文章来源:https://www.toymoban.com/news/detail-760361.html
文章来源:https://www.toymoban.com/news/detail-760361.html
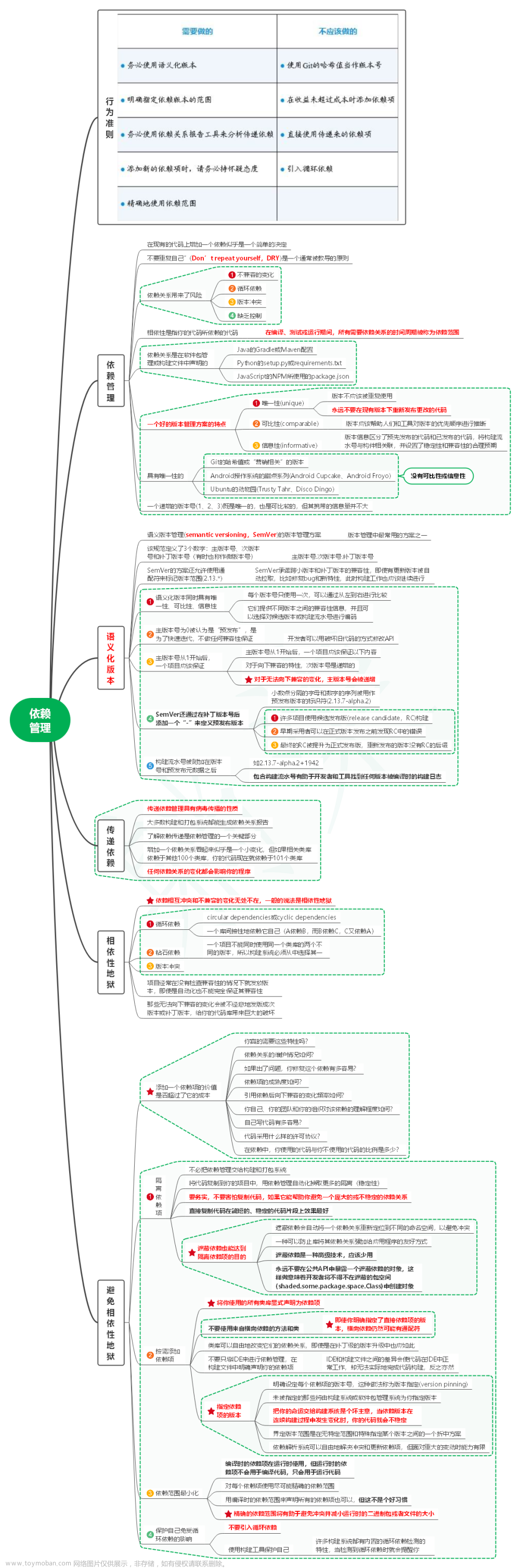
1. 行为准则
 文章来源地址https://www.toymoban.com/news/detail-760361.html
文章来源地址https://www.toymoban.com/news/detail-760361.html
2. On-Call工程师
2.1. On-Call工程师是应对计划外工作的第一道防线,无论是生产环境问题还是临时支持请求
2.2. 将深度工作与运维工作分开,可以让团队中的大多数人专注于开发任务
2.3. On-Call工程师只需专注于不可预知的运维难题和支持任务
3. On-Call的工作方式
3.1. On-Call的开发人员根据时间表进行轮换
3.1.1. 每名合格的开发人员都会参与到轮换工作中
3.2. On-Call人员的大部分时间用来处理临时性的支持请求
3.2.1. bug报告、关于他们团队的软件如何运行以及使用的问题
3.3. 大概每名On-Call人员最终都会遇到一起运维事故(生产软件的关键问题)
3.3.1. 事故是由自动监控系统发出的警报或由支持工程师观察到问题并报告给值班人员的
3.3.2. On-Call的开发人员必须对事故分流、缓解症状和最终解决
3.4. 所有的On-Call轮换的工作都应该以交接开始和结束
4. On-Call技能包
4.1. 随时响应
4.1.1. 较大的公司有“跟随太阳”的On-Call轮换机制,随着时间的推移,轮换到不同时区的开发人员
4.1.2. “随时响应”并不意味着立即放下你正在做的事情来解决最新的问题
4.1.3. 对于许多请求,完全可以先承认你已经收到了询问,并回答你应该在什么时候能看一下这个问题
4.2. 保持专注
4.3. 确定工作优先级
4.3.1. 首先处理优先级最高的任务
4.3.2. 随着任务的完成或受阻,你可以依次从最高优先级到最低优先级展开工作
4.3.3. 如果你无法判断一个请求的紧急程度,请询问该请求的影响是什么
4.3.4. P1:严重影响(critical impact)——服务在生产环境中无法使用
4.3.5. P2:高影响(high impact)——服务的使用受到严重损害
4.3.6. P3:中等影响(medium impact)——服务的使用部分受损
4.3.7. P4:低影响(low impact)——服务完全可用
4.3.8. 服务水平指标(SLI)如错误率、请求延迟和每秒请求数,是了解一个应用程序是否健康的最简单的方法之一
4.3.9. 服务水平目标(service level objective,SLO)为健康的应用程序行为定义了SLI的目标
4.3.10. 如果错误率是某个应用程序的SLI,SLO可能是请求错误率低于0.001%的
4.3.11. 服务水平协议(service level agreement,SLA)是关于越过SLO范围时将会发生什么的协议
4.3.12. 了解你的应用程序的SLI、SLO和SLA,SLI将为你指出最重要的指标,SLO和SLA将帮助你确定事故的优先次序
4.4. 清晰的沟通
4.4.1. 用简洁的句子进行沟通
4.4.2. 回应请求要迅速
4.4.2.1. 回应不一定代表解决方案
4.4.3. 定期发布状态更新
4.4.3.1. 每次更新时,提供一个新的时间预估
4.5. 跟踪你的工作
4.5.1. 记录下你在工作中所做的事情
4.5.2. 聊天是一种很好的沟通方式,但聊天记录在以后很难被阅读,所以要确保在任务票或文档中总结一切
4.5.3. 关闭已解决的问题,这样悬而未决的任务票就不会在On-Call的看板上留下痕迹,也不会使On-Call支持的系统指标出现偏差
4.5.3.1. 如果请求者没有回应,就说你将在24小时内因缺乏回应而关闭该任务票,然后真的这样做
4.5.4. 始终在你的笔记中包含时间戳
5. 事故处理
5.1. 事故处理是On-Call人员最重要的职责
5.1.1. 第一个目标是减轻问题的影响并恢复服务
5.1.2. 第二个目标是捕捉信息,以便以后分析问题是如何发生以及为什么发生的
5.1.3. 第三个目标是确定事故的原因,证明它是罪魁祸首,并解决根本问题
5.2. 提供支持
5.2.1. 大多数请求是bug报告、关于业务逻辑的问题,或关于如何使用你的软件的技术问题
5.2.2. 支持请求遵循一个相当标准的流程
5.3. 5个阶段
5.3.1. 分流(triage)
5.3.1.1. 工程师必须找到问题,确定其严重性,并确定谁能修复它
5.3.1.2. 确认问题并了解其影响,以便对其进行适当的优先排序
5.3.1.3. 分流不是证明你能自己解决问题的时候,最宝贵的是争取时间
5.3.1.4. 分流也不是排除故障的时候
5.3.1.4.1. 把故障排除留给提出应急方案和解决方案的阶段
5.3.2. 协同(coordination)
5.3.2.1. 团队(以及潜在的用户)必须得到这个问题的通知
5.3.2.2. 大型事故设有专门的“作战室”来帮助沟通,“作战室”是用于协调事故响应的虚拟或物理空间
5.3.2.3. 所有相关方都加入作战室,以协同响应
5.3.2.4. 即使你是一个人在工作,也要交流你的工作
5.3.2.4.1. 有人可能会稍后加入并发现你记录的日志大有所益,详细的记录将有助于事后重建时间线
5.3.3. 应急方案(mitigation)
5.3.3.1. 工程师必须尽快让事情稳定下来
5.3.3.2. 缓解并不是长期的修复,你只是在试图“止血”
5.3.3.3. 应急方案的阶段目标是降低问题的影响
5.3.3.3.1. 应急方案并不是要彻底地解决这个问题,而是要降低其严重性
5.3.3.4. 修复一个问题可能需要很多时间,而应急方案通常可以很快完成
5.3.3.5. 事故的应急方案通常是将软件版本回滚到“最后已知良好”的版本,或将流量从问题上转移开
5.3.3.6. 迅速写下你发现的任何不足,可以使你在排除故障时处理得更游刃有余,在后续行动的阶段新建任务票以解决这些不足
5.3.4. 解决方案(resolution)
5.3.4.1. 在问题得到缓解后,工程师有一些时间来喘口气、深入思考,并为解决问题而努力
5.3.4.2. 一旦完成了应急方案,事故就不再是紧急事故了
5.3.4.3. 使用科学方法来排除技术问题的故障
5.3.4.4. 测试并不是治疗
5.3.5. 后续行动(follow-up)
5.3.5.1. 对事故的根本原因:为什么会发生,进行调查
5.3.5.2. 目的是从事故中学习,防止它再次发生
5.3.5.3. 要写一份事后总结的文档,并进行评审,同时开启新任务以防止其再次发生
5.3.5.3.1. 描述了事故的前因后果、故障、影响、检测、响应、恢复、时间表、根本原因、经验教训和所需的纠正措施
5.3.5.3.2. 任何回顾总结文档的关键部分是根本原因分析(root-cause analysis,RCA)
5.3.5.4. 根本原因分析是利用5个“Why”进行的
5.3.5.4.1. “5W”只是口口相传的经验,大多数问题要经过5次反复才能找到根本原因
5.3.5.4.2. 根本原因分析是一个流行但具有误导性的术语
5.3.5.4.2.1. 事故很少是由单一的问题引起的
5.3.5.4.2.2. 在实践中,这5个“Why”可能会引向许多不同的原因
5.3.5.4.2.3. 只要把一切都记录下来
5.3.5.5. 良好的事后总结会还将“解决问题”与评审会议分开
5.3.5.6. 事后总结会结束后,后续任务必须被完成
5.3.5.7. 旧的回顾总结文档是很好的学习资料
6. 不要逞英雄
6.1. 跳入“救火”模式成为一种条件反射
6.2. 依赖“救火队员”是不健康的
6.3. 长时间和高风险将导致倦怠。“救火”工程师也会在编程或设计工作中“步履蹒跚”,因为他们不断地被打断
6.4. “救火队员”的英雄主义也会导致那种修复严重的潜在问题的工作被置于次要地位,因为“救火队员”总在旁边修修补补
到了这里,关于读程序员的README笔记12_On-Call的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!