作者:禅与计算机程序设计艺术
1.简介
概述
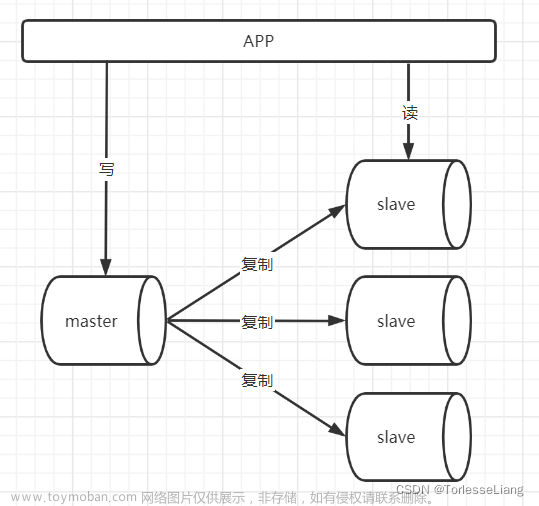
随着互联网的蓬勃发展,用户数量和社交活动呈爆炸式增长。因此,基于互联网的新型应用正在崭露头角,例如新浪微博、微信朋友圈、QQ空间、知乎、搜狐新闻等。这些网站拥有庞大的用户群体,每天产生海量的数据,极大的 challenges 要如何快速准确地处理和分析大数据并将其用于信息发现,用户行为分析,以及推荐系统的设计、开发和部署?这些应用都需要能够存储、检索、分析海量的、结构化的非结构化数据。传统的关系型数据库在处理海量数据时效率低下,无法满足需求。而分布式数据库则可以有效解决这个问题。分布式数据库允许多台服务器共同存储、检索和管理海量的数据,并且提供高可用性、容错性、扩展性等优点。其中,Apache HBase 是一个开源的分布式 NoSQL 数据库系统。本文主要阐述了 HBase 的工作原理、相关概念、特性、适用场景及其在微博搜索引擎中的应用。
发展历史
Apache Hadoop 是 Apache 基金会的开源项目之一,它是一个框架,提供了一个分布式计算模型。它的核心是一个分布式文件系统(HDFS),支持流式读取和写入,具备可靠的容错能力;MapReduce 模型用于对大数据进行并行计算;YARN 技术则负责资源调度和任务监控。文章来源:https://www.toymoban.com/news/detail-762232.html
Hadoop 以其高效的数据处理能力和弹性扩展性著称,但同时也存在一些问题。首先,由于 MapReduce 模型的限制,在处理海量数据的同时不能做实时的查询。其次,数据不一致的问题。当多个节点修改相同的数据导致数据不一致时,很难排查错误。第三,Hadoop 中 MapReduce 只能处理结构化数据,对于半结构化或者非结构化的数据,比如文本或者 JSON 数据文章来源地址https://www.toymoban.com/news/detail-762232.html
到了这里,关于分布式数据库系统:如何利用HBase构建微博搜索引擎?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!