BioMed-CLIP 论文阅读笔记

Abstract
本文聚焦于将VLP(vision-language processing)拓展到生物医学领域,介绍了一种迄今为止最大的生物医学VLP研究(使用了从PubMed Central中提取的15M 图像文本对)PMC-15M数据集的规模远大于现有数据集,并且涵盖不同你那个范围的生物医学图像。基于CLIP结构,作者提出了BiomedCLIP进行领域特定的调整。在广泛的研究和消融实验中取得了很好的成绩。大规模预训练在所有生物医学图像类型上具有实用性。
相关论文:Learning transferable visual models from natural language supervision.
1. INTRODUCTION

首先,作者指出了对于图文信息的学习中对比性预训练(contrastive pretraining)已经取得了不错的成绩。但是由于生物医学数据的限制(与通用领域的巨大差异、样本有限等),作者进行了针对于生物医学领域VLP的特定领域预训练,从PubMed Central中提取了包含15M个图像-文本对的数据集。同时,为了解决标准CLIP在生物医学领域上的限制,提出了BioCLIP,并在标准生物医学图像任务上进行了广泛实验,包括检索、分类和视觉问答(结果如图1所示,BioCLIP在许多数据集上取得了SoTA)。此外,BiomedCLIP还在RSNA肺炎检测等辐射学任务上超越了辐射学领域的最先进模型。
模型是开源的 项目地址aka.ms/biomedclip
2. METHODS
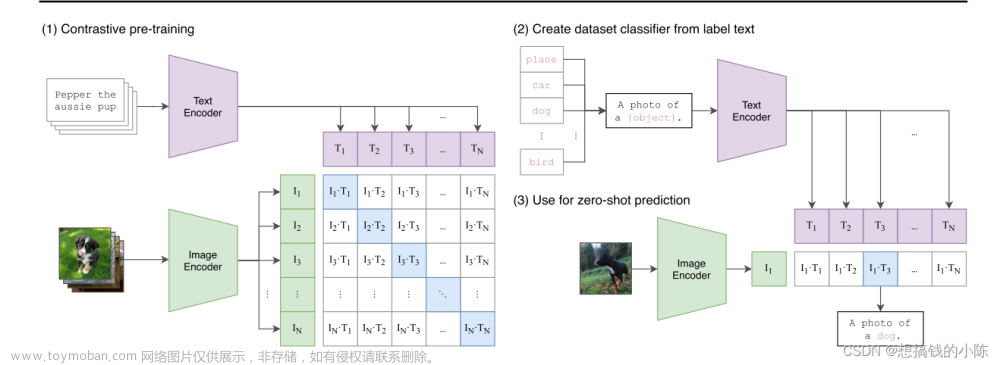
论文的工作内容及模型大致框架如图2所示,包括PMC-15M的生成管道和BioMedCLIP的预训练。

2.1 PMC-15M: A LARGE PARALLEL IMAGE-TEXT DATASET FOR BIOMEDICINE
将从动机、数据生成、统计数据、种类几个方面战术PMC-15M的数据生成。
Motivation
- **生物医学领域的训练数据匮乏:**图文并行数据上的预训练对数据要求很大,但是生物医学上存在着数据集规模小且集中在胸部X射线上的限制。
- **大模型预训练的优势:**在通用领域的研究表明在多样性大规模数据集上进行预训练具有优势。
-
借助公开的医疗图像资源: 引入
PubMed作为生物医学研究论文的综合存储库,尤其是在先前研究的基础上增加了图像数据。数据地址 - **方法:**利用文章中丰富的图像-标题对进行生物医学领域的视觉-语言训练。
Data Creation
通过下载PubMed Central的可公开全文文章,并从中提取图像文件和相应的标题。
Statics
下表展示了数据集的统计信息,作者按照13.9M、13.6k和726k的比例将数据分为训练集、验证集和测试集。关于具体的数据信息如图3所示,图像和标题的长度很多不在CLIP的默认大小内。

图像标题长度和尺寸的统计信息如下,仅有红框以内的是可以直接在CLIP使用的。

Diversity
使用了词云和García Seco de Herrera等人(2015)引入的分类法来探究图像的类别多样性和覆盖范围,分别如图5、图4所示。PMC-15M中的图像极其多样,包括了从通用的生物医学插图(如统计图、图表、表格和表单)到放射学(如磁共振、计算机断层扫描和X射线)再到显微镜学(如透射显微镜和电子显微镜)等各种类型。

图4中展示了PMC-15M中排名前20的图像类型,涉及的分类方法为每种图像类型手动分配了关键词,并根据关键词的频率之和估计了每种图像类型的频率。

2.2 BIOMEDCLIP: LARGE-SCALE VISION-LANGUAGE PRETRAINING FOR BIOMEDICINE
Background
首先介绍一下CLIP模型的预训练方法,对于一个大小为
N
N
N 的图像文本对,CLIP通过联合训练图像编码器和文本编码器学习多模态嵌入空间,学习目的是使匹配的图文余弦相似度最大化,不匹配的最小化。损失函数如下,最小化InfoNCE 损失。下列公式中,
I
i
\mathbf{I}_i
Ii 和
T
i
\mathbf{T}_i
Ti 分别表示第
i
i
i 个图像-文本对的图像和文本嵌入向量。
L
=
−
1
2
N
(
∑
i
=
1
N
log
e
c
o
s
(
I
i
,
T
i
)
/
τ
∑
j
=
1
N
e
c
o
s
(
I
i
,
T
j
)
/
τ
)
\mathcal{L}=-\frac{1}{2N}(\sum_{i=1}^{N}\log\frac{e^{cos(\mathbf{I}_i,\mathbf{T}_i)/\tau}}{\sum^{N}_{j=1}e^{cos(\mathbf{I}_i,\mathbf{T}_j)/\tau}})
L=−2N1(i=1∑Nlog∑j=1Necos(Ii,Tj)/τecos(Ii,Ti)/τ)CLIP不采用预先训练好的模型权重而是从头开始训练图像和文本编码器,这样可以减少其他任务带来的影响。
- 对于图像编码器,考虑
ResNet-50和ViT - 对于文字编码器,采用
GPT-2
Adapting CLIP for the biomedical domain
作者采用了一种有针对性的方法,针对生物医学领域的特点进行了CLIP模型的优化。
在文本方面作者采取的主要措施包括:
- **采用适配生物医学领域的预训练模型:**使用在生物医学任务重性能较好的
PubMedBERT来替代传统CLIP中的GPT-2。 - **更改分词器:**使用
WordPiece分词器替换BPE分词器,WordPiece基于unigram可能性形成标记,可以更好得保留专业术语。 - **上下文大小调整:**将上下文大小扩展到256,如图3所示,256的大小可以覆盖90%图片标题。
调整后的性能改进如表2所示。

在图像方面作者采取的措施包括:
- **选用合适规模的ViT(Visual Transformer):**经过对
ViT-Small,ViT-Medium和ViT-Base的性能评估,发现规模较大的ViT在PMC-15M上的性能较好。

- **提高图像分辨率:**将图像分辨率从 224 × 224 224\times 224 224×224 提升到 336 × 336 336\times 336 336×336 ,但是这样会导致训练代价变大。因此采取了措施 随机丢弃50%图像块 来恢复训练速度,并使用 非掩码调整 (unmasked tuning)来让模型观察到整个图像而不受遮挡的限制,提高泛化能力。实验结果如下,可以观察到采用随机丢弃后的预训练性能更加,猜想是由于正则化效应。

正则化效应
正则化效应是指在机器学习中使用正则化技术时,对模型的训练产生的一种影响。正则化的目的是防止模型在训练数据上过度拟合,以提高其在未见数据上的泛化能力。正则化方法通常通过向模型的损失函数中添加一个正则化项来实现,该项惩罚模型参数的复杂度。
以文章中的方案为例,采取50%随机丢弃会导致模型过于关注细节和子图,引入正则化效应可以让模型更倾向于学习通用特征二不会依赖噪声或图像细节。
非掩码调整(unmask tuning)
非掩码调整(unmasked tuning)通常是指在模型训练的过程中,允许模型观察到整个输入,而不是通过一些形式的掩码或部分遮挡来限制其看到的信息。其目的可能是为了在模型训练中引入一些噪声和多样性,以提高模型的鲁棒性和泛化能力。
在批次大小(batch size)上的措施主要如下。
- 批量大小的增加: 通过梯度累积(gradient accumulation)的方式增加批量大小,该方法缓存每个子迭代的嵌入(embeddings),并在达到批量大小之前计算梯度。
-
两种批处理计划的研究:
- 使用常数批大小(4k)进行40个周期的训练。
- 在前8个周期使用批大小为4k,然后在剩余32个周期中使用批大小为64k。
经过对比实验(结果如表5所示),从较小的批量大小开始,然后逐渐增加批量大小,能够取得学习速度和稳定性之间的最佳平衡。
使用梯度累积来增加batch size
在标准的梯度下降优化过程中,模型参数的更新是通过计算并应用整个批次的梯度来完成的。批次的大小越大,梯度计算所需的内存就越多。梯度累积通过在多个小批次上计算梯度,然后将这些梯度累积(相加),最后在累积的梯度上进行一次参数更新。具体而言,该过程通常包括以下步骤:
- 前向传播: 对于每个小批次,进行前向传播以计算损失。
- 反向传播: 对每个小批次进行反向传播,计算梯度。
- 梯度累积: 将所有小批次的梯度进行累积(相加)。
- 参数更新: 在累积的梯度上进行一次参数更新。
Putting it all together
根据上面的研究与训练了多个BioCLIP模型并与CLIP进行对比,在验证集的表现如表6所示。

Implement
- **框架选择:**使用
OpenCLIP作为实现基础,这是一个为了进行大规模分布式对比图像文本监督训练而调整的开源软件。 - 硬件和分布式训练: 在预训练实验中,作者利用最多16个NVIDIA A100 GPU或16个NVIDIA V100 GPU,并采用PyTorch DDP进行分布式训练。
- 超参数设置: 实验所用的超参数详见附录A。
- 内存消耗优化: 为减少内存消耗,作者启用了梯度检查点和自动混合精度(AMP),使用bfloat16数据类型(在硬件支持的情况下)。
- 分片对比损失: 采用了分片对比损失,与InfoNCE相比具有相同的梯度,通过消除冗余计算和仅计算每个GPU上的局部相关特征的相似度,降低内存使用。

3. EVALUATIONS
3.1 EVALUATING BIOMEDICAL VISION-LANGUAGE MODELS
预训练的总体目标是即提高在各种下游应用中的性能。对于模型进行多个任务的测试,包括跨模态检索(Cross-Modal Retrieval)、图像分类(Image Classification)和视觉问答(VQA)。具体如表7所示。

3.2 CROSS-MODAL RETRIEVAL
跨模态检索的评估包括从标题到图像和从图像到标题的检索,这反映了现实应用中的图像搜索和文本生成任务。作者使用了PMC-15M的保留测试集,其中包含725,739个PMC图题对,作为评估的基础数据。
为了评估检索性能,作者将图像和文本先嵌入同一个向量空间并进行近似最邻近搜索(分别包括最临近、前5、前10 三组测试)。结果如表8所示,可以看到传统CLIP进而被受期待的PubMedCLIP的效果非常不好,而作者团队提出的预训练模型(BiomedCLIP ViT-B/16-224-GPT/77)表现非常出色。(第四行的PMB表示使用PubMedBERT作为语言模型)。

Case Study
如下图所示,为了具体表现新模型的性能优势,随机选取了几个题目进行检索,找到最接近的四个图像,并用黄色方框标出正确答案。可以看到BioMed-CLIP几乎都能找到最佳答案,而CLIP基本找不到。

3.3 IMAGE CLASSIFICATION
作者在图像分类实验中使用了一个名为 ELEVATER 的评估工具包,作者使用了其中的生物医学数据集PatchCamelyon,还在三个标准的生物医学图像基准测试 LC25000、TCGA-TIL 和 RSNA 上进行了评估。
ELEVATER包括三个主要组成部分:
(i)数据集,包括20个图像分类数据集和35个目标检测数据集,每个都经过外部知识增强;
(ii)工具包,提供自动超参数调整工具,以便在下游任务上进行模型评估;
(iii)度量标准,使用多种评估指标来衡量样本效率(零样本和少样本)和参数效率(线性探查和完整模型微调)。
参考论文:ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models 论文链接
Datasets
数据集的大致情况表7所示,具体的信息如下。
| 数据集 | 数量/分辨率 | 图像描述/来源 | 其他 |
|---|---|---|---|
| PCam | 包含 327,680 张颜色图像,分辨率为 96×96 像素。 | 图像来自淋巴结切片的组织病理学扫描。 | 图像被标记为二进制标签,表示是否包含转移性组织。 |
| LC25000 | 包含 25,000 张组织病理学图像,分辨率为 768×768 像素。 | 图像通过增强生成,来源于一组经过 HIPAA 认证的、验证过的原始图像。 | 数据集分为五类:肺良性组织、肺腺癌、肺鳞状细胞癌、结肠腺癌和结肠良性组织,每类包含 5,000 张图像。 |
| TCGATIL | 包含 2,480 个图像块,分辨率为 500×500 像素。 | 图像从癌症基因组图谱(TCGA)的肺腺癌(LUAD)整张切片图像中划分出来。 | / |
| RSNA Pneumonia | 30,000 张前视胸部 X 射线图。 | 来自美国国立卫生研究院的胸部 X 射线公共数据库。 | 数据集包含二进制标签,对肺炎和正常病例进行分类。 |
Zero-shot settings
作者在BiomedCLIP模型上进行零样本性能评估,并将其与三个基线模型(CLIP、MedCLIP和PubMedCLIP)进行比较。结果如下图所示,BioMedCLIP表现出了很好的零样本学习能力,但是增大分辨率之后效果反而不好,这部分作者提出疑问。

Supervised settings
监督学习的结果如表10所示,BioMedCLIP的性能达到了SoTA。BiomedCLIP仅使用10%的标记数据就已经超过了完全监督的BioViL(先前的SoTA)。总体大规模训练可能会使图像编码器性能更强大。

3.4 MEDICAL VISUAL QUESTION ANSWERING (VQA)
在VQA任务中采用了METER框架,将VQA任务视作一个分类任务,核心模块是一个基于Transformer的协同注意力多模态融合模块,用于生成图像和文本编码的跨模态表示,然后通过分类器预测最终答案。
METER框架
METER的全称是 Multimodal End-to-end TransformER,旨在探讨如何设计和预训练一个完全基于Transformer的视觉与语言(VL)模型。如下图所示,
METER框架包括一个图像编码器和文本编码器,通过两个编码器提取两个维度的特征之后进行模态融合以产生跨模态表示,最终选择性送入文本解码器。
参考论文:An Empirical Study of Training End-to-End Vision-and-Language Transformers 论文链接

研究中将BiomedCLIP与通用领域的CLIP、仅在视觉数据上进行预训练的MAML(Model-Agnostic Meta-Learning)网络以及最先进的PubMedCLIP进行比较。这三个模型都在VQA任务上进行了微调,使用QCR(Question answering via Conditional Reasoning)框架,该框架交替使用基于MLP的注意力网络和带有条件推理的融合模块。
QCR框架
问题条件推理模块,是一种框架中的关键组成部分,用于引导多模态融合特征的调制。其主要目标是让Med-VQA系统能够学习并应用不同的推理技能,以根据提出的问题找到正确的答案。这通过对多模态特征的组合进行考虑,并通过对融合表示进行额外的变换来实现,从而识别问题特定的推理信息。
具体的框架如下:
- 对于一个给定的问题 q q q,进行词嵌入得到词向量矩阵 Q e m b Q_{emb} Qemb;
- 对于得到的 Q e m b Q_{emb} Qemb经过门控循环单元(Gated Recurrent Unit,GRU)按照单词顺序生成一系列隐藏状态,得到问题的嵌入矩阵 Q f e a t Q_{feat} Qfeat;
- 对于生成的问题嵌入矩阵,使用注意力机制对不同单词赋予权重,得到注意力向量,并根据问题嵌入和注意力,经过多层感知机(MLP)得到QCR的最终输出。
最后将QCR的输出输入多分类器中得到预测分数。参考论文:Medical Visual Question Answering via Conditional Reasoning论文链接

Datasets
实验使用的数据集信息如下所示。
| 数据集 | 图像数量 | 问答对数量 | 其他信息 |
|---|---|---|---|
| VQA-RAD | 315 张放射学图像 | 3,515 个由临床医生手工构建的问题-答案对 | 测试集中的图像也存在于训练集中,但问题-答案对没有重叠。 |
| SLAKE | 642 张放射学图像 | 由经验丰富的医生注释的 7,000 多个问题-答案对 | 涵盖的人体部位比 VQA-RAD 更多,且训练集和测试集之间没有共同的图像。 |
测试结果如下图所示,可以看到除了在VQA-RAD数据集的闭合问答中略逊于PubMedCLIP,其他都远高于现有的模型。

Case Study
选择了一个先前的最有模型都无法正确回答的样例作研究。可以看到其他的模型对于问题的理解非常不清晰,而BioMed-CLIP能回答其中的两个问题。
4. LIMITATIONS
文章提到的BioMed-CLIP方法的局限性主要如下:
- 复合图形处理: 当前的数据处理流程对复合图形没有进行特殊处理。一种可行的思路是将其拆分为子图,但是这也涉及到合理划分的问题。
- 上下文引用的利用: 除了标题之外,内联引用的上下文也可以与相应的图形自然地配对,以创建额外的训练信号。当前的数据处理流程未涉及这一点。
-
计算资源限制: 由于计算资源的限制,输入图像大小448也受到计算资源的限制,没有引入于
ViT-L、ViT-H和ViT-G等视觉编码器。 -
预训练与下游任务性能差距: 观察到预训练和一些下游图像分类任务之间存在性能差距。最佳的BiomedCLIP模型“
ViT-B/16-448-PMB/256”在这些任务上表现不佳。使用较小图像大小或预训练较短时期的BiomedCLIP模型表现更好。这是因为PubMed文章通常经过策划,并包含在更大研究中为了优化相关发现而包含的图像,因此其分布可能倾向于不太常见的病理情况,而不是在典型医学环境中看到的情况。(个人认为可能类似于过拟合现象?)
5. RELATED WORKS
通用领域的视觉-语言表示学习
- 在通用领域任务中根据图像预测字幕来学习视觉表示有一些不错的成果,但是它们受限与较小的数据集,并且学习得到的模型并不适用于跨模态任务。
- 提出视觉语义嵌入模型,接着引入对象检测器、密集特征图或者使用多注意力层来改进模型。
- 进来对于跨模态注意力层的改进虽然表现很好但是速率很慢,不适用于大数据集。
- 21年之后的文章则提取了一些能从网页数据中学习并取得优秀表现的视觉-语言表示。
生物医学领域的图像-文本预训练研究主要集中在胸部X射线(CXR)方面,并且训练数据量有限。其中包含的一些技术如下。
-
自监督学习方法的引入:
-
Contrastive Learning of Medical Visual Representations from Paired Images and Text(
ConVIRT,2020):- 利用自监督学习中的对比损失,通过自然匹配的医学图像和文本数据进行预训练。
- 收获了对比损失在医学图像处理中的潜在优势。
-
Contrastive Learning of Medical Visual Representations from Paired Images and Text(
-
全局和局部表示的联合学习:
-
GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-Efficient Medical Image Recognition(
GLoRIA,2021):- 在通用领域词汇下,通过对比关注权重的方式,共同学习医学图像的全局和局部表示。
-
GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-Efficient Medical Image Recognition(
-
多模态预训练的发展:
-
Joint Learning of Localized Representations from Medical Images and Reports(
LoVT,2022):- 进一步探索了多模态预训练,将图像区域的局部表示与文本句子对齐。
-
Multimodal representation learning via maximization of local mutual information,2021:
- 提出通过最大化图像和文本的局部特征互信息来学习多模态表示。
-
Joint Learning of Localized Representations from Medical Images and Reports(
-
领域微调与评估:
-
Self-supervised Image-text Pre-training With Mixed Data In Chest X-rays(
PubMedCLIP,2021):- 在PubMed Central的数据集上微调,但由于过滤和手动修订,规模和多样性有限。
- 主要评估针对医学图像和文本的视觉问答任务。
-
Self-supervised Image-text Pre-training With Mixed Data In Chest X-rays(
-
扩展到Transformer框架的应用:
-
Self-supervised Image-text Pre-training With Mixed Data In Chest X-rays:
- 提出了一个基于Transformer的框架,采用混合图像-文本预训练目标。
- 展示了采用预训练模型在医学图像处理中的潜在优势。
-
Self-supervised Image-text Pre-training With Mixed Data In Chest X-rays:
6. CONCLUSION
这篇文章主要涉及以下几个方面的内容文章来源:https://www.toymoban.com/news/detail-761371.html
- **数据集建立:**利用了来自PubMed Central全文文章的1500万图像-标题配对,其中把汗了各种乐行的图像,适用于不同医学人物。
- **领域特定调整:**对
CLIP模型进行了领域特定调整以优化模型性能并提出BioMed-CLIP模型。 - **实验成果:**在八个标准的生物医学数据集上进行了广泛实验,BiomedCLIP在跨模态检索、图像分类和视觉问题回答等多个任务上取得了新的最先进成果。
- **未来方向:**包括进一步改进预训练和微调、探索多模态生成技术,以及将模型应用于实际场景,如图像搜索、数字病理学和精准医学中的多模态融合。
代码是开源的。文章来源地址https://www.toymoban.com/news/detail-761371.html
到了这里,关于BioMed-CLIP 论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!