遗传算法
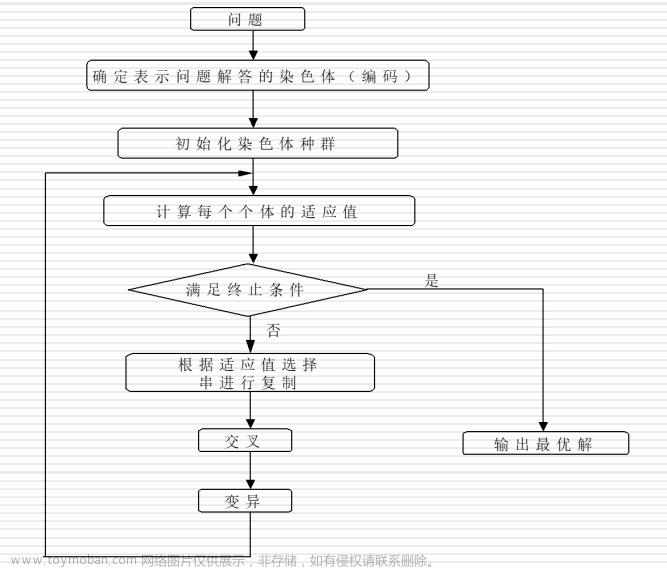
遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。
问题描述
路径规划问题是物流领域的常见问题。由于问题的复杂性较大,用常规的动态规划等方法常常难以满足算力需求。因此可以利用遗传算法等启发式算法,不追求最优,而是转而寻求满意解。
问题如下:现有13个工厂以及一个配送中心,地址已知,各工厂的货物需求量已知。配送中心共有三台车辆,每台车辆的载货量有限。每个车辆每次出发会造成固定成本C1,每行驶一公里会造成C2的成本。问如何分配配送任务使得满足工厂需求的同时成本最低。
解决方案
若是列举出所有可能的方案,即使不考虑载重量只考虑最短路劲遍历所有工厂,即将此问题看做旅行商问题,也会有13!次方案,显然不现实。
编码
考虑遗传算法,将车辆路径编码成染色体,一种配送方案就是一个染色体,具体的编码过程可参考遗传算法详解。路径规划问题并不适合采用二进制编码(后面会说明原因),因为复杂的配送路线不适合用简单的0,1编码来实现。在这里我采用的是形如[0, 4, 2, 0, 8, 0, 6, 0, 11, 0, 10, 9, 0, 13, 0, 5, 12, 0, 1, 0, 3, 0, 7, 0]的编码形式,[0]代表配送中心,[0,4]代表配送中心到工厂四配送的过程,[0,4,2,0]是一次完整的子路径配送,代表车辆从配送中心出发,前往四号工厂配送再前往二号工厂配送最后回到配送中心的过程。
由于有运载量的限制,车辆无法一次性为所有工厂配送,因此需要在染色体中穿插多个0元素,表示车辆的补货过程。具体穿插多少个0元素参照公式K = SUM(require)/carry。K为最少需要的配送次数,require为工厂的需求矩阵,carry为车辆的运载量。最少满足子路径个数为K个,才有可能完成配送任务。然而通常子路径个数要大于K,例如工厂2的需求量为60,工厂4的需求量为70,carry = 120,车辆为工厂2配送完成后,无法再为工厂4配送,而先为工厂4配送60个单位的货物再回头补货再为工厂4配送余下的10个单位货物只会造成无意义的浪费(除非某个工厂的需求量大于carry则需要多次配送)。同时,染色体编码的开头和结尾元素必须为0,表示车辆从配送中心出发最后回到配送中心的过程。
我采用的方法是先生成1-13的全排列,再往里面不相邻的位置插入0的方法。先随机生成200个染色体:
start_m = 200 # 初始种群个数
local = [] # 送货地点编号
for i in range(n - 1):
local.append(i + 1)
ans = [] # 初始种群
for _ in range(start_m):
res = [0] # 随机解res
c = n - 1 # 除配送中心外的点个数
local = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
while c > 0:
a = random.randint(1, c)
res.append(local[a - 1])
local.remove(local[a - 1])
c -= 1
if res not in ans:
res.append(0)
x = 0
while x < k:
len_res = len(res)
b = random.randint(1, len_res - 2)
if res[b] != 0 and res[b - 1] != 0:
res.insert(b, 0)
x += 1
ans.append(res)在这里我采用了K = SUM(require)/carry + 3,这个数字可以自行调整,过大或造成运力的浪费,过小则可能超出运载量的限制,理论上来说,越接近运载量极限的方案越是能够节省成本。
合法性分析
我们已经有了众多随机生成的染色体,然而这些染色体可能会超出运载量的限制,因为需要先判断每一个染色体是否合法。
#检查合法性
def Ture(lst):
cur_carry = carry #现有载货量
for i in range(len(lst)-1):
if lst[i] == 0:
cur_carry = carry #补货
else:
cur_carry -= req[lst[i]-1] #现有载货量减去工厂需求
if cur_carry < 0: #若载货量无法满足工厂需求则返回False
return False
return True适应度分析
遗传算法是一个自然选择的过程,更能适应环境的个体存活的几率更大。因此,我们要先判断每个个体对环境的适应度。
#适应度函数
def Cost(lst):
D = 0 #总行驶里程
for i in range(len(lst)-1):
D += d[lst[i]][lst[i+1]]
cost = (k + 1) * c1 + D * c2 #总成本
return cost用个体耗费的总成本表示它的适应度,总成本等于出发次数K乘C1再加上总行驶里程D乘每公里耗费的成本C2。
至于总里程数D的计算,需要实现给出各个工厂和配送中心两两之间的距离:
#两点距离函数:
def dij(i,j):
D = round(((s[i][0]-s[j][0])**2 + (s[i][1]-s[j][1])**2)**0.5)
if D != 0:
return D
else:
return 1000
#距离矩阵d:
d = [[0]*n for _ in range(n)]
for i in range(n):
for j in range(n):
d[i][j] = dij(i,j)s为配送中心和各工厂的坐标列表。
我们已经知道了每一种个体耗费的成本,现在要计算它们的适应度,方便下一步的择优而选。
#最小值适应度函数
def get_Mincost(pop):
pop_ture = []
for i in pop:
if Ture(i):
pop_ture.append(i)
fitness = []
for i in pop_ture:
fitness.append(Cost(i))
# print("最优配送路线为:",pop_ture[fitness.index(min(fitness))])
# print("花费成本为:",min(fitness))
a = max(fitness)
for i in range(len(fitness)):
fitness[i] = a - fitness[i] + 1
p = []
for i in fitness:
p.append(i / sum(fitness))
return (pop_ture,p,fitness)这段代码要找到耗费成本最高的那一个个体,由于遗传算法中的一个重要特性是无论适应度高低都有存活的可能,因此我们将耗费成本最高的个体的适应度设置为1,其他所有个体的适应度表示为fitness[i] = maxcost - cost[i] + 1
最终返回三个参数,pop_ture为所有合法染色体构成的矩阵,p为每一个染色体被选择的概率矩阵,fitness为所有染色体的适应度矩阵。p的计算采用轮盘赌算法,具体计算可参考轮盘赌算法原理。
选择
遗传算法的物竞天择需要我们在每一次迭代中选择最优秀的一批个体参与下一轮的迭代。刚刚提到的染色体被选择的概率矩阵p中,适应度越大的个体,其被选择的概率越大,但并不是说适应度最低的个体就不可能被选择。我在经过合法性检验的个体中,选择了适应度前百分之五十(这个也可以自己调试)的个体返回到new_pop中。
#自然选择函数(轮盘赌),选取适应值最高的前百分之五十的解
def select(p,pop):
idx = np.random.choice(np.arange(len(p)),size=len(p)//2,replace=False,p = p)
new_pop = []
for i in idx:
new_pop.append(pop[i])
return new_pop交叉和变异
现在我们已经得到了目前为止最优秀的一半个体,接下里我们要让它们繁衍子代,从而衍生出更加优秀的子染色体。
我们首先遍历每一个父染色体,先让子染色体继承父染色体,再随机选取一个染色体作为母染色体,再随机选取一个交叉点作为交叉的索引,使得交叉部分之外的染色体为父染色体,交叉点部分之内的染色体替换为母染色体。
刚刚提到路径规划问题不适合用简单的二进制编码的原因在于,普通的交叉非常容易造成子染色体不合法的情况,也就是子染色体不能满足运载量限制,不能满足对每个工厂遍历且仅遍历一次的需求,因此,在这里对传统的交叉过程进行一定的改进。
step1:若随机生成的交叉点在子染色体中的前后两个位置都为0,那么可以看作一个子路径的交换,可以直接交叉
step2:若不满足上一条,即交叉位外侧两端的父代基因不为0的话,则将交叉点左移,直到移动到左交叉位的左端基因为0时停止,以左交叉位为起点,继续向右移动右交叉位,直到右交叉位的右端基因为0时停止。这就保证了父代染色体都用一条进行交叉。
step3:经过前两条的调整,子代中仍然会出现访问同一个工厂两次的情况,需要对子代进行去重操作,在子代中选择那些具有重复情况的自然数,如果该自然数并非在交叉位之内的话,则将其替换为0
step4:经过前三个步骤,子代已经不会出现重复情况,然而可能会出现缺少遍历某几个工厂的可能,因此在这里,我们需要先找到子代缺失的工厂序号,并在子代染色体中为0的位置补齐这些工厂序号。补余的操作分为两步,第一步,优先找那些前端或者后端为0且自身为0的位置进行插入,这样可以最大化避免不合法的情况;第二步,若第一步未能完全补齐,则不考虑前端后端情况,直接在0的位置插入剩余的工厂序号。
#交叉函数:
def crossover_and_mutation(pop):
new_pop = []
for father in pop: #遍历种群中的每一个个体,将该个体作为父亲
child = father #孩子先得到父亲的全部基因
if np.random.rand() < CROSSOVER_RATE: #交叉不是必然发生的,而是以一定的概率发生
mother = pop[np.random.randint(len(pop))] #在种群中选择另一个个体,并将该个体作为母亲
cross_point = np.random.randint(low=1,high=len(pop[0])-1) #随机生成交叉点(交叉点不为第一个和最后一个否则交叉无意义)
#step1:合法交叉
if child[cross_point-1] == 0 and child[cross_point+1]==0: #若交叉点前后两个元素都为0
child[cross_point] = mother[cross_point]
cross_point_right = cross_point #直接交叉
else:
while child[cross_point-1] != 0: #直到交叉点左端为0
cross_point -= 1 #交叉点左移
cross_point_right = cross_point+1 #交叉部分右端点
while child[cross_point_right+1] != 0: #直到交叉部分右端也为0
cross_point_right += 1 #交叉部分右端点右移直到交叉部分两端皆为0
child[cross_point:cross_point_right+1] = mother[cross_point:cross_point_right+1] #交叉
mutation(child)
#step2:去重
hash = {} #统计各站点出现次数
for i,x in enumerate(child):
if x != 0:
if x not in hash:
hash[x] = 1
else:
hash[x] += 1
if hash[x] > 1:
if i < cross_point or i > cross_point_right: #去掉交叉部分之外的重复点
child[i] = 0
#step3:补余
lst = [] #存放没有遍历到的站点索引
for i in range(1,len(req)+1): #总共有len(req)个站点
if i not in child:
lst.append(i)
for i,x in enumerate(child): #补齐缺失的站点
if (i < cross_point or i > cross_point_right) and i != 0 and i != len(child)-1 and x == 0 : #在交叉部分之外进行补齐
if (child[i-1] == 0 or child[i+1] == 0) and len(lst) > 0: #尽可能让站点分散插入
child[i] = lst[0]
lst.remove(lst[0])
if len(lst) > 0: #若无剩余优质空间可以插入,则择近补齐
for i, x in enumerate(child): # 补齐缺失的站点
if (i < cross_point or i > cross_point_right) and i != 0 and i != len(child) - 1 and x == 0:
if len(lst) > 0:
child[i] = lst[0]
lst.remove(lst[0])
if Ture(child): #检查子代是否合法
new_pop.append(child)
return new_pop经过极其极其极其复杂的维护后,子代终于交叉完成了,在这里我设置交叉概率Crossover_Rate = 0.6,也就是说不是所有的父代都要进行交叉,交叉是随机发生的。
另外,变异过程发生在子代交叉之后,维护之前。具体的,随机找到子染色体中的一个非0点,将这个点的元素随机替换成1-13个工厂序号的任意一个序号。变异的目的是为了防止出现局部最优解,所以一次变异会为这个子代带来巨大的适应度改变,这个改变可能是更好的也可能是更坏。
在这里我设置了变异概率Mutation_Rate = 0.05,一般不需要太高。
#变异函数:
def mutation(child):
if np.random.rand() < MUTATION_RATE: #以MUTATION_RATE的概率进行变异
mutate_point = np.random.randint(low=1,high=len(pop[0])-1) #随机产生一个实数,代表要变异基因的位置
child[mutate_point] = np.random.randint(low=1,high=len(req)-1) #变异后的值为随机一个站点
迭代
以上终于完成了核心的步骤,接下来,不断迭代并更新种群,最终找到满意解指日可待!
#迭代
N = 100 #迭代N次
fitness = []
jiyin = []
pop = select(get_Mincost(ans)[1],get_Mincost(ans)[0])
new_pop = crossover_and_mutation(select(get_Mincost(ans)[1],get_Mincost(ans)[0]))
for i in new_pop:
pop.append(i)
jiyin.append(get_Mincost(pop)[0][np.argmin(get_Mincost(pop)[2])])def print_info(pop):
cost = get_Mincost(pop)[2]
min_cost_index = np.argmax(cost)
print("最低成本为:",Cost(get_Mincost(pop)[0][min_cost_index]))
print("最优的基因型为:",get_Mincost(pop)[0][min_cost_index])小结
至此,遗传算法能够较好的实现路径规划问题了,本人接触遗传算法时间不长,还有很多需要学习和改进的地方,欢迎各位提出宝贵意见,拜了兄弟们!文章来源:https://www.toymoban.com/news/detail-762736.html
最后附上完整代码方便cp。文章来源地址https://www.toymoban.com/news/detail-762736.html
import random
import numpy as np
s = [[393,13142],[632,13008],[586,12917],[390,12934],[648,13052],[632,12848],[667,13361],[382,12961],[378,13267],
[647,13016],[639,13237],[600,13574],[632,13123],[422,13046]] #坐标列表
n = len(s) #点个数
req = [110.0,60.0,55.0,55.0,60.0,100.0,60.0,70.0,60.0,50.0,50.0,60.0,50.0] #需求矩阵
c1 = 50 #出发成本
c2 = 5 #行驶成本,每公里耗费C2
carry = 120 #运载量
k = sum(req)//carry + 2 #车辆需要运行的次数
CROSSOVER_RATE = 0.6 #交叉概率
MUTATION_RATE = 0.05 #变异概率
#两点距离函数:
def dij(i,j):
D = round(((s[i][0]-s[j][0])**2 + (s[i][1]-s[j][1])**2)**0.5)
if D != 0:
return D
else:
return 1000
#距离矩阵d:
d = [[0]*n for _ in range(n)]
for i in range(n):
for j in range(n):
d[i][j] = dij(i,j)
#适应度函数
def Cost(lst):
D = 0
for i in range(len(lst)-1):
D += d[lst[i]][lst[i+1]]
cost = (k + 1) * c1 + D * c2
return cost
#检查合法性
def Ture(lst):
cur_carry = carry
for i in range(len(lst)-1):
if lst[i] == 0:
cur_carry = carry
else:
cur_carry -= req[lst[i]-1]
if cur_carry < 0:
return False
return True
#最小值适应度函数
def get_Mincost(pop):
pop_ture = []
for i in pop:
if Ture(i):
pop_ture.append(i)
fitness = []
for i in pop_ture:
fitness.append(Cost(i))
# print("最优配送路线为:",pop_ture[fitness.index(min(fitness))])
# print("花费成本为:",min(fitness))
a = max(fitness)
for i in range(len(fitness)):
fitness[i] = a - fitness[i] + 1
p = []
for i in fitness:
p.append(i / sum(fitness))
return (pop_ture,p,fitness)
#自然选择函数(轮盘赌),选取适应值最高的前百分之五十的解
def select(p,pop):
idx = np.random.choice(np.arange(len(p)),size=len(p)//2,replace=False,p = p)
new_pop = []
for i in idx:
new_pop.append(pop[i])
return new_pop
#变异函数:
def mutation(child):
if np.random.rand() < MUTATION_RATE: #以MUTATION_RATE的概率进行变异
mutate_point = np.random.randint(low=1,high=len(pop[0])-1) #随机产生一个实数,代表要变异基因的位置
child[mutate_point] = np.random.randint(low=1,high=len(req)-1) #变异后的值为随机一个站点
#交叉函数:
def crossover_and_mutation(pop):
new_pop = []
for father in pop: #遍历种群中的每一个个体,将该个体作为父亲
child = father #孩子先得到父亲的全部基因
if np.random.rand() < CROSSOVER_RATE: #交叉不是必然发生的,而是以一定的概率发生
mother = pop[np.random.randint(len(pop))] #在种群中选择另一个个体,并将该个体作为母亲
cross_point = np.random.randint(low=1,high=len(pop[0])-1) #随机生成交叉点(交叉点不为第一个和最后一个否则交叉无意义)
#step1:合法交叉
if child[cross_point-1] == 0 and child[cross_point+1]==0: #若交叉点前后两个元素都为0
child[cross_point] = mother[cross_point]
cross_point_right = cross_point #直接交叉
else:
while child[cross_point-1] != 0: #直到交叉点左端为0
cross_point -= 1 #交叉点左移
cross_point_right = cross_point+1 #交叉部分右端点
while child[cross_point_right+1] != 0: #直到交叉部分右端也为0
cross_point_right += 1 #交叉部分右端点右移直到交叉部分两端皆为0
child[cross_point:cross_point_right+1] = mother[cross_point:cross_point_right+1] #交叉
mutation(child)
#step2:去重
hash = {} #统计各站点出现次数
for i,x in enumerate(child):
if x != 0:
if x not in hash:
hash[x] = 1
else:
hash[x] += 1
if hash[x] > 1:
if i < cross_point or i > cross_point_right: #去掉交叉部分之外的重复点
child[i] = 0
#step3:补余
lst = [] #存放没有遍历到的站点索引
for i in range(1,len(req)+1): #总共有len(req)个站点
if i not in child:
lst.append(i)
for i,x in enumerate(child): #补齐缺失的站点
if (i < cross_point or i > cross_point_right) and i != 0 and i != len(child)-1 and x == 0 : #在交叉部分之外进行补齐
if (child[i-1] == 0 or child[i+1] == 0) and len(lst) > 0: #尽可能让站点分散插入
child[i] = lst[0]
lst.remove(lst[0])
if len(lst) > 0: #若无剩余优质空间可以插入,则择近补齐
for i, x in enumerate(child): # 补齐缺失的站点
if (i < cross_point or i > cross_point_right) and i != 0 and i != len(child) - 1 and x == 0:
if len(lst) > 0:
child[i] = lst[0]
lst.remove(lst[0])
if Ture(child): #检查子代是否合法
new_pop.append(child)
return new_pop
# print( crossover_and_mutation( select(get_Mincost(ans)[1],get_Mincost(ans)[0] ) ) )
# #print(len(select(get_Mincost(ans)[1],get_Mincost(ans)[0] )))
def print_info(pop):
cost = get_Mincost(pop)[2]
min_cost_index = np.argmax(cost)
print("最低成本为:",Cost(get_Mincost(pop)[0][min_cost_index]))
print("最优的基因型为:",get_Mincost(pop)[0][min_cost_index])
#迭代
N = 100 #迭代N次
fitness = []
jiyin = []
for _ in range(N):
# 生成随机解
ans = []
start_m = 200 # 初始种群个数
local = [] # 送货地点编号
for i in range(n - 1):
local.append(i + 1)
ans = [] # 初始种群
for _ in range(start_m):
res = [0] # 随机解res
c = n - 1 # 除配送中心外的点个数
local = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
while c > 0:
a = random.randint(1, c)
res.append(local[a - 1])
local.remove(local[a - 1])
c -= 1
if res not in ans:
res.append(0)
x = 0
while x < k:
len_res = len(res)
b = random.randint(1, len_res - 2)
if res[b] != 0 and res[b - 1] != 0:
res.insert(b, 0)
x += 1
ans.append(res)
pop = select(get_Mincost(ans)[1],get_Mincost(ans)[0])
new_pop = crossover_and_mutation(select(get_Mincost(ans)[1],get_Mincost(ans)[0]))
for i in new_pop:
pop.append(i)
jiyin.append(get_Mincost(pop)[0][np.argmin(get_Mincost(pop)[2])])
print(print_info(jiyin))到了这里,关于路径规划问题的遗传算法实现(python代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
](https://imgs.yssmx.com/Uploads/2024/04/861235-1.png)