此文章来源于项目官方公众号:“AirtestProject”
版权声明:允许转载,但转载必须保留原链接;请勿用作商业或者非法用途
1. 前言
最近看到群里很多小伙伴都在用Airtest-Selenium做一些web自动化的尝试,正好趁此机会,我们也出几个关于web自动化的实操小课,仅供大家参考~
今天跟大家分享的是一个非常简单的爬取网页信息的小练习,在百度找到新榜网页,搜索关键词“自动化”,爬取前5名的公众号名称。
2. 需求分析和准备
整体的需求大致可以分为以下步骤:
- 打开chrome浏览器
- 打开百度网页
- 搜索“新榜官网”
- 点击“找达人”按钮
- 搜索关键词“自动化”
- 爬取排名前5的公众号名称
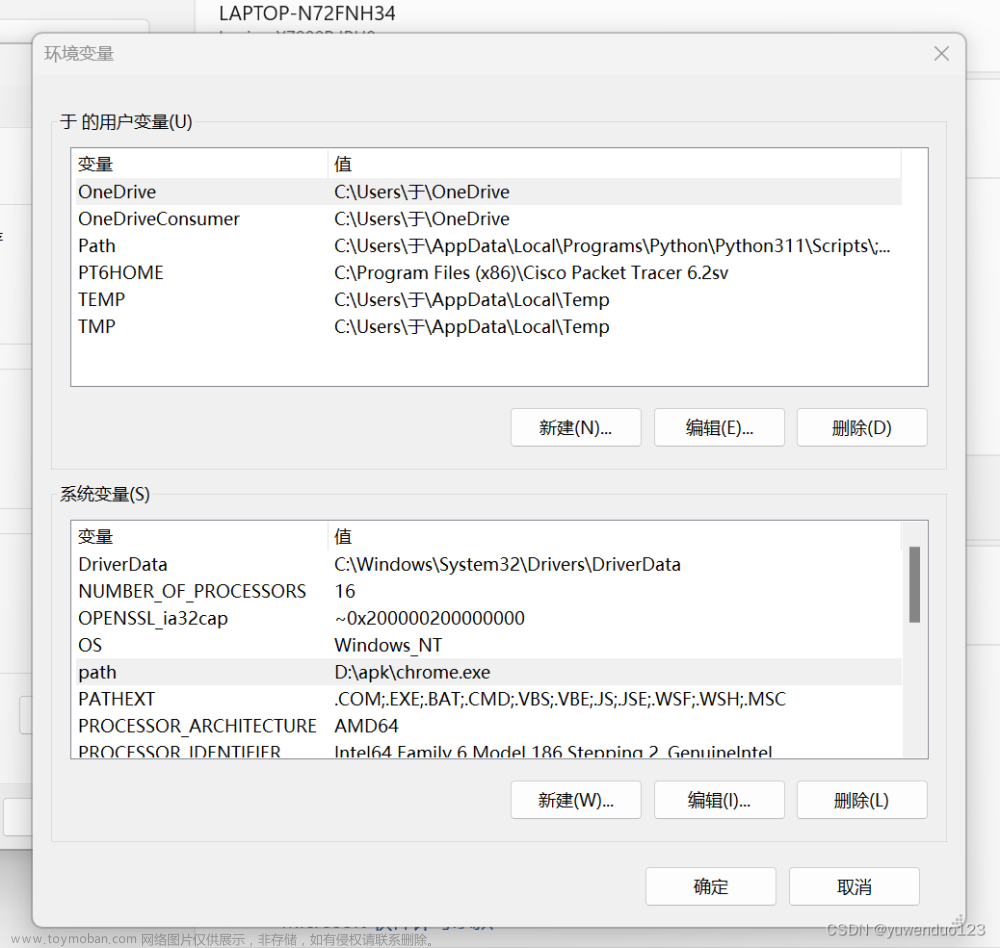
在写脚本之前,我们需要准备好社区版AirtestIDE,设置好chrome.exe和对应的driver;并且确保我们的chrome浏览器版本不是太高以及selenium是4.0以下即可(这些兼容问题我们都会在后续的版本修复)。
3. 脚本实现
3.1 完整示例代码
接下来就可以着手写脚本啦,关于web自动化脚本,我们可以借助IDE的selenium Window ,方便我们录制控件信息和快速使用常用接口:

完整的参考代码如下:
# -*- encoding=utf8 -*-
__author__ = "AirtestProject"
from airtest.core.api import *
from airtest_selenium.proxy import WebChrome
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
"""
任务描述:打开chrome浏览器,打开百度搜索新榜,进入新榜搜索关键词“自动化”,爬取自动化综合排名前10的公众号名称
https://www.newrank.cn/search/gongzhonghao/%E8%87%AA%E5%8A%A8%E5%8C%96
"""
def start_selenium():
# 创建一个实例,代码运行到这里,会打开一个chrome浏览器
driver = WebChrome()
driver.implicitly_wait(20)
driver.get("https://www.baidu.com/")
# 输入搜索关键词并提交搜索
search_box = driver.find_element_by_name('wd')
search_box.send_keys('新榜官网')
search_box.submit()
# 使用XPath查找文本为 "上海新榜信息技术股份" 的元素并点击
try:
element = driver.find_element_by_xpath("//div[@id='content_left']/div[@id='1']/div[@class='c-container']/div[1]/h3[@class='c-title t t tts-title']/a")
except Exception as e:
element = driver.find_element_by_xpath('//*/text()[normalize-space()="上海新榜信息技术股份"]/parent::*')
element.click()
# 获取所有窗口句柄
window_handles = driver.window_handles
# 切换到新打开的窗口
driver.switch_to.window(window_handles[1])
# 获取新页面的链接
new_page_url = driver.current_url
# 打印新页面的链接
print(new_page_url)
driver.get(new_page_url)
# # 在主内容内部查找 "找达人" 按钮并点击
search_box = driver.find_element_by_xpath('//button[@class="ant-btn ant-btn-primary ant-btn-lg index_searchBtn__c3q_1"]//a')
print(search_box.text)
# 获取a标签的URL
url = search_box.get_attribute('href')
# 打印URL
print(url)
driver.get(url) # 请求搜索链接-跳转
# 输入搜索关键词并提交搜索
search_box = driver.find_element_by_id('rc_select_0')
# 模拟发送Backspace键
search_box.send_keys(Keys.BACKSPACE) # 清空内容
search_box.send_keys(Keys.BACKSPACE)
search_box.send_keys('自动化')
# 模拟发送Enter键
search_box.send_keys(Keys.ENTER)
sleep(5)
list_date = driver.find_elements(By.XPATH, "//div[@class='ant-spin-container']//li")
for item in list_date:
name_str = item.find_element_by_class_name("index_name__Fk83i")
print(name_str.text)
if __name__ == "__main__":
start_selenium()
3.2 重要知识点
1)创建实例并打开浏览器
driver = WebChrome()
2)打开网页
driver.get("https://www.baidu.com/")
3)元素定位
driver.find_element_by_xpath('//button[@class="ant-btn ant-btn-primary ant-btn-lg index_searchBtn__c3q_1"]//a')
更多定位方式可以在官方教程学习:https://python-selenium-zh.readthedocs.io/zh_CN/latest/ 。
4)模拟按键输入
search_box = driver.find_element_by_name('wd')
search_box.send_keys('新榜官网')
5)模拟回车
search_box = driver.find_element_by_name('wd')
search_box.submit()
6)模拟键盘事件
search_box = driver.find_element_by_id('rc_select_0')
# 模拟发送Backspace键
search_box.send_keys(Keys.BACKSPACE)
4. 注意事项与小结
4.1 相关教程
- 如何使用AirtestIDE生产web自动化脚本
- 如何设置chromedriver以及一些常见的web脚本问题
- 为什么AirtestIDE无法检索web控件?
4.2 参考脚本的有效性
请同学们不要过多依赖于我们给出的参考脚本,通常情况下,网页的控件信息可能会随着前端的改动而更新,所以我们的教程并不是永久有效的。
更多的是参考整体脚本的知识点,查漏补缺,让自己在小实践中对web自动化的熟练程度更高。也非常欢迎热心同学给我们投稿~
AirtestIDE下载:airtest.netease.com/
Airtest 教程官网:airtest.doc.io.netease.com/
搭建企业私有云服务:airlab.163.com/b2b文章来源:https://www.toymoban.com/news/detail-760351.html
官方答疑 Q 群:117973773文章来源地址https://www.toymoban.com/news/detail-760351.html
到了这里,关于Airtest-Selenium实操小课①:爬取新榜数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!