Scala安装配置
一、Scala简介
1. 概述
Scala(斯嘎拉)这个名字来源于"Scalable Language(可伸缩的语言)",它是一门基于JVM的多范式编程语言,通俗的说:Scala是一种运行在JVM上的函数式的面向对象语言。之所以这样命名,是因为它的设计目标是:随着用户的需求一起成长。Scala可被广泛应用于各种编程任务, 从编写小型的脚本到构建巨型系统,它都能胜任。正因如此, Scala得以提供一些出众的特性, 例如: 它集成了面向对象编程和面向函数式编程的各种特性, 以及更高层的并发模型。
scala是运行在 JVM 上的多范式编程语言,同时支持面向对象和面向函数编程早期,scala刚出现的时候,并没有怎么引起重视,随着Spark和Kafka这样基于scala的大数据框架的兴起,scala逐步进入大数据开发者的眼帘。scala的主要优势是它的表达性。
1.1 为什么要使用scala?
- 开发大数据应用程序(Spark程序、Flink程序)
- 表达能力强,一行代码抵得上Java多行,开发速度快
- 兼容Java,可以访问庞大的Java类库,例如:操作mysql、redis、freemarker、activemq等等
- Spark就是使用Scala编写的。因此为了更好的学习Spark, 需要掌握Scala这门语言。
- Spark的兴起,带动Scala语言的发展!
1.2 Scala 发展历史
联邦理工学院的马丁·奥德斯基(Martin Odersky)于2001年开始设计Scala。
马丁·奥德斯基是编译器及编程的狂热爱好者,长时间的编程之后,希望发明一种语言,能够让写程序这样的基础工作变得高效,简单。所以当接触到JAVA语言后,对JAVA这门便携式,运行在网络,且存在垃圾回收的语言产生了极大的兴趣,所以决定将函数式编程语言的特点融合到JAVA中,由此发明了两种语言(Pizza & Scala)。
Pizza和Scala极大地推动了Java编程语言的发展。
⚫ JDK5.0 的泛型、增 强for循 环、自动类型转换等,都是从Pizza引入的新特性。
⚫ JDK8.0 的类型推断、Lambda表达式就是从Scala引入的特性。
JDK5.0和JDK8.0的编辑器就是马丁·奥德斯基写的,因此马丁·奥德斯基一个人的战斗力抵得上一个Java开发团队。
Scala之父
Scala之父是: Martin·Odersky(马丁·奥德斯基), 他是EPFL(瑞士领先的技术大学)编程研究组的教授. 也是Typesafe公司(现已更名为: Lightbend公司)的联合创始人. 他在整个职业生涯中一直不断追求着一个目标:让写程序这样一个基础工作变得高效、简单、且令人愉悦. 他曾经就职于IBM研究院、耶鲁大学、卡尔斯鲁厄大学以及南澳大利亚大学. 在此之前,他在瑞士苏黎世联邦理工学院追随Pascal语言创始人Niklaus Wirth(1984年图灵奖获得者)学习,并于1989年获得博士学位。

1.3 Scala 和 Java 关系
一般来说,学 Scala 的人,都会 Java,而 Scala 是基于 Java 的,因此我们需要将 Scala和 Java 以及 JVM 之间的关系搞清楚,否则学习 Scala 你会蒙圈。
下面是 Scala和Java及JVM关系图:

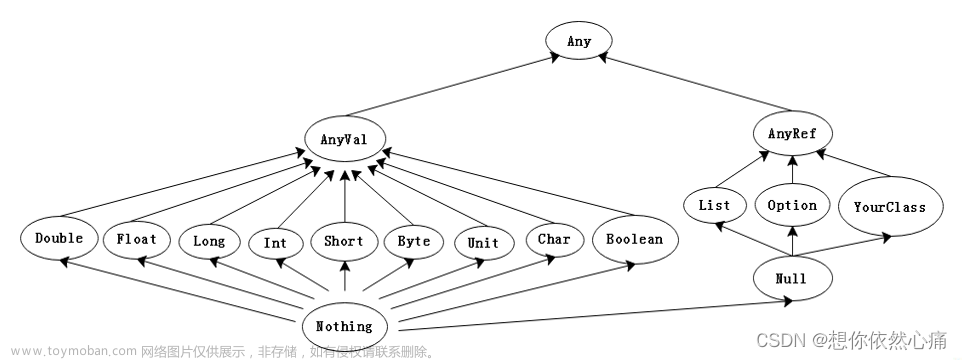
1.4 Scala 语言特点
Scala是一门以Java虚拟机(JVM)为运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言(静态语言需要提前编译的如:Java、c、c++等,动态语言如:js)。
1)Scala是一门多范式的编程语言,Scala支持面向对象和函数式编程。(多范式,就是多种编程方法的意思。有面向过程、面向对象、泛型、函数式四种程序设计方法。)
2)Scala源代码(.scala)会被编译成Java字节码(.class),然后运行于JVM之上,并可以调用现有的Java类库,实现两种语言的无缝对接。
3)Scala单作为一门语言来看,非常的简洁高效。
4)Scala在设计时,马丁·奥德斯基是参考了Java的设计思想,可以说Scala是源于Java,同时马丁·奥德斯基也加入了自己的思想,将函数式编程语言的特点融合到JAVA中, 因此,对于学习过Java的同学,只要在学习Scala的过程中,搞清楚Scala和Java相同点和不同点,就可以快速的掌握Scala这门语言。
2. Scala对比Java
下面通过两个案例,分别使用 java 和 scala 实现的代码数量
案例一
定义三个实体类(用户、订单、商品)
Java代码
/**
* 用户实体类
*/
public class User {
private String name;
private List<Order> orders;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Order> getOrders() {
return orders;
}
public void setOrders(List<Order> orders) {
this.orders = orders;
}
}
/**
* 订单实体类
*/
public class Order {
private int id;
private List<Product> products;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public List<Product> getProducts() {
return products;
}
public void setProducts(List<Product> products) {
this.products = products;
}
}
/**
* 商品实体类
*/
public class Product {
private int id;
private String category;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
}
scala代码
case class User(var name:String, var orders:List[Order]) // 用户实体类
case class Order(var id:Int, var products:List[Product]) // 订单实体类
case class Product(var id:Int, var category:String) // 商品实体类
案例二
有一个字符串(数字)列表,我们想将该列表中所有的字符串转换为整数。
Java代码
// 创建一个Integer类型的列表
List<Integer> ints = new ArrayList<Integer>();
for (String s : list) {
ints.add(Integer.parseInt(s));
}
scala代码
val ints = list.map(s => s.toInt)
二、开发环境安装
1. 使用版本
- Intellij IDEA 2022.2.3
- JDK 17.0.5
- scala-sdk-2.11.12
2. Scala执行流程
Java程序编译执行流程

Scala程序编译执行流程

scala程序运行需要依赖于Java类库,必须要有Java运行环境,scala才能正确执行根据
上述流程图,要编译运行scala程序,需要
- jdk(jvm)
- scala编译器(scala SDK)
接下来,需要依次安装以下内容:
3. 安装JDK
安装JDK 1.8 64位版本,并配置好环境变量。
这里可以参考文章:JDK的使用
4. 安装scala SDK
Scala官网

4.1 下载Scala

4.2 安装Scala
双击鼠标点击安装:

点击下一步:

同意协议:

选择安装路径:
最好安装在不存在中文字符,不含空格的目录下。

点击安装:


安装完成:

5. 测试是否安装成功

这样就安装成功了。
6. 安装IDEA scala插件
IDEA默认是不支持scala程序开发的,所以需要在IDEA中安装scala插件, 让它来支持scala语言。
进入 Settings :

点击安装插件:

7. 新建项目
新建一个项目:

初次新建时,是没有Scala的sdk的,需要点击后面的Create按钮,把scala的安装路径作为SDK。

这样一个项目就创建好了:

三、scala解释器
后续我们会使用scala解释器来学习scala基本语法,scala解释器像Linux命令一样,执行一条代码,马上就可以让我们看到执行结果,用来测试比较方便。
1. 启动scala解释器
要启动scala解释器,只需要以下几步:
- 按住 windows键 + r
- 输入 scala 即可


2. 执行scala代码
在scala的命令提示窗口中输入 println(“hello, world”) ,回车执行

3. 退出解释器
在scala命令提示窗口中执行 :quit ,即可退出解释器
四、HelloWorld 案例
1. 创建 IDEA 项目工程
1)打开 IDEA->点击左侧的 Flie->选择 New->选择 Project…

2)创建一个 Maven 工程,并点击 next
注意:工程存储路径一定不要有中文和空格。

3)默认下,Maven 不支持 Scala 的开发,需要引入 Scala 框架。
在 scala 项目上,点击右键-> Add Framework Support… ->选择 Scala->点击 OK


注意:如果是第一次引入框架,Use libary 看不到,需要选择你的 Scala 安装目录,然后工具就会自动识别,就会显示 user libary。
4)创建项目的源文件目录
右键点击 main 目录->New->点击 Diretory -> 写个名字(比如 scala)。


右键点击 scala 目录->Mark Directory as->选择 Sources root,观察文件夹颜色发生变化。


5)在 scala 包下,创建包 com.atguigu.chapter01 包名和 Hello 类名
右键点击 scala 目录->New->Package->输入 cn.edu.hgu.chapter01->点击 OK。


右键点击 cn.edu.hgu.chapter01->New->Scala Class->选择 Object->Name 项输入Hello。


6)编写输出 Hello Scala 案例
在类中中输入 main,然后回车可以快速生成 main 方法;


在 main 方法中输入 println(“hello scala”)

运行后,观察控制台打印输出:

说明:Java 中部分代码也是可以在 Scala 中运行。
2. 代码中语法的简单说明
package cn.edu.hgu.chapter01
object Hello {
def main(args: Array[String]): Unit = {
println("hello scala")
System.out.println("hello scala")
}
}
定义方法:
def 方法名(参数名:参数类型):返回值类型={方法体}
scala中没有public关键字,如不声明访问权限,那么就是公共的。
scala是一个完全面向对象的语言,没有静态语法,所以没有static关键字,为了能调用静态语法(模仿静态语法),采用伴生对象单例的方式调用方法。
Scala完全面向对象,故Scala去掉了Java中非面向对象的元素,如static关键字,void类型
1)static Scala无static关键字,由object实现类似静态方法的功能(类名.方法名)。
2)void 对于无返回值的函数,Scala定义其返回值类型为Unit类
五、关联 Scala 源码
在使用 Scala 过程中,为了搞清楚 Scala 底层的机制,需要查看源码,下面看看如何查看 Scala 的源码包。
例如查看 Array 源码。按住 ctrl 键->点击 Array->右上角出现 Attach Soures…


六、官方编程指南
目前最新版本为3系列,我们使用的是 2 系列版本。
https://docs.scala-lang.org/overviews/scala-book/prelude-taste-of-scala.html
参考文章:
Scala基础教程–01–scala简介及安装使用
安装scala出现"此时不应有 \scala\bin\scala.bat"问题解决方案
【尚硅谷大数据技术之Scala入门到精通教程(小白快速上手scala)】文章来源:https://www.toymoban.com/news/detail-761152.html
在线查看文章来源地址https://www.toymoban.com/news/detail-761152.html
到了这里,关于Scala安装配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!