报错:
circuit_breaking_exception[[parent] Data too large, data for [<transport_request>] would be [12318476937/11.2gb], which is larger than the limit of [12237372108/12.2gb], real usage: [12318456248/11.2gb]
原因:
(1)表面原因是在ES中大量内存被占用,GC无法对heap进行垃圾回收,导致node内存用量超出limit限制。
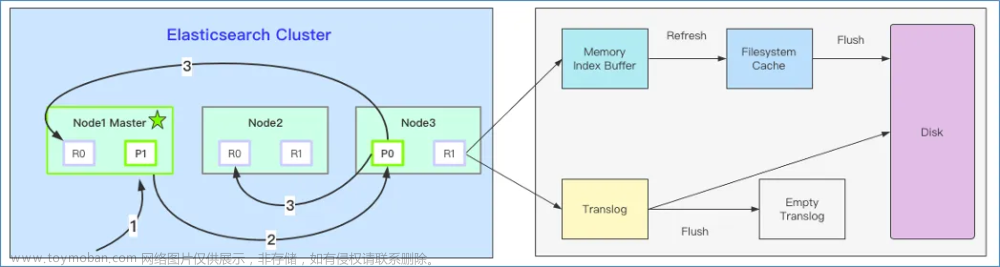
(2)根本原因是ES设置有问题,默认配置是JVM内存使用达到75%的时候进行full GC,默认配置总熔断器indices.breaker.total.use_real_memory 它的值直接影响JVM堆内存分配的大小, 1、值为 true, indices.breaker.total.limit 为堆大小的 95%。 2、值为 false,indices.breaker.total.limit 为堆大小的70%
如果在还未到ES的full GC的时候,已经达到ES总熔断器的上限了,那么此时ES的内存一直没有回收,不断插入新数据,那么就会产生报错。
解决:1、在elasticsearch.yml添加配置:
indices.breaker.total.use_real_memory:false
indices.breaker.total.limit: 70%
2、修改ES的jvm.options:文章来源:https://www.toymoban.com/news/detail-761677.html
-Xms10g
-Xmx10g
## GC configuration
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=60
-XX:+UseCMSInitiatingOccupancyOnly
假如JVM的内存设置的是10GB,经过以上配置后,熔断器的内存范围是7GB,GC的内存范围是6GB,那么在未达到熔断器的最高标准时,JVM会进行full GC,那么就不会报错了。或者就无脑加大ES的内存也是可以的,毕竟内存大了,可能永远就达不到熔断了。文章来源地址https://www.toymoban.com/news/detail-761677.html
到了这里,关于ES写入数据时:circuit_breaking_exception[[parent] Data too large的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!