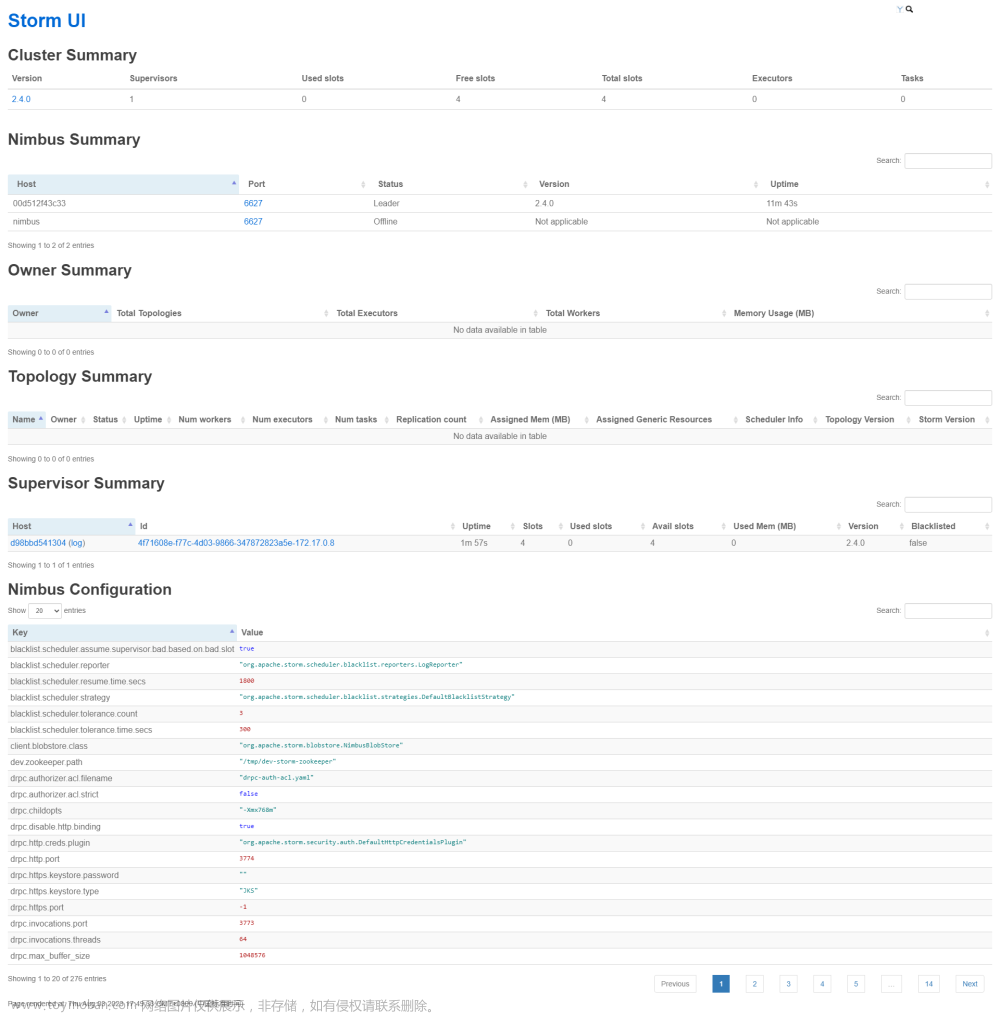
在浏览器中打开localhost:8080 可以看到storm集群的详细情况

storm UI 展示
二、Storm统计任务
统计股票交易情况交易量和交易总金额 (数据文件存储在csv文件中)
编写DataSourceSpout类

DataSourceSpout类
编写bolt类

编写topology类

需要注意的是 Storm Java API 下有本地模型和远端模式
在本地模式下的调试不依赖于集群环境,可以进行简单的调试
如果需要使用生产模式,则需要将
1、 编写和自身业务相关的spout和bolt类,并将其打包成一个jar包
2、将上述的jar包放到客户端代码能读到的任何位置,
3、使用如下方式定义一个拓扑(Topology)

演示结果:
本地模式下的调试:
正在执行:

根据24小时

根据股票种类
生产模式:

向集群提交topology
三、核心计算bolt的代码
1.统计不同类型的股票交易量和交易总金额:
package bolt; import java.io.IOException; import java.util.HashMap; import java.util.Map; import java.util.Set; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; @SuppressWarnings("serial") public class TypeCountBolt extends BaseRichBolt { OutputCollector collector; Map<String,Integer> map = new HashMap<String, Integer>(); Map<String,Float> map2 = new HashMap<String, Float>(); public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } public void execute(Tuple input) { String line = input.getStringByField("line"); String[] data = line.split(","); Integer count = map.get(data[2]); Float total_amount = map2.get(data[2]); if(count==null){ count = 0; } if(total_amount==null){ total_amount = 0.0f; } count++; total_amount+=Float.parseFloat(data[3]) * Integer.parseInt(data[4]); map.put(data[2],count); map2.put(data[2],total_amount); System.out.println("~~~~~~~~~~~~~~~~~~~~~~~"); Set<Map.Entry<String,Integer>> entrySet = map.entrySet(); for(Map.Entry<String,Integer> entry :entrySet){ System.out.println("交易量:"); System.out.println(entry); } System.out.println(); Set<Map.Entry<String,Float>> entrySet2 = map2.entrySet(); for(Map.Entry<String,Float> entry :entrySet2){ System.out.println("交易总金额:"); System.out.println(entry); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
2. 统计不同每个小时的交易量和交易总金额文章来源:https://www.toymoban.com/news/detail-760110.html
package bolt; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.HashMap; import java.util.Map; import java.util.Set; public class TimeCountBolt extends BaseRichBolt { OutputCollector collector; Map<Integer,Integer> map = new HashMap<Integer, Integer>(); Map<Integer,Float> map2 = new HashMap<Integer, Float>(); public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } public void execute(Tuple input) { String line = input.getStringByField("line"); String[] data = line.split(","); Date date = new Date(); SimpleDateFormat dateFormat= new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); try { date = dateFormat.parse(data[0]); } catch (ParseException e) { e.printStackTrace(); } Integer count = map.get(date.getHours()); Float total_amount = map2.get(date.getHours()); if(count==null){ count = 0; } if(total_amount==null){ total_amount = 0.0f; } count++; total_amount+=Float.parseFloat(data[3]) * Integer.parseInt(data[4]); map.put(date.getHours(),count); map2.put(date.getHours(),total_amount); System.out.println("~~~~~~~~~~~~~~~~~~~~~~~"); Set<Map.Entry<Integer,Integer>> entrySet = map.entrySet(); for(Map.Entry<Integer,Integer> entry :entrySet){ System.out.println("交易量:"); System.out.println(entry); } System.out.println(); Set<Map.Entry<Integer,Float>> entrySet2 = map2.entrySet(); for(Map.Entry<Integer,Float> entry :entrySet2){ System.out.println("交易总金额:"); System.out.println(entry); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
文章来源地址https://www.toymoban.com/news/detail-760110.html
到了这里,关于Storm 集群的搭建及其Java编程进行简单统计计算的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!