前言
同志们,我很高兴的告诉大家我们有了一个比langchain更好用的构建AI agent的工具。众所周知,langchain主要就是一堆字符串提示模板构成的,这导致,当我们的模型性能不够强大(比如说gpt3.5)时会因为上下文的干扰而产生幻觉,从而无法完成我们所需要让其完成的任务(之前想让它自己跑代码,结果加了点限定条件字符串就匹配不上了/(ㄒoㄒ)/~~)。而Autogen就没这种问题,而且Autogen内部还有一些对LLM记忆的一些优化,构建AI agent的时候简单快捷准确性高。接下来,我将和大家一起学习,如何使用Autogen,以及如何将代理嵌入到自己的应用程序中,让我们开始吧!
环境:conda 4.5.11、python 3.9.12、Windows 11、VScode
一、配置网络环境
可以直连openai api的,或者使用其它国内可以访问的api的,可以忽略此步骤
# 在引入openai api 对环境变量进行初始化
os.environ["OPENAI_API_BASE"] = "这里填你的代理服务器地址/v1"
os.environ["OPENAI_API_PREFIX"] = "这里填你的代理服务器地址"
如何免费获取代理服务请参考这里:
国内开发者如何最小成本调用openai的接口? - 掘金
二、安装Autogen
和其它python库一样,pip install 即可
pip install openai
pip install pyautogen
三、创建配置列表
在autogen的github上有一个模板
[
{
"model": "gpt-4",
"api_key": "<your OpenAI API key here>"
},
{
"model": "gpt-4",
"api_key": "<your Azure OpenAI API key here>",
"api_base": "<your Azure OpenAI API base here>",
"api_type": "azure",
"api_version": "2023-07-01-preview"
},
{
"model": "gpt-3.5-turbo",
"api_key": "<your Azure OpenAI API key here>",
"api_base": "<your Azure OpenAI API base here>",
"api_type": "azure",
"api_version": "2023-07-01-preview"
}
]
你选择你需要的那个,再把其它没用的删了就行。例如说:
[
{
"model": "gpt-3.5-turbo",
"api_key": "<your OpenAI API key here>"
}
]
修改完成之后保存为json文件,记着文件名和路径。
再这之后我们就可以把配置文件引入到我们的py文件中了
#引入autogen的配置文件解析器
from autogen import config_list_from_json
#获取配置文件
#env_or_file这里填写你的配置文件的名字
#file_location这里填写你的配置文件的路径
config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST.json",file_location="D:\\CodeFiles\\CondaProgram\\MieruData\\test")
当然,你也可以直接填写你的配置到config_list 中,问题不大。
config_list = [{'model': 'gpt-3.5-turbo', 'api_key': '<your OpenAI API key here>'}]
四、创建第一个autogen程序
-
首先,引入并实例化出用户代理对象和助手代理对象
from autogen import AssistantAgent, UserProxyAgent assistant = AssistantAgent( name="Monika", llm_config={ "seed": 42, # seed for caching and reproducibility "config_list": config_list, # a list of OpenAI API configurations "temperature": 0, # temperature for sampling }, # configuration for autogen's enhanced inference API which is compatible with OpenAI API ) user_proxy = UserProxyAgent( name="user_proxy", max_consecutive_auto_reply=2, is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"), code_execution_config={ "work_dir": "coding", "use_docker": True, # set to True or image name like "python:3" to use docker }, llm_config={"config_list": config_list} ) -
使用initiate_chat函数进行推理
user_proxy.initiate_chat( assistant, message="""尝试对数据进行分析。【文件地址:D:\CodeFiles\CondaProgram\MieruData\data\inputData\Mytest.csv】""" ,clear_history = True ) -
完整代码
import os os.environ["OPENAI_API_BASE"] = "https://transfer-4t4.pages.dev/v1" os.environ["OPENAI_API_PREFIX"] = "https://transfer-4t4.pages.dev" from autogen import AssistantAgent, UserProxyAgent, config_list_from_json config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST.json",file_location="D:\\CodeFiles\\CondaProgram\\MieruData\\test") assistant = AssistantAgent( name="Monika", llm_config={ "seed": 42, # seed for caching and reproducibility "config_list": config_list, # a list of OpenAI API configurations "temperature": 0, # temperature for sampling }, # configuration for autogen's enhanced inference API which is compatible with OpenAI API ) user_proxy = UserProxyAgent( name="user_proxy", max_consecutive_auto_reply=2, is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"), code_execution_config={ "work_dir": "coding", "use_docker": True, # set to True or image name like "python:3" to use docker }, llm_config={"config_list": config_list} ) user_proxy.initiate_chat( assistant, message="""尝试对数据进行分析。【文件地址:D:\CodeFiles\CondaProgram\MieruData\data\inputData\Mytest.csv】""" ,clear_history = True ) -
运行结果如下

当你键入回车的时候,你的user_proxy 会进行自动回复,有代码的时候会运行代码。如


可以看到我们现在存在两个问题- 输入只能在终端进行,如果我们需要把它接入到应用程序中时,我们的应用程序是输入不进去的。
- 代理在自动执行代码的时候会把pip的过程当作python代码去执行,导致我们的对话一直纠缠在安装环境当中。
之后,我们来解决问题1;对于问题2,你把结果返回给它之后,它接下来就会换成sh脚本了。
五、获取对话记录
我们的代理要接入程序的话,得先要获取到代理在说什么对吧。
在代理类里面有两个可以获取对话记录的函数。一个是chat_messages一个是last_message
-
我们先用chat_messages试试
#在原来的代码后面加上这个 messge = user_proxy.chat_messages() print(f"message:{messge}")然而结果看来是不行(其实我们也用不上这个)

-
我们再用last_message试试
message = user_proxy.last_message() print(f"message:{message}")这次没问题了

-
创造一个新的获取所有对话记录的函数
这个看个人需求需不需要,说实话就我们接下来的要构建的应用来说是用不上这个的。
ctrl+左键,点击last_message函数,查看源码。

可以发现chat_messages是直接返回 ._oai_messages 属性的,而last_message则多出了一个解析的步骤。这可能就是chat_messages报错的原因的所在。
我们依葫芦画瓢,在后面再添加一个函数all_message,内容如下
def all_message(self, agent: Optional[Agent] = None) -> Dict: """我发现chat_message不能用,但last可以。 我来把last_massage改改,代替chat_message """ if agent is None: n_conversations = len(self._oai_messages) if n_conversations == 0: return None if n_conversations == 1: for conversation in self._oai_messages.values(): return conversation raise ValueError("More than one conversation is found. Please specify the sender to get the last message.")添加后如图所示

接下来,让我们看看它的效果如何
# 我们定义的新的获取历史信息的函数 message = user_proxy.all_message() print(f"message:{message}")
可以看到我们已经成功的获取到了历史信息。
六、由我们自行控制的每一步
解决问题:输入只能在终端进行
先给代码(有时间的话我再说一下为什么这样做)
#用以下内容替换initiate_chat
while True:
text = input("请输入:")
assistant.reset_consecutive_auto_reply_counter(user_proxy)
user_proxy.reset_consecutive_auto_reply_counter(assistant)
assistant.reply_at_receive[user_proxy] = True
user_proxy.send(message=text,recipient=assistant,request_reply=True)
lastmsg = user_proxy.last_message()
print(lastmsg)
结果如图
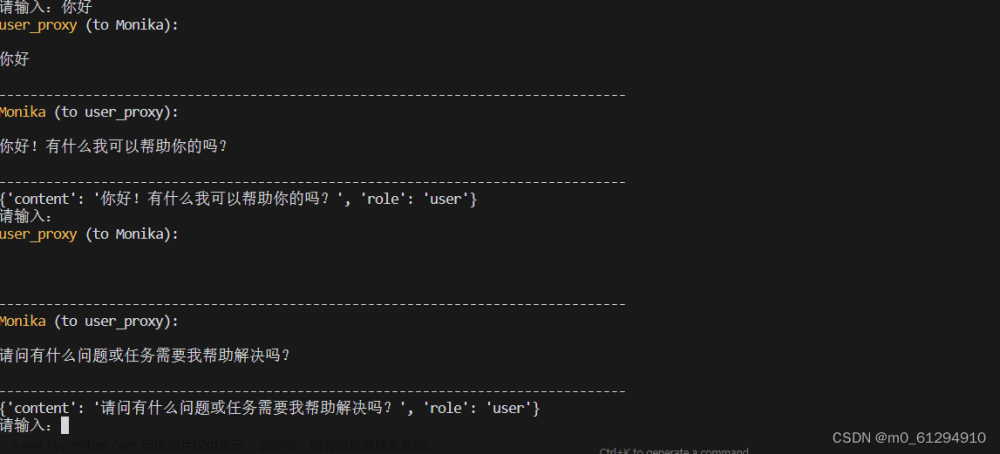
我们现在已经可以控制每一步的输入了,并且每一步都能捕获到assistant的回复。
现在还有一个缺点,就是我们的user_proxy执行不了代码了。
我们再次进行改进:
while True:
text = input("请输入:")
if text == "自动填充代码执行结果":
text = codeAnswer
assistant.reset_consecutive_auto_reply_counter(user_proxy)
user_proxy.reset_consecutive_auto_reply_counter(assistant)
assistant.reply_at_receive[user_proxy] = True
user_proxy.send(message=text,recipient=assistant,request_reply=True)
lastmsg = user_proxy.last_message()
# 提取代码块
code = extract_code(lastmsg['content'])
codeAnswer = ""
# 它可能一次提供多个代码块,我们试出它的每个结果
for Acode in code:
if Acode[0] == "python":
# 当代码类型是python时运行代码
# logs_all是代码的执行结果
logs_all = user_proxy.execute_code_blocks([Acode])
# 把答案拼起来
codeAnswer += logs_all[1] + "\n"
现在就可以了。
看看效果

安装库的那一步不管的话,我们的目的其实已经完成了。
七、把AI嵌入到应用中
在这里我用我的大作业Demo「可视化数据分析平台」为例。
后端框架:Flask
大家可以用自己熟悉框架来进行。
# 把对话过程封装成函数
def AIAgent(text,assistant,user_proxy,codeAnswer):
if text == "自动代码执行":
text = codeAnswer
#这个会重置对话次数,给它注释掉
#assistant.reset_consecutive_auto_reply_counter(user_proxy)
user_proxy.reset_consecutive_auto_reply_counter(assistant)
#assistant.reply_at_receive[user_proxy] = True
user_proxy.send(message=text,recipient=assistant,request_reply=True)
lastmsg = user_proxy.last_message()
# 提取代码块
code = extract_code(lastmsg['content'])
codeAnswer = ""
# 它可能一次提供多个代码块,我们试出它的每个结果
for Acode in code:
if Acode[0] == "python":
# 当代码类型是python时运行代码
# logs_all是代码的执行结果
logs_all = user_proxy.execute_code_blocks([Acode])
# 把答案拼起来
codeAnswer += logs_all[1] + "\n"
return lastmsg['content'],codeAnswer
@app.route('/chat', methods=['POST'])
def chat():
# 从请求中获取消息
message = request.form.get('message')
full_path = session['full_path']
if "数据地址" not in message:
message = f"{message} \n【数据地址:{full_path}】"
if "自动代码执行" in message:
message = "自动代码执行"
if "图" in message or "可视化" in message:
hack = "如果要绘制图像的话,请把图像保存在/static/img/createdImg/created.png。并且打印'图像已绘制'到控制台"
message = f"{message} \n 【{hack}】"
if session['codeAnswer'] != None:
codeAnswer = str(session['codeAnswer'])
response,codeAnswer = AIAgent(text=message,assistant=Globalassistant,user_proxy=Globaluser_proxy,codeAnswer=codeAnswer)
else:
response,codeAnswer = AIAgent(text=message,assistant=Globalassistant,user_proxy=Globaluser_proxy,codeAnswer="")
session['codeAnswer'] = codeAnswer
show_image = '图像已绘制' in response
# 返回一个 JSON 响应
return jsonify({'response': response, 'show_image': show_image})
结果:

总结
这个框架我也不是很熟悉,我也是摸石头过河的,如有错误请毫不吝啬的指出,我也希望我能在错误中进步。
我构思的项目主要是用它来执行代码的,而网上根本找不到这方面的教程,所以我想自己写一篇。
我的环境好像与docker不兼容,无法在docker环境下运行代码。这个可能会影响sh代码的运行。
项目是一个软件工程的大作业,但我们的评分标准是主要是用例图、文档、PPT这些,Demo主要是用来证明项目是可行的。所以我做的很粗糙,很多东西都不能用,请见谅。文章来源:https://www.toymoban.com/news/detail-762120.html
项目地址:https://github.com/mizu1/MieruData 文章来源地址https://www.toymoban.com/news/detail-762120.html
文章来源地址https://www.toymoban.com/news/detail-762120.html
到了这里,关于把通过autogen构建的AI agent接入到自己的应用程序中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








