📝前言
本小节,我们学习结构的内存对齐,理解其对齐规则,内存对齐包含结构体的计算,使用宏offsetof计算偏移量,为什么要存在内存对齐?最后了解结构体的传参文章干货满满!学习起来吧😃!
🌠 结构体内存对齐
结构体内存对齐指的是结构体中各成员变量在内存中的存储位置按照一定规则对齐。
既然是按照一定规则,那得首先了解它的对齐规则:
- 结构体的第一个成员对齐到和结构体起始位置偏移量为
0的地址处。 - 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值。
- VS 中默认的值为 8
-
linux中gcc没有默认对齐数,对齐数就是成员自身的大小
- 结构体总大小为最大对齐数(结构体中的每一个成员都有一个对齐数,所有对齐数中的)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
- 来代码理解:
struct S1
{
char c1;
char c2;
int i;
};
struct S2
{
char c1;
int i;
char c2;
};
int main()
{
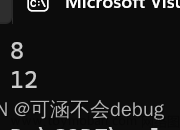
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}
代码运行:
分析:
首先结构体S1的成员有三个,根据对齐规则:结构体的第一个成员对齐到结构体变量起始位置偏移量为0的地址处-—>C1放在偏移量为0的地址处,接下来第二个C2就从第2个规则按对齐数进行放置,C2的字节数char类型,大小为1,VS的默认对齐数为8,对齐数取的是默认对齐数和成员变量字节大小的较小值,1<8,取1为对齐数,然后偏移量为1的位置放1,此时再看第三个变量i的字节大小为4,4<8,对齐数为4,当放在偏移量为2时,2不是4的整数倍,跳过,3也不是,跳过,而当偏移量为4时刚好是4的整数1倍(4*1=4),然后占据为4个字节空间,从偏移量0到最后偏移量的空间就是结构体的总大小,为8,此时还没有结束,要验证,根据第三条规则结构体的总大小为最大对齐数的整数倍,最大对齐数为4(4>1>1),而结构刚才计算出来是8刚好是4整数倍(4*2)当这些都符合了,结构体的大小就是8了。
一个例子你可能想是不是碰巧,那么第二个例子:
结构体S2中有三个成员,C1大小为一,第一个成员放在偏移量为0处,第二个成员i大小为4,偏移量1,2,3都不是4的整数倍,然后这些空间都跳过不放数据,(注:他开辟了空间,但他此时不用,你可能会想:这不浪费吗?文章我们慢慢解释)然后偏移量为4时为整数倍,从偏移量4开始放i直到7,第三个元素C2大小为1,1的整数倍任何数的整数倍,可以直接放,当放在偏移量8处时,全部成员都放完了,我们还要对他进行验证是否为整数倍。S2最大对齐数是4,偏移量9,10都不对,当偏移量为11,从0到11刚好为12,为4的倍数(4*3=12)。所以S2总大小为12!
🌉内存对齐包含结构体的计算
struct S3
{
double d;
char c;
int i;
};
int main()
{
printf("%zd\n", sizeof(struct S3));
return 0;
}
运行结果:16
分析:

首先第一个成员为d,放在偏移量为0处,double类型,大小为8,位置范围为0 ~ 7,第二个成员C ,类型为char,大小为1,1<8,对齐数为1,1可以直接放,占据8位置处,第三个成员i,大小为4,4<8,对齐数是4,偏移量9,10,11都不是4的倍数,12开始占据4个空间到15,范围0 ~ 15总大小为16。S3结构体是三个成员(8>4>1)大小最大是double大小为8,此时总结构体大小16刚好为8的2倍,符合条件。
- [] 包含
S3的结构体
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{
printf("%zd\n", sizeof(struct S4));
return 0;
}
运行结果:32
第一个成员C1对应到偏移量为0处,大小为1,s3为结构体,s3的大小为16,根据第四条规则【如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。】,也就是说结构体s3最大对齐数为double的8,用8对齐到S4中整数倍,1,2,3,4,5,6,7都不是8的整数倍,跳过,当偏移量为8时为对齐数8的整数倍时,然后结构体整体大小为16,占据范围为8 ~ 23,接下来就是第三个元素d,大小为8,偏移量24就是8的整数倍,占据了24 ~ 31,所有成员都完成了,偏移量范围在0 ~ 31,总大小就是32。答案就是32.看到这里的你,给自己鼓个掌,继续加油。

🌠宏offsetof计算偏移量
宏offsetof可以用来计算结构体成员相对于结构体起始位置的偏移量。
宏offsetof原型:
offsetof(type, member)
type是结构体类型
member是结构体中的成员。
注意:使用offsetof宏计算结构体成员偏移量时,需要包含stddef.h头文件
# define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <string.h>
#include <stddef.h>
struct S1
{
char c1;
char c2;
int i;
};
struct S2
{
char c1;
int i;
char c2;
};
struct S3
{
double d;
char c;
int i;
};
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{
struct S1 s1 = {0};//8
struct S2 s2 = { 0 };//12
printf("结构体大小:\n");
printf("S1=%zd\n", sizeof(struct S1));//8
printf("S2=%zd\n", sizeof(struct S2));//12
printf("S3=%zd\n", sizeof(struct S3));//16
printf("S4=%zd\n", sizeof(struct S4));//32
printf("\n");
printf("结构体S1成员的偏移量:\n");
printf("c1=%zd\n", offsetof(struct S1, c1));//0
printf("c2=%zd\n", offsetof(struct S1, c2));//1
printf(" i=%zd\n", offsetof(struct S1, i));//8
printf("\n");
printf("结构体S2成员的偏移量:\n");
printf("c1=%zd\n", offsetof(struct S2, c1));//0
printf(" i=%zd\n", offsetof(struct S2, i));//4
printf("c2=%zd\n", offsetof(struct S2, c2));//8
printf("\n");
printf("结构体S4成员的偏移量:\n");
printf("c1=%zd\n", offsetof(struct S4, c1));//0
printf("s3=%zd\n", offsetof(struct S4, s3));//8
printf("d=%zd\n", offsetof(struct S4, d));//24
return 0;
}
运行+图对比:
🌉为什么存在内存对⻬?
-
平台原因 (移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 -
性能原因:
数据结构(尤其是栈)应该尽可能地在⾃然边界上对⻬。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。
假设⼀个处理器总是从内存中取
8个字节,则地址必须是8的倍数。如果数据没有对齐,CPU需要额外的时间来处理非对齐的内存访问,这会降低性能。

总结一句话来说:
结构体的内存对⻬是拿空间来换取时间的做法。
在设计结构体时,既要满足内存对齐要求,又要考虑节省空间,可以采取以下方法:
- 尽量将较小类型如
char、short等成员放在结构体开始位置。这可以减少由对齐产生的内存浪费。
例如前面的S1和S2就很典型:
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
char c1;
char c2;
int i;
};
阿森把宝图解:
- 修改默认对⻬数
#pragma这个预处理指令,可以改变编译器的默认对⻬数。#pragma原型:
#pragma pack(push, 1) // 将结构体对齐数设置为1字节
struct S1
{
char a;
int b;
};
#pragma pack(pop)// 恢复之前的对齐数
-
pack(push, 1)表示将当前对齐数压入栈,并设置新的对齐数为1字节 -
pack(pop)表示从栈中弹出之前的对齐数,恢复默认对齐数
可以直接指定对齐数:
#pragma pack(1)
struct S1
{ // 成员对齐数为1字节
char a;
int b;
};
#pragma pack() // 恢复默认对齐数
例子:
#pragma pack(1)
struct S1
{
char c1;
char c2;
int i;
};
#pragma pack()
int main()
{
printf("%d\n", sizeof(struct S1));
return 0;
}
输出:
图解对比:
🌠 结构体传参
- 按值传递(传结构体)
函数形参声明为结构体,实参传递结构体变量。此时在函数内对形参的修改不会影响实参。
struct St
{
int x;
};
void func(struct St st)
{
st.x = 10;
}
int main()
{
struct St s = { 0 };
func(s);//传结构体
printf("%d\n", s.x);
}
输出:
- 按地址传递
函数形参定义为结构体指针,实参传递结构体变量的地址。函数内对形参所指结构体的修改会影响实参。
struct St
{
int x;
};
void func(struct St* p)
{
p->x = 10;
}
int main() {
struct St s = { 0 };
func(&s);
printf("%d\n", s.x);
}
输出:
- 传结构体指针
实参直接传结构体指针:
struct St
{
int x;
};
void func(struct St* st)
{
st->x = 10;
}
int main()
{
struct St s;
struct St* p = &s;
func(p);
printf("%d\n", s.x);
}
输出:10
分析:
传值也就是把整个结构体传过去,我们知道形参是是实参的一份临时拷贝,需要再创建特别大的空间来存储结构体。

无论是传结构体指针还是传结构体地址,本质上都是传地址,但是传地址,只需要创建一个小的空间来存储地址。

选择传地址比较好一些。
原因:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递⼀个结构体对象的时候,结构体过⼤,参数压栈的的系统开销⽐较⼤,所以会导致性能的下降。
总结:
结构体传参的时候,要传结构体的地址。
🚩总结
这次阿森和你一起学习结构体的 结构体内存对齐,内存对齐包含结构体的计算,使用宏offsetof计算偏移量,为什么存在内存对⻬? 结构体传参的本质,阿森将下一节和你一起学习结构体实现位段。文章来源:https://www.toymoban.com/news/detail-760545.html
感谢你的收看,如果文章有错误,可以指出,我不胜感激,让我们一起学习交流,如果文章可以给你一个小小帮助,可以给博主点一个小小的赞😘 文章来源地址https://www.toymoban.com/news/detail-760545.html
文章来源地址https://www.toymoban.com/news/detail-760545.html
到了这里,关于【C语言】自定义类型:结构体深入解析(二)结构体内存对齐&&宏offsetof计算偏移量&&结构体传参的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!