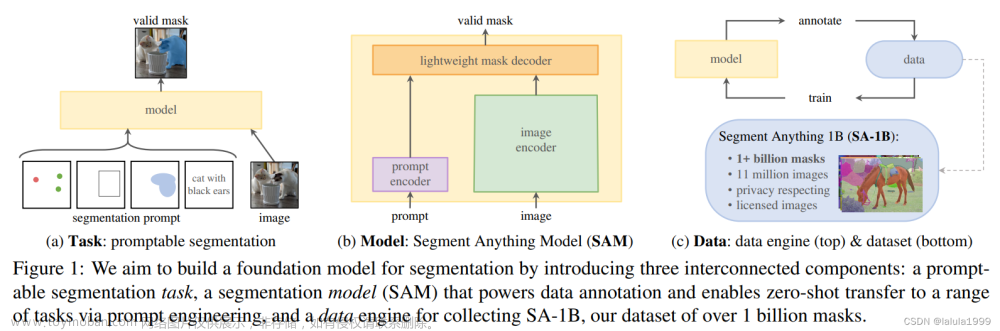
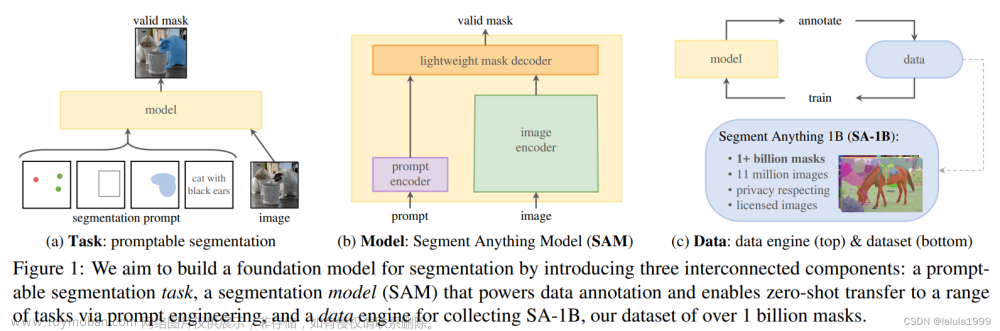
摘要:从图像输入模型开始,梳理TransUNet模型流程。
注:这里n_patches原代码设置196,但自己在分割硬渗出物的时候设置成了1024,不知道会不会使得效果变差
一. class VisionTransformer()
图片开始进入模型所在代码行:
outputs = model(image_batch) # (B,n_classes,H,W)
然后进入类VisionTransformer(nn.Moudle)
class VisionTransformer(nn.Module):
def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.zero_head = zero_head
self.classifier = config.classifier
self.transformer = Transformer(config, img_size, vis)
self.decoder = DecoderCup(config)
self.segmentation_head = SegmentationHead(
in_channels=config['decoder_channels'][-1],
out_channels=config['n_classes'],
kernel_size=3,
)
self.config = config
def forward(self, x):
if x.size()[1] == 1: # 如果图片是灰度图就在其通道方向进行复制从1维转成3维(比如CT图像就是灰度图)
x = x.repeat(1,3,1,1) # (B,3,H,W)
# 然后将x送入self.trasnformer中,实现在1节
x, attn_weights, features = self.transformer(x)
# (B, n_patch, hidden):(B,196,768) # features:(B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
x = self.decoder(x, features)
logits = self.segmentation_head(x)
return logits
1. self.transformer()
class Transformer(nn.Module):
def __init__(self, config, img_size, vis):
super(Transformer, self).__init__()
self.embeddings = Embeddings(config, img_size=img_size)
self.encoder = Encoder(config, vis)
def forward(self, input_ids): # (B,3,H,W)
# 将x送入self.embeddings中,实现在1.1节
embedding_output, features = self.embeddings(input_ids) # (B, 1024, 768) # (B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
encoded, attn_weights = self.encoder(embedding_output) # (B, n_patchs, hidden)
return encoded, attn_weights, features
这部分实现:features:表示CNN支路中的3个特征图;embedding_output:表示Transformer支路的输入;self.encoder:即Transformer支路的实现;encoded:表示
1.1. self.embeddings()
class Embeddings(nn.Module):
"""Construct the embeddings from patch, position embeddings.
"""
def __init__(self, config, img_size, in_channels=3):
super(Embeddings, self).__init__()
self.hybrid = None
self.config = config
img_size = _pair(img_size)
if config.patches.get("grid") is not None: # ResNet
grid_size = config.patches["grid"] # (14,14)
patch_size = (img_size[0] // 16 // grid_size[0], img_size[1] // 16 // grid_size[1]) # (1,1)
patch_size_real = (patch_size[0] * 16, patch_size[1] * 16) # (16,16)
n_patches = (img_size[0] // patch_size_real[0]) * (img_size[1] // patch_size_real[1]) # 14*14
self.hybrid = True
else:
patch_size = _pair(config.patches["size"])
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])
self.hybrid = False
if self.hybrid:
self.hybrid_model = ResNetV2(block_units=config.resnet.num_layers, width_factor=config.resnet.width_factor)
in_channels = self.hybrid_model.width * 16
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=patch_size,
stride=patch_size)
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, config.hidden_size)) # (1,n_patches, hidden): (1,196,768)
self.dropout = Dropout(config.transformer["dropout_rate"])
def forward(self, x):
if self.hybrid: # True
# 将x送入self.hybrid_model中,实现在1.1.1节
x, features = self.hybrid_model(x) # (B,3,H,W) -> (B,1024,H/16,W/16)
else:
features = None
x = self.patch_embeddings(x) # (B, hidden. n_patches^(1/2), n_patches^(1/2)) = (B,768,H/16,W/16)
x = x.flatten(2) # (B, hidden, n_patches)
x = x.transpose(-1, -2) # (B, n_patches, hidden) = (B, 1024, 768)
embeddings = x + self.position_embeddings # (B, 1024, 768)
embeddings = self.dropout(embeddings)
return embeddings, features
1.1.1. self.hybrid_model()
class ResNetV2(nn.Module):
"""Implementation of Pre-activation (v2) ResNet mode."""
def __init__(self, block_units, width_factor): # (3,4,9); 1
super().__init__()
width = int(64 * width_factor)
self.width = width
self.root = nn.Sequential(OrderedDict([
('conv', StdConv2d(3, width, kernel_size=7, stride=2, bias=False, padding=3)),
('gn', nn.GroupNorm(32, width, eps=1e-6)),
('relu', nn.ReLU(inplace=True)),
# ('pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=0))
]))
self.body = nn.Sequential(OrderedDict([
('block1', nn.Sequential(OrderedDict(
[('unit1', PreActBottleneck(cin=width, cout=width*4, cmid=width))] +
[(f'unit{i:d}', PreActBottleneck(cin=width*4, cout=width*4, cmid=width)) for i in range(2, block_units[0] + 1)],
))),
('block2', nn.Sequential(OrderedDict(
[('unit1', PreActBottleneck(cin=width*4, cout=width*8, cmid=width*2, stride=2))] +
[(f'unit{i:d}', PreActBottleneck(cin=width*8, cout=width*8, cmid=width*2)) for i in range(2, block_units[1] + 1)],
))),
('block3', nn.Sequential(OrderedDict(
[('unit1', PreActBottleneck(cin=width*8, cout=width*16, cmid=width*4, stride=2))] +
[(f'unit{i:d}', PreActBottleneck(cin=width*16, cout=width*16, cmid=width*4)) for i in range(2, block_units[2] + 1)],
))),
]))
def forward(self, x): # (B,3,H,W)
features = []
b, c, in_size, _ = x.size() # B,3,H
x = self.root(x) # (B,3,H,W) -> (B,64,H/2,W/2)
features.append(x) # (B,64,H/2,W/2)
x = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)(x) # (B,64,H/4-1,W/4-1)
for i in range(len(self.body)-1): # i: 0 ; 1
x = self.body[i](x) # (B,256,H/4-1,W/4-1);(B,512,H/8,W/8)
right_size = int(in_size / 4 / (i+1)) # 56,28
# 进行补0操作,将特征图size补成right_size
if x.size()[2] != right_size:
pad = right_size - x.size()[2]
assert pad < 3 and pad > 0, "x {} should {}".format(x.size(), right_size)
feat = torch.zeros((b, x.size()[1], right_size, right_size), device=x.device) # (B,256,H/4,W/4)
feat[:, :, 0:x.size()[2], 0:x.size()[3]] = x[:]
else:
feat = x
# 这三个特征图就是CNNs分支里的
features.append(feat) # (B,64,H/2,W/2);(B,256,H/4,W/4);(B,512,H/8,W/8)
x = self.body[-1](x) # (B,1024,H/16,W/16)
return x, features[::-1] #对features逆序排序
到这里,这部分代码就走完了,接下来将x,features两个参数传入类Embeddings,继续1.1小节
1.1.(2)
为了简洁,这里就只显示前向传播forward过程
def forward(self, x):
if self.hybrid: # True
# 将x送入self.hybrid_model中,实现在1.1.1节
x, features = self.hybrid_model(x) # (B,3,H,W) -> (B,1024,H/16,W/16)
# x:(B,1024,H/16,W/16)
# features[0]:(B,512,H/8,W/8)
# features[1]:(B,256,H/4,W/4)
# features[2]:(B,64,H/2,W/2)
else:
features = None
# patch_embedding是通过卷积层实现的, channel数变化:1024->768
x = self.patch_embeddings(x) # (B, hidden. n_patches^(1/2), n_patches^(1/2)) = (B,768,H/16,W/16)
x = x.flatten(2) # (B, hidden, n_patches) = (B, 768, H*W/(16*16) )
x = x.transpose(-1, -2) # (B, n_patches, hidden) = (B, H*W/(16*16), 768)
# 加入位置编码(1, H*W/(16*16), 768)
embeddings = x + self.position_embeddings # (B, H*W/(16*16), 768)
embeddings = self.dropout(embeddings)
return embeddings, features # (B, n_patches, 768); features
这段代码中的
最初的x是 1 / 16 1/16 1/16倍的特征图,然后分别经过:①patch_embeddings(x):改变通道数为768;②flatten(2):合并后两个维度;③transpose(-1, -2):交换后两个维度,目的是将张量改成transformer需要的shape形状;④self.position_embeddings:加入位置编码;⑤self.dropout:防止过拟合。
最后,返回的embeddings会送入Transformer Layer。
到这里类Embeddings执行结束。下面将embeddings传入Encoder,继续1小节。
1.(2)
前向传播forward过程:
def forward(self, input_ids): # (B,3,H,W)
# 将x送入self.embeddings中,实现在1.1节
embedding_output, features = self.embeddings(input_ids) # (B, 1024, 768) # (B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
# 这里将embedding_output传入self.encoder中,实现在1.2小节
encoded, attn_weights = self.encoder(embedding_output) # (B, n_patchs, hidden):(B, 1024, 768)
return encoded, attn_weights, features
1.2. self.encoder()
class Encoder(nn.Module):
def __init__(self, config, vis):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)
for _ in range(config.transformer["num_layers"]): # 12
layer = Block(config, vis)
self.layer.append(copy.deepcopy(layer))
# 这里的hidden_states是上面代码中的embedding_output
def forward(self, hidden_states): # (B, n_patches, 768):(B, 1024, 768)
attn_weights = []
'''
这里的layer_block是Transformer Layer层,共有12层
'''
for layer_block in self.layer:
# 跳转到类Block,实现见1.2.1节
hidden_states, weights = layer_block(hidden_states)
if self.vis:
attn_weights.append(weights)
encoded = self.encoder_norm(hidden_states)
return encoded, attn_weights
1.2.1. class Block()
类class Block是Transformer Layer的实现过程,有12个Transformer Layer,所以要执行12次
class Block(nn.Module):
def __init__(self, config, vis):
super(Block, self).__init__()
self.hidden_size = config.hidden_size
self.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn = Mlp(config)
self.attn = Attention(config, vis)
def forward(self, x):
h = x # (B, n_patchs, hidden):(B, 1024, 768)
x = self.attention_norm(x) # (B, n_patchs, hidden):(B, 1024, 768)
# 下面使用注意力模块,实现见1.2.1.1节
x, weights = self.attn(x) # (B, 1024, 768)
x = x + h
h = x # (B,196,768)
x = self.ffn_norm(x)
x = self.ffn(x)
x = x + h
return x, weights
1.2.1.1. self.attn(x)
类Attention()
class Attention(nn.Module):
def __init__(self, config, vis):
super(Attention, self).__init__()
self.vis = vis
self.num_attention_heads = config.transformer["num_heads"]
self.attention_head_size = int(config.hidden_size / self.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = Linear(config.hidden_size, self.all_head_size)
self.key = Linear(config.hidden_size, self.all_head_size)
self.value = Linear(config.hidden_size, self.all_head_size)
self.out = Linear(config.hidden_size, config.hidden_size)
self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.softmax = Softmax(dim=-1)
def transpose_for_scores(self, x): # (B, 1024, 768)
# 构造新的张量,其形状为x前两维加上(self.num_attention_heads, self.attention_head_size)作为后两维,
# 其形状为(B, n_patchs, self.num_attention_heads, self.attention_head_size)
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size) # (B,1024,12,64)
x = x.view(*new_x_shape) # 将 x 变成new_x_shape的形状: (B,1024,12,64)
return x.permute(0, 2, 1, 3) # (B,12,1024,64)
def forward(self, hidden_states): # (B, n_patchs, hidden):(B, 1024, 768)
# 使用Linear生成q、k、v
mixed_query_layer = self.query(hidden_states) # (B, 1024, 768)
mixed_key_layer = self.key(hidden_states) # (B, 1024, 768)
mixed_value_layer = self.value(hidden_states) # (B, 1024, 768)
# 将q、k、v 变换成需要的形状
query_layer = self.transpose_for_scores(mixed_query_layer) # (B,12,1024,64)
key_layer = self.transpose_for_scores(mixed_key_layer) # (B,12,1024,64)
value_layer = self.transpose_for_scores(mixed_value_layer) # (B,12,1024,64)
# q 点乘 k的转置,记为:q·k'
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))# (B,12,1024,64)matmul(B,12,64,1024)=(B,12,1024,1024)
# q·k'/√d :attention_head_size是注意力机制的维度d
attention_scores = attention_scores / math.sqrt(self.attention_head_size) # (B,12,1024,1024)
# softmax(q·k'/√d)
attention_probs = self.softmax(attention_scores) # (B,12,1024,1024)
# self.vis = False
weights = attention_probs if self.vis else None
# softmax(q·k'/√d) : 这一步猜测是防止过拟合
attention_probs = self.attn_dropout(attention_probs) # (B,12,1024,1024)
# softmax(q·k'/√d)·v , 其中v:(B,12,1024,64)
context_layer = torch.matmul(attention_probs, value_layer) # (B,12,1024,64) #(B,12,1024,1024)matmul(B,12,1024,64)=(B,12,1024,64)
# 至此, 完成Attention(q,k,v) = softmax(q·k'/√d)·v
# 调整shape:(B,12,1024,64)->(B,1024,12,64)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous() # (B,1024,12,64)
# 构造一个新的张量形状(B,1024,768), 将 context_layer 变成其形状
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,) # (B,1024,768)
context_layer = context_layer.view(*new_context_layer_shape) # (B,1024,768)
# 通过一个Linear层和dropout层
attention_output = self.out(context_layer) # (B,1024,768)
attention_output = self.proj_dropout(attention_output) # (B,1024,768)
# 到这, attention_output 为注意力机制的输出, weight为None
return attention_output, weights # (B,1024,768)
# 下面跳转到 1.2.1.小节的 class Block()
1.2.1.(2)
class Block()
只看前向传播过程,该从x = x+h 开始
def forward(self, x):
h = x # (B, n_patchs, hidden):(B, 1024, 768)
x = self.attention_norm(x) # (B, n_patchs, hidden):(B, 1024, 768)
# 下面使用注意力模块,实现见1.2.1.1节
x, weights = self.attn(x) # (B, 1024, 768)
x = x + h # (B, 1024, 768)
h = x # (B, 1024, 768)
# self.ffn_norm是一个LayerNorm层
x = self.ffn_norm(x) # (B, 1024, 768)
# self.ffn = Mlp(), 实现见1.2.1.2小节
x = self.ffn(x)
x = x + h
return x, weights
1.2.1.2. self.ffn(x)
类Mlp
class Mlp(nn.Module):
def __init__(self, config):
super(Mlp, self).__init__()
self.fc1 = Linear(config.hidden_size, config.transformer["mlp_dim"]) # mlp_dim:3072
self.fc2 = Linear(config.transformer["mlp_dim"], config.hidden_size)
self.act_fn = ACT2FN["gelu"]
self.dropout = Dropout(config.transformer["dropout_rate"])
self._init_weights()
def _init_weights(self):
nn.init.xavier_uniform_(self.fc1.weight)
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.normal_(self.fc1.bias, std=1e-6)
nn.init.normal_(self.fc2.bias, std=1e-6)
def forward(self, x): # (B, 1024, 768)
x = self.fc1(x) # (B, 1024, 3072)
x = self.act_fn(x) # (B, 1024, 3072)
x = self.dropout(x) # (B, 1024, 3072)
x = self.fc2(x) # (B, 1024, 768)
x = self.dropout(x) # (B, 1024, 768)
return x
# 到这里, Mlp 的过程完成,下面进入1.2.1小节class Block()
1.2.1.(3)
class Block()
只看前向传播过程,该从第二个x = x+h 开始
def forward(self, x):
h = x # (B, n_patchs, hidden):(B, 1024, 768)
x = self.attention_norm(x) # (B, n_patchs, hidden):(B, 1024, 768)
# 下面使用注意力模块,实现见1.2.1.1节
x, weights = self.attn(x) # (B, 1024, 768)
x = x + h # (B, 1024, 768)
h = x # (B, 1024, 768)
# self.ffn_norm是一个LayerNorm层
x = self.ffn_norm(x) # (B, 1024, 768)
# self.ffn = Mlp(), 实现见1.2.1.2小节
x = self.ffn(x) # (B, 1024, 768)
x = x + h # (B, 1024, 768)
return x, weights # x: (B, 1024, 768) ; weights: None
# 到这 class Block() 的过程结束,下面跳转到 1.2. self.encoder()
1.2.(2) self.encoder()
类Encoder
代码该从if self.vis:开始
class Encoder(nn.Module):
def __init__(self, config, vis):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)
for _ in range(config.transformer["num_layers"]): # 12
layer = Block(config, vis)
self.layer.append(copy.deepcopy(layer))
def forward(self, hidden_states): # (B, n_patch, hidden):(B, 1024, 768)
attn_weights = []
'''
这里的layer_block是Transformer Layer层,共有12层
'''
# 这里self.layer有12层,即循环要走12次class Block()
for layer_block in self.layer:
hidden_states, weights = layer_block(hidden_states) # (B,1024,768)
if self.vis: # False
attn_weights.append(weights)
# LayerNorm层,
encoded = self.encoder_norm(hidden_states) # (B,1024,768)
return encoded, attn_weights # encoded:(B,1024,768); attn_weights:None
# 到这 class Encoder() 的过程结束,下面跳转到 1. self.transformer()
1.(3)
类Transformer()
代码该从return encoded, attn_weights, features开始
class Transformer(nn.Module):
def __init__(self, config, img_size, vis):
super(Transformer, self).__init__()
self.embeddings = Embeddings(config, img_size=img_size)
self.encoder = Encoder(config, vis)
def forward(self, input_ids): # (B,3,H,W)
# 将x送入self.embeddings中,实现在1.1节
embedding_output, features = self.embeddings(input_ids) # (B, 196, 768) # (B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
encoded, attn_weights = self.encoder(embedding_output) # (B, n_patchs, hidden)
# 返回 encoded:(B,1024,768); features: (B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
return encoded, attn_weights, features
# 到这 class Transformer() 的过程结束,下面跳转到 一. class VisionTransformer
一.(2)
类VisionTransformer()
代码该从x = self.decoder(x, features)开始
class VisionTransformer(nn.Module):
def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.zero_head = zero_head
self.classifier = config.classifier
self.transformer = Transformer(config, img_size, vis)
self.decoder = DecoderCup(config)
self.segmentation_head = SegmentationHead(
in_channels=config['decoder_channels'][-1],
out_channels=config['n_classes'],
kernel_size=3,
)
self.config = config
def forward(self, x):
if x.size()[1] == 1: # 如果图片是灰度图就在其通道方向进行复制从1维转成3维(比如CT图像就是灰度图)
x = x.repeat(1,3,1,1) # (B,3,H,W)
# 然后将x送入self.trasnformer中,实现在1节
x, attn_weights, features = self.transformer(x)
# (B, n_patchs, hidden):(B,1024,768) # features:(B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
# x: (B,1024,768); features: (B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
# 将x,features送入DecoderCup(), 实现在2小节
x = self.decoder(x, features)
logits = self.segmentation_head(x)
return logits
2. self.decoder()
类Decoder()
class DecoderCup(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
head_channels = 512
self.conv_more = Conv2dReLU(
config.hidden_size,
head_channels,
kernel_size=3,
padding=1,
use_batchnorm=True,
)
decoder_channels = config.decoder_channels
in_channels = [head_channels] + list(decoder_channels[:-1])
out_channels = decoder_channels
if self.config.n_skip != 0:
skip_channels = self.config.skip_channels
for i in range(4-self.config.n_skip): # re-select the skip channels according to n_skip
skip_channels[3-i]=0 # skip_channels=[512,256,64,0]
else:
skip_channels=[0,0,0,0]
blocks = [
DecoderBlock(in_ch, out_ch, sk_ch) for in_ch, out_ch, sk_ch in zip(in_channels, out_channels, skip_channels)
]
self.blocks = nn.ModuleList(blocks)
def forward(self, hidden_states, features=None): # (B, n_patchs, hidden):(B,1024,768) # features:(B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
# reshape from (B, n_patchs, hidden) to (B, h, w, hidden)
B, n_patch, hidden = hidden_states.size()
h, w = int(np.sqrt(n_patch)), int(np.sqrt(n_patch)) # 32,32
x = hidden_states.permute(0, 2, 1) # (B,768,1024)
x = x.contiguous().view(B, hidden, h, w) # (B,768,32,32)
# 将channel变成512, 对应前面三个特征图的通道数512,256,64
# 通道数256和64在后面会体现到
x = self.conv_more(x) # (B,512,32,32) # features:(B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
'''
(1)self.block共有4层, 对应上面对DecoderBlock()的定义,
其中zip(in_channels, out_channels, skip_channels)这里面的参数有
4 组:(512, 256, 512); (256, 128, 256); (128, 64, 64); (64, 16, 0)。
(2)skip为features的三个特征图: (B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)。
(3)Decoder_Block()作用: 先对 x 进行上采样,然后将 x 与 skip 进行cat, 再对cat后
的x进行卷积使其channel变成256, 128, 64。
但是当i=3时,不在进行skip与x拼接(cat),Decoder_Block()的作用:对x的channel降维到16,
最后输出的x:(B,16,H,W)=(B,16,512,512)
'''
for i, decoder_block in enumerate(self.blocks): # (512, 256, 512); (256, 128, 256); (128, 64, 64); (64, 16, 0)
if features is not None:
skip = features[i] if (i < self.config.n_skip) else None
else:
skip = None
# 将 x 和 skip 送如decoder_block,实现见2.1小节
x = decoder_block(x, skip=skip)
return x # x:(B,16,H,W)=(B,16,512,512)
2.1. decoder_block(x, skip)
类DecoderBlock()
class DecoderBlock(nn.Module):
def __init__(
self,
in_channels,
out_channels,
skip_channels=0,
use_batchnorm=True,
):
super().__init__()
self.conv1 = Conv2dReLU(
in_channels + skip_channels,
out_channels,
kernel_size=3,
padding=1,
use_batchnorm=use_batchnorm,
)
self.conv2 = Conv2dReLU(
out_channels,
out_channels,
kernel_size=3,
padding=1,
use_batchnorm=use_batchnorm,
)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x, skip=None): # (B,512,32,32); (B,512,64,64)
# 先对x进行上采样,然后将x与skip进行cat
x = self.up(x) # (B,512,64,64)
if skip is not None:
x = torch.cat([x, skip], dim=1) # (B,1024,64,64)
x = self.conv1(x) # (B,256,64,64)
x = self.conv2(x) # (B,256,64,64)
return x
'''
上面只是i=0的时候实现流程
这个类根据i的取值会执行4次,0、1、2的时候 x 会和 skip 及进行cat操作,4的时候skip为None,只
对 x 进行卷积操作,最后x:(B,16,512,512),该特征图是整个模型最后的特征图。
'''
执行完后会跳到2.小节最后一行return x ,然后从一.节类VisionTransformer中的logits = self.segmentation_head(x)开始。
一.(3)
类VisionTransformer()
代码该从logits = self.segmentation_head(x)开始
为了简洁,只看前向传播:
def forward(self, x):
if x.size()[1] == 1:
x = x.repeat(1,3,1,1) # (B,3,H,W) = (B,3,512,512)
x, attn_weights, features = self.transformer(x) # (B, n_patchs, hidden):(B,1024,768) # features:(B,512,H/8,W/8);(B,256,H/4,W/4);(B,64,H/2,W/2)
x = self.decoder(x, features) # (B,16,H,W):(B,16,512,512)
# 从这跳转到3.小节的class SegmentationHead()
logits = self.segmentation_head(x) # (B,2,H,W):(B,2,512,512)
return logits
3. self.segmentation_head(x)
类SegmentationHead()
class SegmentationHead(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, upsampling=1):
# 分割头:将 out_channels 设置成n_classes, 这里 out_channels=2
conv2d = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=kernel_size // 2)
# upsampling=1 不进行上采样
upsampling = nn.UpsamplingBilinear2d(scale_factor=upsampling) if upsampling > 1 else nn.Identity()
super().__init__(conv2d, upsampling)
该段代码执行完后,跳转到一.小节中的return logits,即返回最后的分类特征图,至此模型完毕。
附录. 模型图
最后附上模型图:文章来源:https://www.toymoban.com/news/detail-761647.html
 文章来源地址https://www.toymoban.com/news/detail-761647.html
文章来源地址https://www.toymoban.com/news/detail-761647.html
到了这里,关于【代码复现】TransUNet代码实现流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!