一.引言
“性能优化”,从计算机诞生之初就一直伴随着计算机技术的发展,直到现在。将来也必定不会消失。这是因为每个人都会追求性价比,花最少的钱,办最多的事。生活中也一样,就比如说泡茶,但凡有点常识的人都不会先洗茶杯,再去烧水,而是先去烧水,在等水开的过程中,去做洗茶杯等工作。这也是一种优化。
本篇尝试带大家从计算机系统的角度,简单介绍一下几种性能优化的原理和方法,抛砖引玉,供大家参考。
二.访问寄存器代替内存引用
我们先看一个例子:
有这么两个程序:它们的目的就是将数组x中的数,按照下标累加到数组y中,最后在把数组y中的数据累加到一个数dest里面。为了验证效果,我们将这个过程重复10000遍。

Prog 1 Prog2
这两个程序的区别就在Prog2中红框里面的内容。那么哪个程序运行的更快呢?
话不多说,我们看实际的结果:


这里为了说明效果,我们编译的时候,并没有采用优化(编译优化,确实可以提高程序运行的效率,但是过高的编译优化等级会有一定的副作用,另外编译器优化也具有一定的局限性,高效的代码仍然应该是我们追求的目标)。可以看到,Prog2要明显比Prog1快。
要想理解上面的例子,我们必须先介绍一下寄存器和汇编代码的相关知识:
1.寄存器
CPU内部用来存放数据的一些小型存储区域, 注意寄存器是在CPU内部,受限于CPU的物理尺寸,寄存器数量不会太多。我们只需要记住两点:
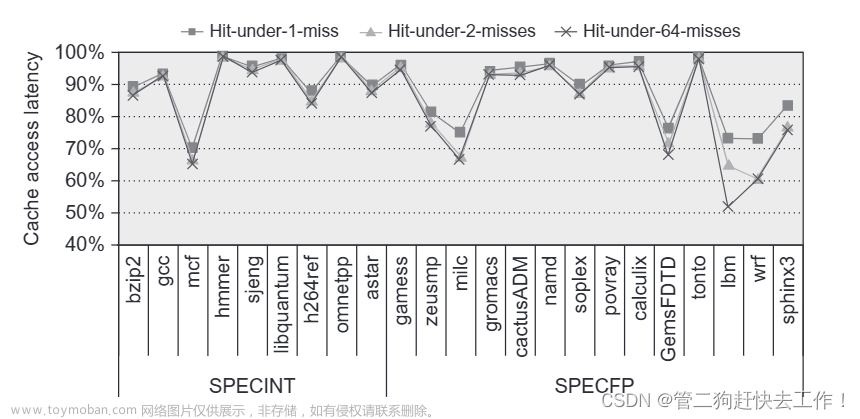
1) 寄存器和CPU的L1 cache相比,速度虽然还在一个数量级,但是L1 cache的访问速度还是要慢几倍。具体的数据见下文表2
2) CPU只能从寄存器直接取数据或者指令,如果取不到,获取的顺序是L1->L2->L3->主存->磁盘。
从下文表2中可以看出,如果cpu的cache访问miss了,性能损失还是很大的。如果内存里面再miss了,那对性能来说不亚于一场灾难了。
计算机访问速度分级:
表1 时间单位

以3.3GHz的CPU为例:
表2 系统的各种延时

正如你所见,CPU周期的时间非常短,这段时间,光的速度大约只能走0.5米。想象一下,是不是非常震撼?
x86-64 CPU的整数寄存器:

我们无需刻意去记住这些寄存器的名称,不同架构的寄存器的数量和名称也不一样,我们只要知道他们是cpu内部的效率极高的存储单元即可。
回到前面的例子,为什么Prog2要比Prog1快,是因为Prog2里面用DEST这个局部变量代替了*dest。DEST是一个局部变量,在汇编指令里是直接访问寄存器,而*dest则需要去访问内存cache。
2.汇编代码简介
说到汇编语言的产生,首先要讲一下机器语言。机器语言是机器指令的集合。机器指令展开来讲就是一台机器可以正确执行的命令。电子计算机的机器指令是一列二进制数字。计算机将之转变为一列高低电平,以使计算机的电子器件受到驱动,进行运算。
上面所说的计算机指的是可以执行机器指令,进行运算的机器。这是早期计算机的概念。在我们常用的PC机中,有一个芯片来完成上面所说的计算机的功能。这个芯片就是我们常说的CPU(Central Processing Unit,中央处理单元)。每一种微处理器,由于硬件设计和内部结构的不同,就需要用不同的电平脉冲来控制,使它工作。所以每一种微处理器都有自己的机器指令集,也就是机器语言。
早期的程序设计均使用机器语言。程序员们将用0, 1数字编成的程序代码打在纸带或卡片上,1打孔,0不打孔,再将程序通过纸带机或卡片机输入计算机,进行运算。这样的机器语言由纯粹的0和1构成,十分复杂,不方便阅读和修改,也容易产生错误。

程序员们很快就发现了使用机器语言带来的麻烦(何止是麻烦,简直令人发狂),它们难于辨别和记忆,给整个产业的发展带来了障碍,于是汇编语言产生了。
汇编语言的主体是汇编指令。汇编指令和机器指令的差别在于指令的表示方法上。汇编指令是机器指令便于记忆的书写格式。
我们举个例子看下:
源代码:

汇编代码和机器码:

可以看到汇编代码,好歹还有几个能猜出意思的单词。
有没有觉得现在的程序员还是挺幸福的。
3.汇编指令简介
汇编语言是计算机语言的一种,是一种低级语言。相比高级语言,汇编语言更接近底层硬件,使用更加直接,效率更高。但相对而言,汇编语言更加复杂,语法更加严格。
操作数指示符:
大多数指令有一个或多个操作数,指示出执行一个操作中要使用的源数据值。
操作数一般可以分为三类:
立即数
寄存器
内存引用

数据传送指令:
最频繁使用的指令,负责将数据从一个位置复制到另一个位置。
例如:
mov %rbx, %rax : 将rbx寄存器的值移动到rax寄存器
mov %rbx, (%rax) : 将rbx寄存器的值移动到rax寄存器所表示的内存地址中
以及mov指令的一些扩展指令: movb, movw, movl, movq等等
压入和弹出栈数据
将数据压入程序栈中,以及从程序栈中弹出数据。
push %rbp : 将%rbp寄存器的值压入程序栈指针指向的位置
pop %rbp : 将栈指针指向的数据弹出,放入%rbp寄存器
算数和逻辑操作

跳转指令
导致执行切换到程序中一个全新的位置
jmp %rax 用寄存器%rax中的值作为跳转目标
jmp是无条件跳转,还有一些条件跳转指令,有兴趣的同学可以查一下资料。
比较和测试指令
比较指令CMP,只设置条件码,不更新目的寄存器,其余的行为和SUB指令一致
测试指令TEST,只设置条件码,不更新目的寄存器,其余的行为和ADD指令一致
更多详细的内容,可以通过相关书籍进行系统性的了解,鉴于篇幅,就不多介绍了。
让我们回到刚才的例子,可以看到由于把内存引用替换成了访问寄存器,程序性能就有了明显的提升。
三.帮助提高CPU分支跳转的正确率
我们还是先看一个例子:

看上面的两个函数,它们都是calloc一个全零数组x(这里不能直接用数组赋值,否则编译器会足够聪明进行自动的优化),遍历x中的每个数,如果等于0,执行分支A,否则执行分支B。
唯一的不同就是在分支判断的时候,prog2.c加了likely。我们先看下实际的结果如何:


可以看出,加了likely的prog2,明显用时变短。原因何在?
为了理解上面的例子,我们先介绍CPU流水线相关知识:
3.1. CPU流水线简介
CPU流水线是一种使用多级缓存来提高处理器性能的技术。它是指将CPU操作分为多个阶段,每个阶段单独完成一个操作,然后将结果传递给下一个阶段,以此类推。每个阶段都有一个独立的部件,并且所有部件都能同时处理不同的指令。现代CPU都会采用这种技术来提高CPU的运行效率。
CPU流水线通常包括以下五个阶段:
1)取指令(Instruction fetch):从存储器中读取指令。
2)指令译码(Instruction decode):将指令转换为可执行的指令。
3)执行指令(Instruction execute):执行指令的操作。
4)写回(Write back):将执行指令得到的结果写回内存中。
5)更新程序计数器(Update program counter):将程序计数器加1,使它指向下一个指令。
举个简单的例子:
我们假设每一个步骤执行时间都是一个时钟周期,那么一条指令执行需要3个时钟周期

CPU 执行指令的3个时钟周期里,取值单元只在第一个时钟周期里工作,其余两个时钟周期都处于空闲状态,其它两个执行单元也是如此,效率太低了。
解决方法就是引入流水线,引入流水线工作模式后可以看到,除了刚开始第一个时钟周期大家还可以偷懒外,其余的时间都不会闲着

CPU流水线的优点是可以同时执行多个指令,从而提高了处理器的效率。但它也存在一些问题,例如数据相关性(Data dependency)和控制相关性(Control dependency),这些问题可能导致流水线停滞,降低CPU的性能。
执行的程序指令如果是顺序结构,没有中断或跳转,流水线确实可以提高执行效率。但是当程序指令中存在跳转、分支结构时,下面预取的指令可能就要全部丢掉了,需要到要跳转的地方重新取指令执行。一般来说分支预测错误的处罚大约是19个时钟周期。(具体计算方法这里不做详细介绍了)。
我们看下前面提到的例子汇编出来的结果:

prog2,这里汇编是”jne”,意思是如果判断结果不为0,就跳转到地址 800 的地方执行。我们知道这里的判断一直是0。所以,cpu指令顺序向下执行,并不会发生预判错误,预取的指令也不会丢弃。这样就不会遭到分支预测错误的惩罚,效率会提高。
所以有些情况下,当我们根据实际的情况可以判断出哪条分支的可能性更高的时候,我们就可以站在上帝视角给予一定的提示,这样就可以降低分支预测错误,减少CPU的无用功了,从而可以有效的提高性能,同时也节省了功耗。
四.总结
从计算机系统的角度来看,性能优化的几个思考方向:
1. 尽可能高效的获取数据
2. 尽可能减少CPU的无用功。
3. 尽可能在有限的时间内,让CPU干更多的有效的事情。
4. 完成同样的工作任务,尽可能的让CPU少做事。
参考资料:
1.《深入理解计算机系统》作者:【美】兰德尔E.布莱恩特 【美】大卫R.奥哈拉伦
2.《性能之巅》作者:【美】 Brendan Gregg
3. CSND博客:宋宝华:深入理解cache对写好代码至关重要
往
期
推
荐
超详细!Linux内核内存规整详解
关于Ultra HDR Image的那些事
多图文教你看懂单个图层的绘制流程

长按关注内核工匠微信文章来源:https://www.toymoban.com/news/detail-761528.html
Linux内核黑科技| 技术文章| 精选教程文章来源地址https://www.toymoban.com/news/detail-761528.html
到了这里,关于深入计算机系统看性能优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!