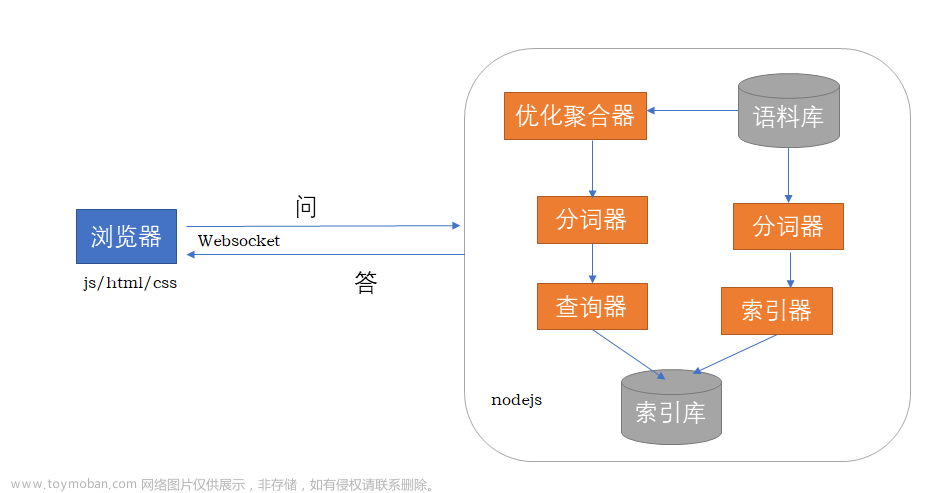
规划一个聊天机器人
- 智能化完全于依托于GPT, 而产品化是我们需要考虑的事情
- 比如,如何去构建一个聊天机器人
- 聊天机器人它的处理逻辑其实非常的清晰
- 我们输入问题调用 GPT
- 然后,GPT 给我们生成回答就可以了
- 需要注意的是,聊天机器人不同于调用API进行一个简单的测试
- 我们和聊天机器人的对话,可能是多轮的一个对话
- 在这时候,我们去调用API的时候,就需要将我们多轮的问答都传递给GPT才行
新增一些实现类,结构如下
-
以下Java版代码来源于网络,可基于此逻辑,改造成其他编程语言
-
src
- main
- java
- com.xxx.gpt.client
- util
- ChatContextHolder.java
- ChatBotClient.java
- …
- util
- com.xxx.gpt.client
- java
- test
- java
- com.xxx.gpt.client.test
- FunctionCallTest.java
- …
- com.xxx.gpt.client.test
- java
- main
ChatContextHolder.java文章来源:https://www.toymoban.com/news/detail-761325.html
package com.xxx.gpt.client.util;
import com.xxx.gpt.client.entity.Message;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class ChatContextHolder {
private static Map<String, List<Message>> context = new HashMap<>();
public static List<Message> get(String id) {
// TODO 限制轮数,或者限制token数量
List<Message> messages = context.get(id);
if (messages == null) {
messages = new ArrayList<>();
context.put(id, messages);
}
return messages;
}
public static void add(String id, String msg) {
Message message = Message.builder().content(msg).build();
add(id, message);
}
public static void add(String id, Message message) {
List<Message> messages = context.get(id);
if (messages == null) {
messages = new ArrayList<>();
context.put(id, messages);
}
messages.add(message);
}
public static void remove(String id) {
context.remove(id);
}
}
- 这里需要来添加一个类,就是我们GPT的上下文的类
- 我们创建一个类,用于保存我们和GPT聊天的相关的 message
- 实例化一个Map的对象, 里面的 key 是我们chat的一个id, 一个会话的id
- 然后,对应的这个key就会有它的一个消息的列表,也就是一个message的list
- 添加相关的方法
- 比如说像get方法,根据我们的会话id,获取到所有的message
- add方法,去对指定的会话id去添加message
- remove方法, 去删除message
- 这是我们的上下文处理的类
ChatBotClient.java文章来源地址https://www.toymoban.com/news/detail-761325.html
package com.xxx.gpt.client;
import com.xxx.gpt.client.entity.Message;
import com.xxx.gpt.client.listener.ConsoleStreamListener;
import com.xxx.gpt.client.util.ChatContextHolder;
import com.xxx.gpt.client.util.Proxys;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.Proxy;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.CountDownLatch;
import java.util.stream.Collectors;
@Slf4j
public class ChatBotClient {
public static Proxy proxy = Proxy.NO_PROXY;
public static void main(String[] args) {
System.out.println("ChatGPT - Java command-line interface");
System.out.println("Press enter twice to submit your question.");
System.out.println();
System.out.println("按两次回车以提交您的问题!!!");
String chatUuid = UUID.randomUUID().toString();
String key = "sk-adfas";
proxy = Proxys.http("127.0.0.1", 7890);
while (true) {
String prompt = getInput("\nYou:\n");
ChatGPTStreamClient chatGPT = ChatGPTStreamClient.builder()
.apiKey(key)
.proxy(proxy)
.build()
.init();
System.out.println("AI: ");
// 卡住
CountDownLatch countDownLatch = new CountDownLatch(1);
Message message = Message.of(prompt);
ChatContextHolder.add(chatUuid, message);
ConsoleStreamListener listener = new ConsoleStreamListener() {
@Override
public void onError(Throwable throwable, String response) {
throwable.printStackTrace();
countDownLatch.countDown();
}
};
listener.setOnComplate(msg -> {
ChatContextHolder.add(chatUuid, Message.ofAssistant(msg));
countDownLatch.countDown();
});
chatGPT.streamChatCompletion(ChatContextHolder.get(chatUuid), listener);
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@SneakyThrows
public static String getInput(String prompt) {
System.out.print(prompt);
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
List<String> lines = new ArrayList<>();
String line;
try {
while ((line = reader.readLine()) != null && !line.isEmpty()) {
lines.add(line);
}
} catch (IOException e) {
e.printStackTrace();
}
return lines.stream().collect(Collectors.joining("\n"));
}
}
- 它的实现其实也比较简单
- 第一步,需要等待用户输入,用户输入完成之后,调用GPT
- 添加一下相关的我们的 API KEY 和 proxy
- getInput 去接收用户输入
- 第二步,需要保存多轮会话
- 我们是多轮会话,我们这里写一个循环在前面
- chatUuid 是我们用于标识会话的id
- 第三步,为了效果更好,更加顺畅,采用流式的方式
- 创建一个 StreamClient 去调用GPT的 API
- 调用完成进行输出
- 第一步,需要等待用户输入,用户输入完成之后,调用GPT
测试
- 完成之后,可以测试一下
- 程序等待我们的输出,我们去询问一下: “你是谁?”
- 这里需要敲两次回车进行确认
- 调用之后,我们获取到了 GPT 它的返回的结果
- 然后,我们问: “请介绍一下ChatGPT”
- GPT生成了相关的答案
- 在这次问答当中,也能看到流式Client的一个效果
- 整体上和我们通过界面去访问GPT是没有什么区别的
- 假如说,我们现在再问: “这是我的第几个问题?”
- 理论上讲,这是我们本轮会话的第三个问题
- 由于我们没有在刚刚的调用里面, 去关联我们会话上下文的信息
- 这样,GPT会回答: “这是第3个问题”
- 将会话的上下文信息传递给 GPT, 就可以去结合这些上下文的信息,给予我们比较精确的一个答案
- 这是我们在构造一个聊天机器人的时候和前面测试所不一样的,需要我们注意的地方
- 但是在这里,其实就会有一个问题就是token的问题。
- GPT它的模型对于 token 是有限制的
- 如果我们一轮轮会话的叠加,最终我们的token, 一定会超过模型它本身的token
- 所以在上下文的管理类里面,我们这里是需要去进行处理
- 上述问题如何处理?
- 方案一就是保留最近一轮的会话轮数,比如只保留最近五轮
- 对于历史的消息,不再保存,不再发送给GPT这样,可以达到小于指定token数量的目的
- 但是当我们一轮的消息比较长的话,也有可能会超过token的阈值
- 方案二,就是在方案一的基础之上,我们不再以单纯会话的轮数去做一个迭代
- 这里,根据计算后的token的数量,去进行判断
- 如果小于模型的 max_token,我们就保留相关的这些会话
- 如果大于,我们就要去做相关消息的一个删减
- 目前并未实现,可在上述 ChatContextHolder.java 类中进行实现
- 方案一就是保留最近一轮的会话轮数,比如只保留最近五轮
到了这里,关于AIGC: 关于ChatGPT中实现一个聊天机器人的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!